# بکارگیری مدلهای از پیش تعلیم دیده
{#if fw === 'pt'}
{:else}
{/if}
هاب مدلها، انتخاب مدل مناسب را ساده میکند؛ به طوری که میتوان با چند خط کد، آن را در هر کتابخانه پاییندستی وابسته استفاده نمود. بیایید نگاهی به نحوه عملی بکارگیری یکی از این مدلها انداخته و ببینیم چگونه میتوانیم در جامعه کاربران مشارکت داشته باشیم.
فرض کنید به دنبال مدلی مبتنی بر زبان فرانسوی هستیم که قادر به پر کردن جاهای خالی متن است.
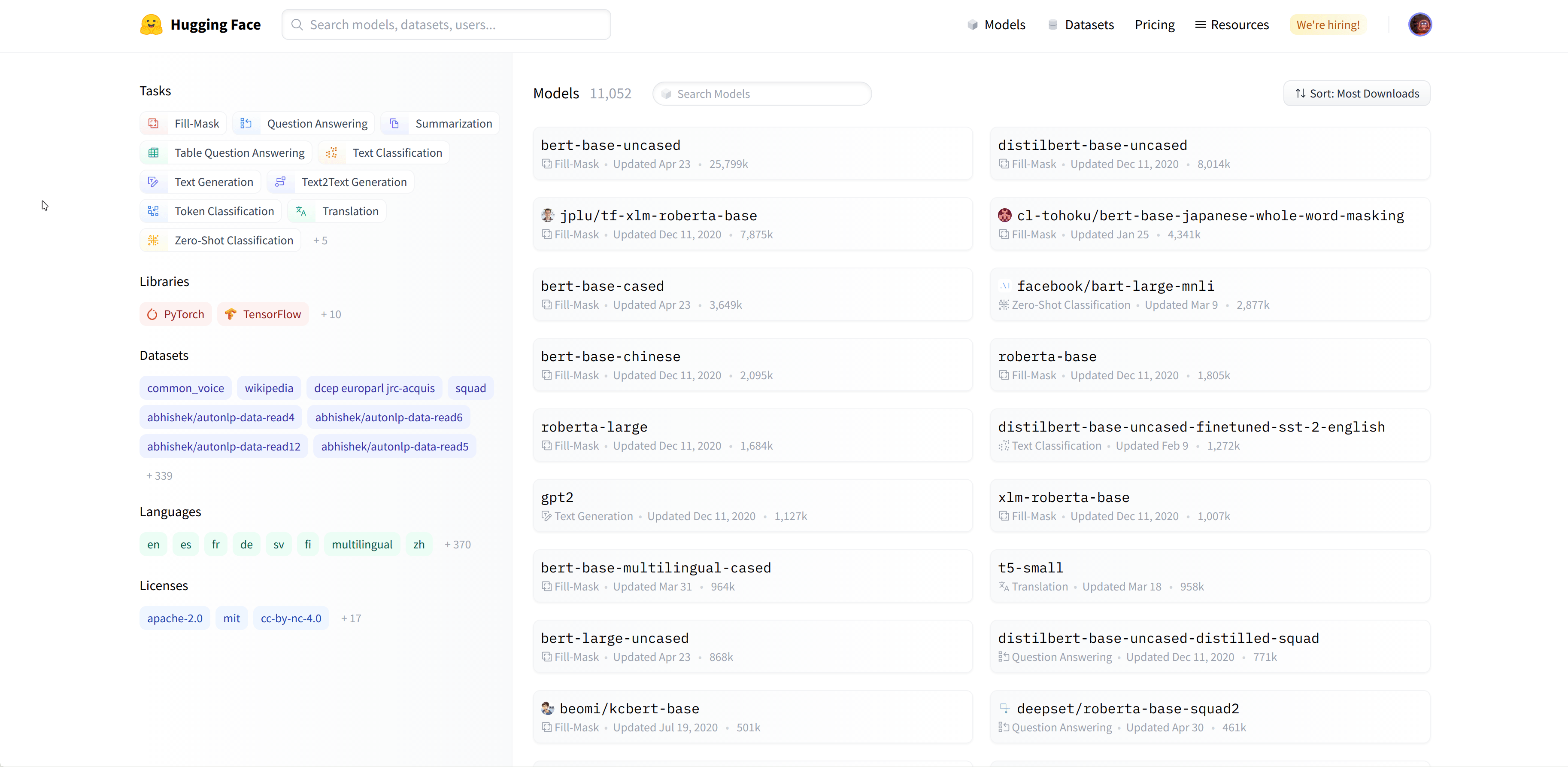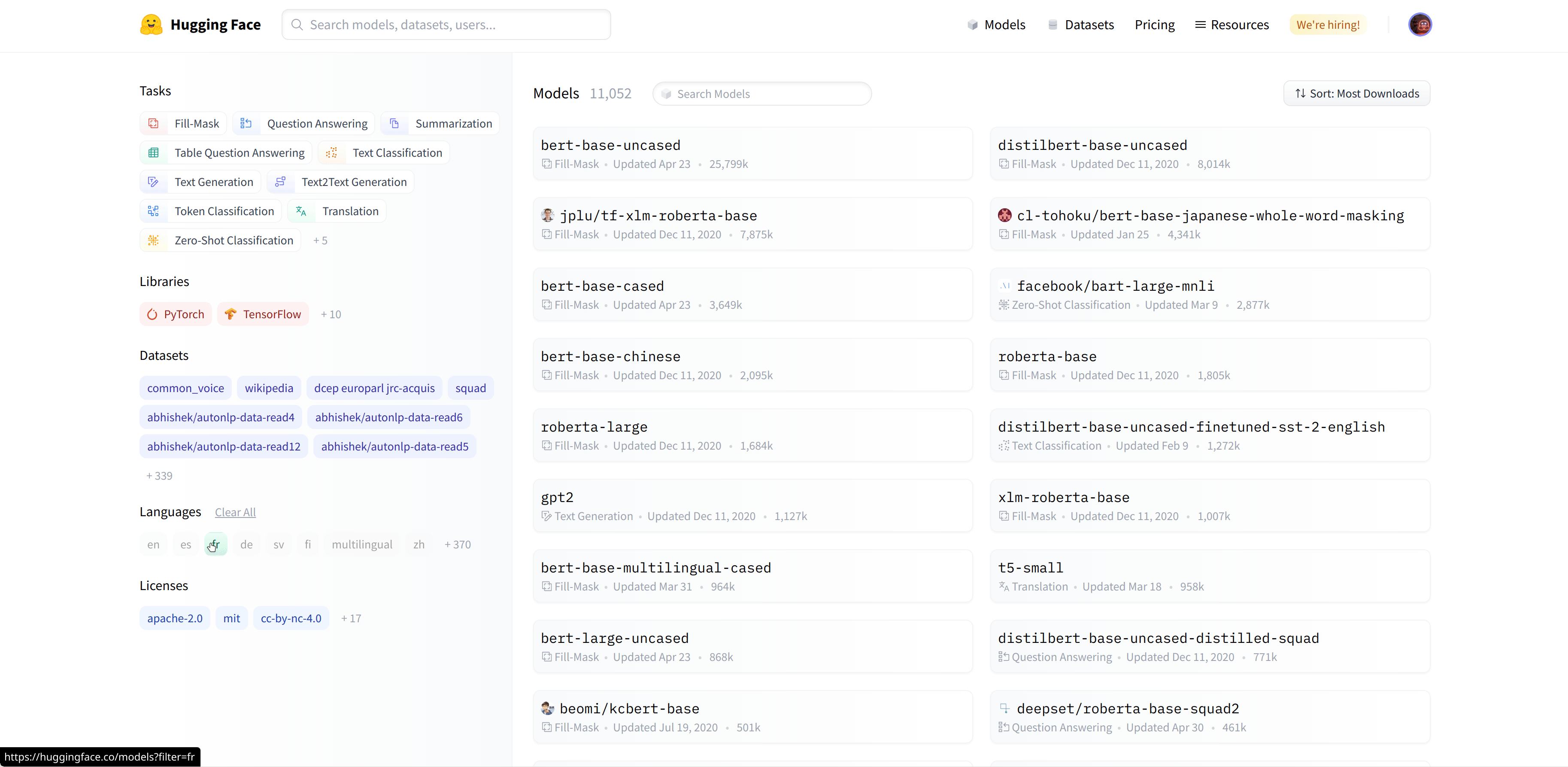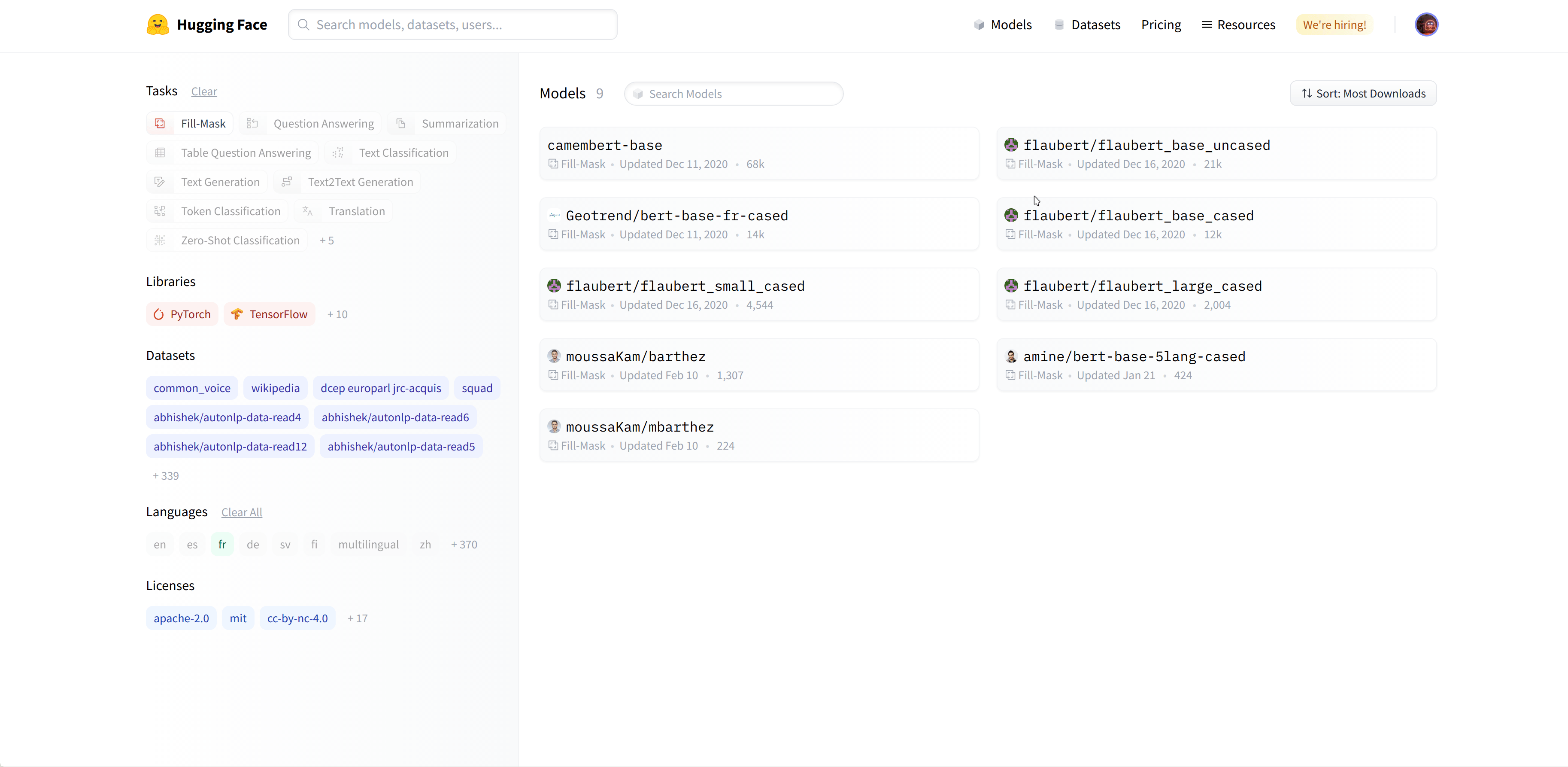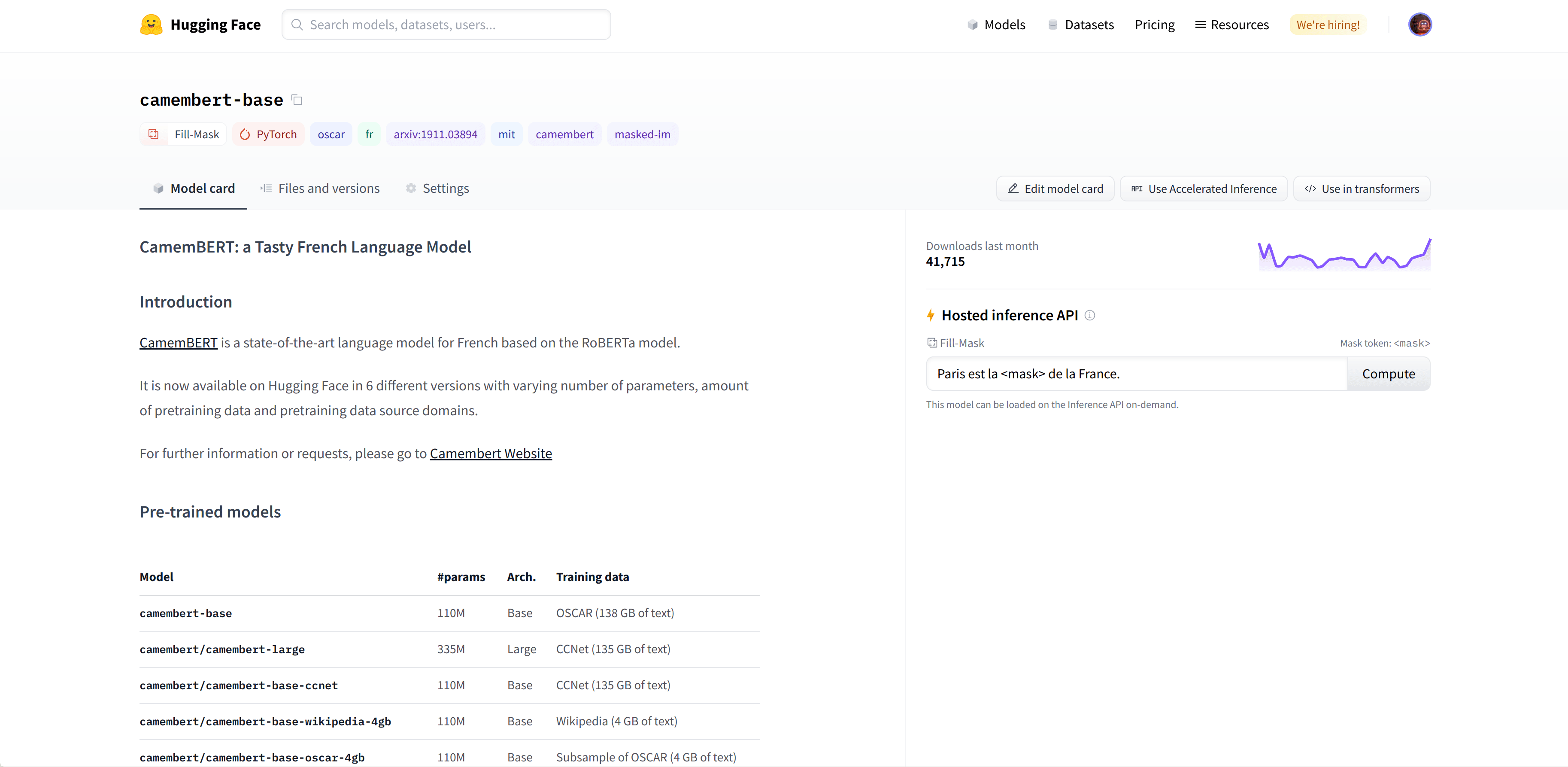
نقطه تعلیم `camembert-base` را انتخاب میکنیم تا مدل را با آن آزمایش نماییم. برای شروع استفاده از آن، تمام آنچه نیاز داریم شناسه `camembert-base` است! همان گونه که در فصلهای پیشین دیدید، میتوانیم با استفاده از تابع `pipeline()` نمونهای از آن بسازیم:
```py
