

Commit
·
e8a0e72
verified
·
0
Parent(s):
Duplicate from RekaAI/reka-flash-3
Browse filesCo-authored-by: Che Zheng <[email protected]>
- .gitattributes +36 -0
- README.md +77 -0
- added_tokens.json +3 -0
- aime.png +0 -0
- config.json +1 -0
- eval.png +3 -0
- generation_config.json +10 -0
- merges.txt +0 -0
- model-00001-of-00005.safetensors +3 -0
- model-00002-of-00005.safetensors +3 -0
- model-00003-of-00005.safetensors +3 -0
- model-00004-of-00005.safetensors +3 -0
- model-00005-of-00005.safetensors +3 -0
- model.safetensors.index.json +406 -0
- special_tokens_map.json +28 -0
- tokenizer.json +0 -0
- tokenizer_config.json +203 -0
- vocab.json +0 -0
.gitattributes
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
eval.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
---
|
| 4 |
+
# Reka Flash 3
|
| 5 |
+
|
| 6 |
+
Reka Flash 3 is a 21B general-purpose reasoning model that was trained from scratch. It was trained in synthetic and public datasets for supervised finetuning, followed by RLOO with model-based and rule-based rewards. It performs competitively with proprietary models such as OpenAI o1-mini, making it a good foundation to build applications that require low latency or on-device deployment. It is currently the best open model in its size category.
|
| 7 |
+
|
| 8 |
+
Try it out at [Reka Space](https://space.reka.ai).
|
| 9 |
+
|
| 10 |
+
Reka Flash 3 powers Nexus, our new platform for organizations to create and manage AI workers. Nexus workers have native deep research capabilities and can browse the web, execute code, and analyse internal files including documents, images, videos and audio. Learn more about Nexus at [getnexus.reka.ai](https://getnexus.reka.ai).
|
| 11 |
+
|
| 12 |
+

|
| 13 |
+
|
| 14 |
+
## Quickstart
|
| 15 |
+
|
| 16 |
+
For ease of deployment, the model is released in a Llama-compatible format. You may use any library compatible with Llama to run the model.
|
| 17 |
+
|
| 18 |
+
### Via Hugging Face
|
| 19 |
+
|
| 20 |
+
```python
|
| 21 |
+
import transformers
|
| 22 |
+
|
| 23 |
+
tokenizer = transformers.AutoTokenizer.from_pretrained("RekaAI/reka-flash-3")
|
| 24 |
+
model = transformers.AutoModelForCausalLM.from_pretrained("RekaAI/reka-flash-3", torch_dtype='auto', device_map='auto')
|
| 25 |
+
|
| 26 |
+
prompt = {"role": "user", "content": "Write a poem about large language model."}
|
| 27 |
+
text = tokenizer.apply_chat_template([prompt], tokenize=False, add_generation_prompt=True)
|
| 28 |
+
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
|
| 29 |
+
outputs = model.generate(**model_inputs, max_new_tokens=512)
|
| 30 |
+
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
### Via vLLM
|
| 34 |
+
|
| 35 |
+
```bash
|
| 36 |
+
docker run --rm -it --network=host --gpus '"device=0"' -v --shm-size=10.24gb vllm/vllm-openai:latest serve RekaAI/reka-flash-3 --dtype auto -tp 1
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
## Model Details
|
| 40 |
+
|
| 41 |
+
### Prompt Format
|
| 42 |
+
|
| 43 |
+
Reka Flash 3 uses cl100k_base tokenizer and adds no additional special tokens. Its prompt format is as follows:
|
| 44 |
+
|
| 45 |
+
```
|
| 46 |
+
human: this is round 1 prompt <sep> assistant: this is round 1 response <sep> ...
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
Generation should stop on seeing the string `<sep>` or seeing the special token `<|endoftext|>`.
|
| 50 |
+
|
| 51 |
+
System prompt can be added by prepending to the first user round.
|
| 52 |
+
|
| 53 |
+
```
|
| 54 |
+
human: You are a friendly assistant blah ... this is round 1 user prompt <sep> assistant: this is round 1 response <sep> ...
