
Imtiaz Sajwani commited on
Commit ·
928e689
1
Parent(s): 502ee16
add examples.
Browse files- README.md +12 -0
- examples/code.png +0 -0
- examples/summarization.png +0 -0
- examples/trip.png +0 -0
README.md
CHANGED
|
@@ -65,6 +65,18 @@ python run_generation.py \
|
|
| 65 |
--ipex
|
| 66 |
```
|
| 67 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 68 |
## Organizations developing the model
|
| 69 |
|
| 70 |
The NeuralChat team with members from Intel/SATG/AIA/AIPT. Core team members: Kaokao Lv, Liang Lv, Chang Wang, Wenxin Zhang, Xuhui Ren, and Haihao Shen.
|
|
|
|
| 65 |
--ipex
|
| 66 |
```
|
| 67 |
|
| 68 |
+
### Examples
|
| 69 |
+
|
| 70 |
+
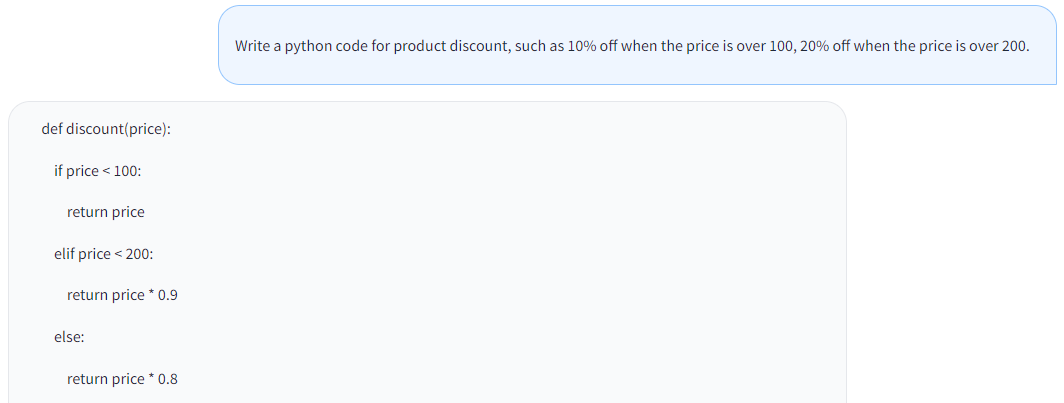
- code generation
|
| 71 |
+

|
| 72 |
+
|
| 73 |
+
- summarization
|
| 74 |
+

|
| 75 |
+
|
| 76 |
+
- trip
|
| 77 |
+

|
| 78 |
+
|
| 79 |
+
|
| 80 |
## Organizations developing the model
|
| 81 |
|
| 82 |
The NeuralChat team with members from Intel/SATG/AIA/AIPT. Core team members: Kaokao Lv, Liang Lv, Chang Wang, Wenxin Zhang, Xuhui Ren, and Haihao Shen.
|
examples/code.png
ADDED
|
examples/summarization.png
ADDED

|
examples/trip.png
ADDED

|