from transformers import pipeline
camembert_fill_mask = pipeline("fill-mask", model="camembert-base")
results = camembert_fill_mask("Le camembert est :)")
```
```python out
[
{'sequence': 'Le camembert est délicieux :)', 'score': 0.49091005325317383, 'token': 7200, 'token_str': 'délicieux'},
{'sequence': 'Le camembert est excellent :)', 'score': 0.1055697426199913, 'token': 2183, 'token_str': 'excellent'},
{'sequence': 'Le camembert est succulent :)', 'score': 0.03453313186764717, 'token': 26202, 'token_str': 'succulent'},
{'sequence': 'Le camembert est meilleur :)', 'score': 0.0330314114689827, 'token': 528, 'token_str': 'meilleur'},
{'sequence': 'Le camembert est parfait :)', 'score': 0.03007650189101696, 'token': 1654, 'token_str': 'parfait'}
]
```
همان طور که میبینید، بارگذاری مدل در داخل خط تولید بسیار ساده است. تنها چیزی که باید مراقبش باشید این است که نقطه تعلیم انتخاب شده، مناسب مسئلهای باشد که برای حل آن به کار گرفته خواهد شد. برای مثال، در اینجا نقطه تعلیم `camembert-base` را در خط تولید `fill-mask` استفاده میکنیم، که انتخابی کاملا معقول است. اما اگر ما این نقطه تعلیم را در خط تولید `text-classification` به کار بگیریم، نتایج هیچ معنایی نخواهند داشت؛ زیرا سَر مربوط به `camembert-base` برای این نوع مسئله مناسب نیست. توصیه میکنیم برای گزینش نقاط تعلیم مناسب، از قسمت انتخاب مسئله در رابط کاربری هاب هاگینگفِیس استفاده نمایید:
همچنین میتوانید ایجاد نمونه از نقطه تعلیم مد نظر را مستقیما با استفاده از معماری مدل انجام دهید:
{#if fw === 'pt'}
```py
from transformers import CamembertTokenizer, CamembertForMaskedLM
tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
model = CamembertForMaskedLM.from_pretrained("camembert-base")
```