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
For multi-round conversations, it is recommended to drop the reasoning traces in the previous assistant round to save tokens for the model to think.
|
| 58 |
+
|
| 59 |
+
If you are using HF or vLLM, the built-in chat_template shall handle prompt formatting automatically.
|
| 60 |
+
|
| 61 |
+
### Budget Forcing
|
| 62 |
+
|
| 63 |
+
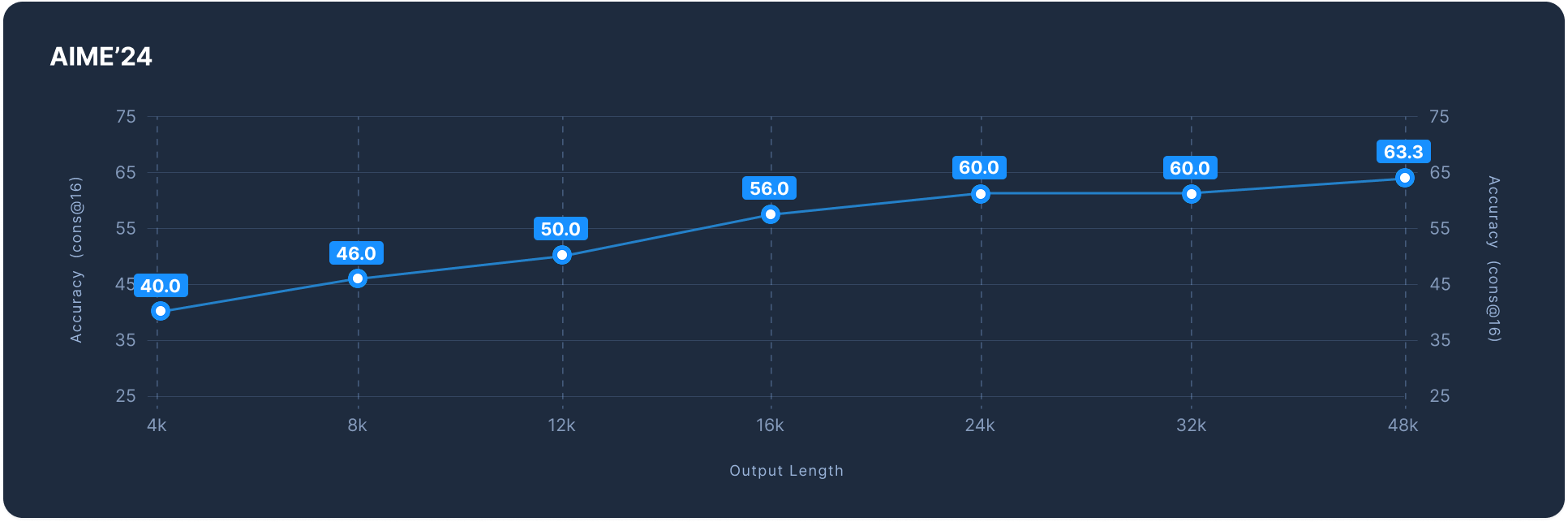
Reka Flash thinks before it produces an output. We use <reasoning> </reasoning> tags to indicate the beginning and the end of its thinking process. For some problems, the model might think for a long time. You can make the model to stop its thinking process by forcing it to output </reasoning> after a certain number of steps. We observe such a budget forcing mechanism will still produce a reasonable output. We show performance on AIME-2024 (cons@16) for various budgets below.
|
| 64 |
+
|
| 65 |
+

|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
### Language Support
|
| 69 |
+
|
| 70 |
+
This model is primarily built for the English language, and you should consider this an English only model. However, the model is able to converse and understand other languages to some degree.
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
### Relase Notes
|
| 74 |
+
|
| 75 |
+
- As a smaller model, it is not the best model for knowledge-intensive tasks. We recommend coupling Reka Flash 3 with web search for knowledge-related tasks.
|
| 76 |
+
- The model often thinks in English when prompted questions in non-English languages. We observe that this sometimes affects the output quality in non-English languages.
|
| 77 |
+
- The model has not undergone extensive alignment or persona training.
|
added_tokens.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<|endofprompt|>": 100276
|
| 3 |
+
}
|
aime.png
ADDED
|
config.json
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
{"architectures": ["LlamaForCausalLM"], "attention_bias": false, "attention_dropout": 0.0, "bos_token_id": 100257, "eos_token_id": 100257, "hidden_act": "silu", "hidden_size": 6144, "initializer_range": 0.006, "intermediate_size": 19648, "max_position_embeddings": 32768, "model_type": "llama", "num_attention_heads": 64, "num_hidden_layers": 44, "num_key_value_heads": 8, "pretraining_tp": 1, "rms_norm_eps": 1e-05, "rope_scaling": null, "rope_theta": 8000000, "tie_word_embeddings": false, "torch_dtype": "bfloat16", "use_cache": true, "vocab_size": 100352}
|
eval.png
ADDED
|
Git LFS Details
|
generation_config.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 100257,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": 100257,
|
| 5 |
+
"pad_token_id": 100257,
|
| 6 |
+
"temperature": 0.6,
|
| 7 |
+
"top_k": 1024,
|
| 8 |
+
"top_p": 0.95
|
| 9 |
+
}
|
| 10 |
+
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:332dc205fc170943365bc371c72bae438bae1c0c1fc77b168591b335ed1e64dc
|
| 3 |
+
size 9789748352
|
model-00002-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3977f7ac371555d7f7d5f5cb73d77dffae1fd91cf81627e7aae423ca4a5c8e08
|
| 3 |
+
size 9836186896
|
model-00003-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:31e8b5b46749a07387137f2d1934c2812976b89d4f1ca427706d8c58b558bc21
|
| 3 |
+
size 9836186920
|
model-00004-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bc578dd3aef0dc7c05a6ae1e1502a8de6e582f0097a6c54a3fd577df231c0445
|
| 3 |
+
size 9836186920
|
model-00005-of-00005.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e6aaffe60b34da953502c13f9b47694db245ff00171aab0dcef4df4d6df76497
|
| 3 |
+
size 2512701864
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,406 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 41810964480
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"model.embed_tokens.weight": "model-00001-of-00005.safetensors",
|
| 7 |
+
"lm_head.weight": "model-00001-of-00005.safetensors",
|
| 8 |
+
"model.norm.weight": "model-00001-of-00005.safetensors",
|
| 9 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 10 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 11 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 12 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 13 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 14 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 15 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 16 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 17 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 18 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 19 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 20 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 21 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 22 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 23 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 24 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 25 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 26 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 27 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 28 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 29 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 30 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 31 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 32 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 33 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 34 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 35 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 36 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 37 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 38 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 39 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 40 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 41 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 42 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 43 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 44 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 45 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 46 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 47 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 48 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 49 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 50 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 51 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 52 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 53 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 54 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 55 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 56 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 57 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 58 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 59 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 60 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 61 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 62 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 63 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 64 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 65 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 66 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 67 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 68 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 69 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 70 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 71 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 72 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 73 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 74 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 75 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 76 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 77 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 78 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00005.safetensors",
|
| 79 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00005.safetensors",
|
| 80 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00005.safetensors",
|
| 81 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00005.safetensors",
|
| 82 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00005.safetensors",
|
| 83 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00005.safetensors",
|
| 84 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00005.safetensors",
|
| 85 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 86 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00005.safetensors",
|
| 87 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 88 |
+
"model.layers.8.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 89 |
+
"model.layers.8.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 90 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 91 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 92 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 93 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 94 |