با این حال توصیه میکنیم به جای این کار، از کلاسهایی استفاده کنید که نام آنها با [`Auto*`](https://huggingface.co/transformers/model_doc/auto.html?highlight=auto#auto-classes) شروع میشود؛ چرا که طراحی این کلاسهای خودکار به گونهایست که فارغ از هرگونه وابستگی به معماری به کار رفته هستند. در حالی که نمونه کد قبلی، کاربران را محدود به نقاط تعلیم قابل بارگذاری در معماری CamemBERT میکند، استفاده از کلاسهای `Auto*`، تعویض نقاط تعلیم را سادهتر مینماید:
```py
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("camembert-base")
model = AutoModelForMaskedLM.from_pretrained("camembert-base")
```
{:else}
```py
from transformers import CamembertTokenizer, TFCamembertForMaskedLM
tokenizer = CamembertTokenizer.from_pretrained("camembert-base")
model = TFCamembertForMaskedLM.from_pretrained("camembert-base")
```
با این حال توصیه میکنیم به جای این کار، از کلاسهایی استفاده کنید که نام آنها با [`TFAuto*`](https://huggingface.co/transformers/model_doc/auto.html?highlight=auto#auto-classes) شروع میشود؛ چرا که طراحی این کلاسهای خودکار به گونهایست که فارغ از هرگونه وابستگی به معماری به کار رفته هستند. در حالی که نمونه کد قبلی، کاربران را محدود به نقاط تعلیم قابل بارگذاری در معماری CamemBERT میکند، استفاده از کلاسهای `TFAuto*`، تعویض نقاط تعلیم را سادهتر مینماید:
```py
from transformers import AutoTokenizer, TFAutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("camembert-base")
model = TFAutoModelForMaskedLM.from_pretrained("camembert-base")
```
{/if}
> [!TIP]
> هنگامی که مدلی از پیش تعلیم دیده را استفاده میکنید، حتما بررسی کنید که این تعلیم چگونه و روی چه دیتاسِتهایی صورت پذیرفته و چه محدودیتها و سوگیریهایی را شامل میشود. تمامی این اطلاعات میبایست در صفحه توضیحات مدل نشان داده شوند.