+
"model.layers.9.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 95 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 96 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 97 |
+
"model.layers.9.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 98 |
+
"model.layers.9.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 99 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 100 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 101 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 102 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 103 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 104 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 105 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 106 |
+
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 107 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 108 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 109 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 110 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 111 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 112 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 113 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 114 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 115 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 116 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 117 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 118 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 119 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 120 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 121 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 122 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 123 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 124 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 125 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 126 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 127 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 128 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 129 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 130 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 131 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 132 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 133 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 134 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 135 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 136 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 137 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 138 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 139 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 140 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 141 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 142 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 143 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 144 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 145 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 146 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 147 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 148 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 149 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 150 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 151 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 152 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 153 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 154 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 155 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 156 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 157 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 158 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 159 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 160 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 161 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 162 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 163 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 164 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 165 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 166 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 167 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 168 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 169 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 170 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 171 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 172 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 173 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 174 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 175 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 176 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 177 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00005.safetensors",
|
| 178 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00005.safetensors",
|
| 179 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00005.safetensors",
|
| 180 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00005.safetensors",
|
| 181 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00005.safetensors",
|
| 182 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00005.safetensors",
|
| 183 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00005.safetensors",
|
| 184 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 185 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00005.safetensors",
|
| 186 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 187 |
+
"model.layers.19.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 188 |
+
"model.layers.19.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 189 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 190 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 191 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 192 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 193 |
+
"model.layers.20.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 194 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 195 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 196 |
+
"model.layers.20.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 197 |
+
"model.layers.20.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 198 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 199 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 200 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 201 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 202 |
+
"model.layers.21.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 203 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 204 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 205 |
+
"model.layers.21.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 206 |
+
"model.layers.21.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 207 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 208 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 209 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 210 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 211 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 212 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 213 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 214 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 215 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 216 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 217 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 218 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 219 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 220 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 221 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 222 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 223 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 224 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 225 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 226 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 227 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 228 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 229 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 230 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 231 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 232 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 233 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 234 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 235 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 236 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 237 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 238 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 239 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 240 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 241 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 242 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 243 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 244 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 245 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 246 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 247 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 248 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 249 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 250 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 251 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 252 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 253 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 254 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 255 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 256 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 257 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 258 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 259 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 260 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 261 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 262 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 263 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 264 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 265 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 266 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 267 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 268 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 269 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 270 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 271 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 272 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 273 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 274 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 275 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 276 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00005.safetensors",
|
| 277 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00005.safetensors",
|
| 278 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00005.safetensors",
|
| 279 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00005.safetensors",
|
| 280 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00005.safetensors",
|
| 281 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00005.safetensors",
|
| 282 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00005.safetensors",
|
| 283 |
+
"model.layers.30.input_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 284 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00005.safetensors",
|
| 285 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 286 |
+
"model.layers.30.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 287 |
+
"model.layers.30.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 288 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 289 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 290 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 291 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 292 |
+
"model.layers.31.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 293 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 294 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 295 |
+
"model.layers.31.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 296 |
+
"model.layers.31.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 297 |
+
"model.layers.32.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 298 |
+
"model.layers.32.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 299 |
+
"model.layers.32.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 300 |
+
"model.layers.32.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 301 |
+
"model.layers.32.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 302 |
+
"model.layers.32.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 303 |
+
"model.layers.32.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 304 |
+
"model.layers.32.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 305 |
+
"model.layers.32.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 306 |
+
"model.layers.33.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 307 |
+
"model.layers.33.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 308 |
+
"model.layers.33.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 309 |
+
"model.layers.33.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 310 |
+
"model.layers.33.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 311 |
+
"model.layers.33.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 312 |
+
"model.layers.33.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 313 |
+
"model.layers.33.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 314 |
+
"model.layers.33.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 315 |
+
"model.layers.34.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 316 |
+
"model.layers.34.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 317 |
+
"model.layers.34.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 318 |
+
"model.layers.34.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 319 |
+
"model.layers.34.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 320 |
+
"model.layers.34.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 321 |
+
"model.layers.34.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 322 |
+
"model.layers.34.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 323 |
+
"model.layers.34.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 324 |
+
"model.layers.35.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 325 |
+
"model.layers.35.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 326 |
+
"model.layers.35.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 327 |
+
"model.layers.35.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 328 |
+
"model.layers.35.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 329 |
+
"model.layers.35.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 330 |
+
"model.layers.35.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 331 |
+
"model.layers.35.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 332 |
+
"model.layers.35.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 333 |
+
"model.layers.36.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 334 |
+
"model.layers.36.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 335 |
+
"model.layers.36.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 336 |
+
"model.layers.36.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 337 |
+
"model.layers.36.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 338 |
+
"model.layers.36.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 339 |
+
"model.layers.36.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 340 |
+
"model.layers.36.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 341 |
+
"model.layers.36.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 342 |
+
"model.layers.37.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 343 |
+
"model.layers.37.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 344 |
+
"model.layers.37.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 345 |
+
"model.layers.37.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 346 |
+
"model.layers.37.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 347 |
+
"model.layers.37.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 348 |
+
"model.layers.37.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 349 |
+
"model.layers.37.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 350 |
+
"model.layers.37.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 351 |
+
"model.layers.38.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 352 |
+
"model.layers.38.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 353 |
+
"model.layers.38.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 354 |
+
"model.layers.38.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 355 |
+
"model.layers.38.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 356 |
+
"model.layers.38.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 357 |
+
"model.layers.38.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 358 |
+
"model.layers.38.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 359 |
+
"model.layers.38.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 360 |
+
"model.layers.39.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 361 |
+
"model.layers.39.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 362 |
+
"model.layers.39.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 363 |
+
"model.layers.39.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 364 |
+
"model.layers.39.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 365 |
+
"model.layers.39.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 366 |
+
"model.layers.39.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 367 |
+
"model.layers.39.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 368 |
+
"model.layers.39.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 369 |
+
"model.layers.40.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 370 |
+
"model.layers.40.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 371 |
+
"model.layers.40.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 372 |
+
"model.layers.40.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 373 |
+
"model.layers.40.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 374 |
+
"model.layers.40.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 375 |
+
"model.layers.40.mlp.gate_proj.weight": "model-00004-of-00005.safetensors",
|
| 376 |
+
"model.layers.40.mlp.up_proj.weight": "model-00004-of-00005.safetensors",
|
| 377 |
+
"model.layers.40.mlp.down_proj.weight": "model-00004-of-00005.safetensors",
|
| 378 |
+
"model.layers.41.self_attn.q_proj.weight": "model-00004-of-00005.safetensors",
|
| 379 |
+
"model.layers.41.self_attn.k_proj.weight": "model-00004-of-00005.safetensors",
|
| 380 |
+
"model.layers.41.self_attn.v_proj.weight": "model-00004-of-00005.safetensors",
|
| 381 |
+
"model.layers.41.self_attn.o_proj.weight": "model-00004-of-00005.safetensors",
|
| 382 |
+
"model.layers.41.input_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 383 |
+
"model.layers.41.post_attention_layernorm.weight": "model-00004-of-00005.safetensors",
|
| 384 |
+
"model.layers.41.mlp.gate_proj.weight": "model-00005-of-00005.safetensors",
|
| 385 |
+
"model.layers.41.mlp.up_proj.weight": "model-00005-of-00005.safetensors",
|
| 386 |
+
"model.layers.41.mlp.down_proj.weight": "model-00005-of-00005.safetensors",
|
| 387 |
+
"model.layers.42.self_attn.q_proj.weight": "model-00005-of-00005.safetensors",
|
| 388 |
+
"model.layers.42.self_attn.k_proj.weight": "model-00005-of-00005.safetensors",
|
| 389 |
+
"model.layers.42.self_attn.v_proj.weight": "model-00005-of-00005.safetensors",
|
| 390 |
+
"model.layers.42.self_attn.o_proj.weight": "model-00005-of-00005.safetensors",
|
| 391 |
+
"model.layers.42.input_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 392 |
+
"model.layers.42.post_attention_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 393 |
+
"model.layers.42.mlp.gate_proj.weight": "model-00005-of-00005.safetensors",
|
| 394 |
+
"model.layers.42.mlp.up_proj.weight": "model-00005-of-00005.safetensors",
|
| 395 |
+
"model.layers.42.mlp.down_proj.weight": "model-00005-of-00005.safetensors",
|
| 396 |
+
"model.layers.43.self_attn.q_proj.weight": "model-00005-of-00005.safetensors",
|
| 397 |
+
"model.layers.43.self_attn.k_proj.weight": "model-00005-of-00005.safetensors",
|
| 398 |
+
"model.layers.43.self_attn.v_proj.weight": "model-00005-of-00005.safetensors",
|
| 399 |
+
"model.layers.43.self_attn.o_proj.weight": "model-00005-of-00005.safetensors",
|
| 400 |
+
"model.layers.43.input_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 401 |
+
"model.layers.43.post_attention_layernorm.weight": "model-00005-of-00005.safetensors",
|
| 402 |
+
"model.layers.43.mlp.gate_proj.weight": "model-00005-of-00005.safetensors",
|
| 403 |
+
"model.layers.43.mlp.up_proj.weight": "model-00005-of-00005.safetensors",
|
| 404 |
+
"model.layers.43.mlp.down_proj.weight": "model-00005-of-00005.safetensors"
|
| 405 |
+
}
|
| 406 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|endoftext|>",
|
| 4 |
+
"<|fim_prefix|>",
|
| 5 |
+
"<|fim_middle|>",
|
| 6 |
+
"<|fim_suffix|>",
|
| 7 |
+
"<|endofprompt|>",
|
| 8 |
+
"<|_unuse_missing_100256|>",
|
| 9 |
+
"<|_unuse_missing_100261|>",
|
| 10 |
+
"<|_unuse_missing_100262|>",
|
| 11 |
+
"<|_unuse_missing_100263|>",
|
| 12 |
+
"<|_unuse_missing_100264|>",
|
| 13 |
+
"<|_unuse_missing_100265|>",
|
| 14 |
+
"<|_unuse_missing_100266|>",
|
| 15 |
+
"<|_unuse_missing_100267|>",
|
| 16 |
+
"<|_unuse_missing_100268|>",
|
| 17 |
+
"<|_unuse_missing_100269|>",
|
| 18 |
+
"<|_unuse_missing_100270|>",
|
| 19 |
+
"<|_unuse_missing_100271|>",
|
| 20 |
+
"<|_unuse_missing_100272|>",
|
| 21 |
+
"<|_unuse_missing_100273|>",
|
| 22 |
+
"<|_unuse_missing_100274|>",
|
| 23 |
+
"<|_unuse_missing_100275|>"
|
| 24 |
+
],
|
| 25 |
+
"bos_token": "<|endoftext|>",
|
| 26 |
+
"eos_token": "<|endoftext|>",
|
| 27 |
+
"unk_token": "<|endoftext|>"
|
| 28 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"100256": {
|
| 5 |
+
"content": "<|_unuse_missing_100256|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"100257": {
|
| 13 |
+
"content": "<|endoftext|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"100258": {
|
| 21 |
+
"content": "<|fim_prefix|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"100259": {
|
| 29 |
+
"content": "<|fim_middle|>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"100260": {
|
| 37 |
+
"content": "<|fim_suffix|>",
|
| 38 |
+
"lstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": false,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"100261": {
|
| 45 |
+
"content": "<|_unuse_missing_100261|>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"100262": {
|
| 53 |
+
"content": "<|_unuse_missing_100262|>",
|
| 54 |
+
"lstrip": false,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": false,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"100263": {
|
| 61 |
+
"content": "<|_unuse_missing_100263|>",
|
| 62 |
+
"lstrip": false,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": false,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"100264": {
|
| 69 |
+
"content": "<|_unuse_missing_100264|>",
|
| 70 |
+
"lstrip": false,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": false,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": true
|
| 75 |
+
},
|
| 76 |
+
"100265": {
|
| 77 |
+
"content": "<|_unuse_missing_100265|>",
|
| 78 |
+
"lstrip": false,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": false,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": true
|
| 83 |
+
},
|
| 84 |
+
"100266": {
|
| 85 |
+
"content": "<|_unuse_missing_100266|>",
|
| 86 |
+
"lstrip": false,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": false,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": true
|
| 91 |
+
},
|
| 92 |
+
"100267": {
|
| 93 |
+
"content": "<|_unuse_missing_100267|>",
|
| 94 |
+
"lstrip": false,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": false,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": true
|
| 99 |
+
},
|
| 100 |
+
"100268": {
|
| 101 |
+
"content": "<|_unuse_missing_100268|>",
|
| 102 |
+
"lstrip": false,
|
| 103 |
+
"normalized": false,
|
| 104 |
+
"rstrip": false,
|
| 105 |
+
"single_word": false,
|
| 106 |
+
"special": true
|
| 107 |
+
},
|
| 108 |
+
"100269": {
|
| 109 |
+
"content": "<|_unuse_missing_100269|>",
|
| 110 |
+
"lstrip": false,
|
| 111 |
+
"normalized": false,
|
| 112 |
+
"rstrip": false,
|
| 113 |
+
"single_word": false,
|
| 114 |
+
"special": true
|
| 115 |
+
},
|
| 116 |
+
"100270": {
|
| 117 |
+
"content": "<|_unuse_missing_100270|>",
|
| 118 |
+
"lstrip": false,
|
| 119 |
+
"normalized": false,
|
| 120 |
+
"rstrip": false,
|
| 121 |
+
"single_word": false,
|
| 122 |
+
"special": true
|
| 123 |
+
},
|
| 124 |
+
"100271": {
|
| 125 |
+
"content": "<|_unuse_missing_100271|>",
|
| 126 |
+
"lstrip": false,
|
| 127 |
+
"normalized": false,
|
| 128 |
+
"rstrip": false,
|
| 129 |
+
"single_word": false,
|
| 130 |
+
"special": true
|
| 131 |
+
},
|
| 132 |
+
"100272": {
|
| 133 |
+
"content": "<|_unuse_missing_100272|>",
|
| 134 |
+
"lstrip": false,
|
| 135 |
+
"normalized": false,
|
| 136 |
+
"rstrip": false,
|
| 137 |
+
"single_word": false,
|
| 138 |
+
"special": true
|
| 139 |
+
},
|
| 140 |
+
"100273": {
|
| 141 |
+
"content": "<|_unuse_missing_100273|>",
|
| 142 |
+
"lstrip": false,
|
| 143 |
+
"normalized": false,
|
| 144 |
+
"rstrip": false,
|
| 145 |
+
"single_word": false,
|
| 146 |
+
"special": true
|
| 147 |
+
},
|
| 148 |
+
"100274": {
|
| 149 |
+
"content": "<|_unuse_missing_100274|>",
|
| 150 |
+
"lstrip": false,
|
| 151 |
+
"normalized": false,
|
| 152 |
+
"rstrip": false,
|
| 153 |
+
"single_word": false,
|
| 154 |
+
"special": true
|
| 155 |
+
},
|
| 156 |
+
"100275": {
|
| 157 |
+
"content": "<|_unuse_missing_100275|>",
|
| 158 |
+
"lstrip": false,
|
| 159 |
+
"normalized": false,
|
| 160 |
+
"rstrip": false,
|
| 161 |
+
"single_word": false,
|
| 162 |
+
"special": true
|
| 163 |
+
},
|
| 164 |
+
"100276": {
|
| 165 |
+
"content": "<|endofprompt|>",
|
| 166 |
+
"lstrip": false,
|
| 167 |
+
"normalized": false,
|
| 168 |
+
"rstrip": false,
|
| 169 |
+
"single_word": false,
|
| 170 |
+
"special": true
|
| 171 |
+
}
|
| 172 |
+
},
|
| 173 |
+
"additional_special_tokens": [
|
| 174 |
+
"<|endoftext|>",
|
| 175 |
+
"<|fim_prefix|>",
|
| 176 |
+
"<|fim_middle|>",
|
| 177 |
+
"<|fim_suffix|>",
|
| 178 |
+
"<|endofprompt|>",
|
| 179 |
+
"<|_unuse_missing_100256|>",
|
| 180 |
+
"<|_unuse_missing_100261|>",
|
| 181 |
+
"<|_unuse_missing_100262|>",
|
| 182 |
+
"<|_unuse_missing_100263|>",
|
| 183 |
+
"<|_unuse_missing_100264|>",
|
| 184 |
+
"<|_unuse_missing_100265|>",
|
| 185 |
+
"<|_unuse_missing_100266|>",
|
| 186 |
+
"<|_unuse_missing_100267|>",
|
| 187 |
+
"<|_unuse_missing_100268|>",
|
| 188 |
+
"<|_unuse_missing_100269|>",
|
| 189 |
+
"<|_unuse_missing_100270|>",
|
| 190 |
+
"<|_unuse_missing_100271|>",
|
| 191 |
+
"<|_unuse_missing_100272|>",
|
| 192 |
+
"<|_unuse_missing_100273|>",
|
| 193 |
+
"<|_unuse_missing_100274|>",
|
| 194 |
+
"<|_unuse_missing_100275|>"
|
| 195 |
+
],
|
| 196 |
+
"bos_token": "<|endoftext|>",
|
| 197 |
+
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set merged_content = messages[0]['content'] + ' ' + messages[1]['content'] %}{% set merged_messages = [{'role': messages[1]['role'], 'content': merged_content}] + messages[2:] %}{% else %}{% set merged_messages = messages %}{% endif %}{% for message in merged_messages %}{{message['role'] + ': ' + (message['content'].split('<reasoning>')[0] + message['content'].split('</reasoning>')[1] if message['role'] == 'assistant' and '</reasoning>' in message['content'] else message['content'])}}{% if (loop.last and add_generation_prompt and merged_messages[-1]['role'] != 'assistant') or not loop.last %}{{ ' <sep> ' }}{% endif %}{% endfor %}{% if add_generation_prompt and merged_messages[-1]['role'] != 'assistant' %}{{ 'assistant:' }}{% endif %}",
|
| 198 |
+
"clean_up_tokenization_spaces": true,
|
| 199 |
+
"eos_token": "<|endoftext|>",
|
| 200 |
+
"model_max_length": 32768,
|
| 201 |
+
"tokenizer_class": "GPT2Tokenizer",
|
| 202 |
+
"unk_token": "<|endoftext|>"
|
| 203 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|