

Hello
Browse files- ComputeAgent/ComputeAgent.png +0 -0
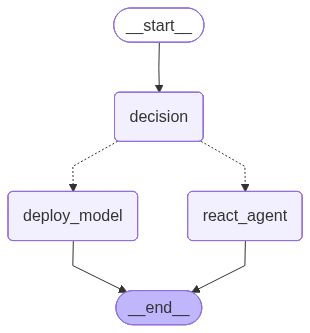
- ComputeAgent/basic_agent_graph.png +0 -0
- ComputeAgent/chains/tool_result_chain.py +240 -0
- ComputeAgent/compute_agent_graph.png +0 -0
- ComputeAgent/graph/__init__.py +0 -0
- ComputeAgent/graph/basic_agent_graph.png +0 -0
- ComputeAgent/graph/graph.py +411 -0
- ComputeAgent/graph/graph_ReAct.py +331 -0
- ComputeAgent/graph/graph_deploy.py +363 -0
- ComputeAgent/graph/state.py +84 -0
- ComputeAgent/hivenet.jpg +0 -0
- ComputeAgent/main.py +284 -0
- ComputeAgent/models/__init__.py +0 -0
- ComputeAgent/models/doc.py +55 -0
- ComputeAgent/models/model_manager.py +100 -0
- ComputeAgent/models/model_router.py +146 -0
- ComputeAgent/nodes/ReAct/__init__.py +58 -0
- ComputeAgent/nodes/ReAct/agent_reasoning_node.py +399 -0
- ComputeAgent/nodes/ReAct/auto_approval_node.py +81 -0
- ComputeAgent/nodes/ReAct/decision_functions.py +135 -0
- ComputeAgent/nodes/ReAct/generate_node.py +510 -0
- ComputeAgent/nodes/ReAct/human_approval_node.py +284 -0
- ComputeAgent/nodes/ReAct/tool_execution_node.py +190 -0
- ComputeAgent/nodes/ReAct/tool_rejection_exit_node.py +93 -0
- ComputeAgent/nodes/ReAct_DeployModel/__init__.py +13 -0
- ComputeAgent/nodes/ReAct_DeployModel/capacity_approval.py +183 -0
- ComputeAgent/nodes/ReAct_DeployModel/capacity_estimation.py +387 -0
- ComputeAgent/nodes/ReAct_DeployModel/extract_model_info.py +291 -0
- ComputeAgent/nodes/ReAct_DeployModel/generate_additional_info.py +83 -0
- ComputeAgent/nodes/__init__.py +0 -0
- ComputeAgent/routers/compute_agent_HITL.py +590 -0
- ComputeAgent/vllm_engine_args.py +325 -0
- Compute_MCP/api_data_structure.py +398 -0
- Compute_MCP/main.py +16 -0
- Compute_MCP/tools.py +96 -0
- Compute_MCP/utils.py +26 -0
- Dockerfile +29 -0
- Gradio_interface.py +1374 -0
- README.md +12 -4
- constant.py +195 -0
- logging_setup.py +73 -0
- requirements.txt +21 -0
- run.sh +21 -0
ComputeAgent/ComputeAgent.png
ADDED

|
ComputeAgent/basic_agent_graph.png
ADDED
|
ComputeAgent/chains/tool_result_chain.py
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Tool Result Chain Module for ReAct Workflow
|
| 3 |
+
|
| 4 |
+
This module implements the ToolResultChain class, which serves as a specialized
|
| 5 |
+
response generation component within the ReAct (Reasoning and Acting) workflow
|
| 6 |
+
for synthesizing responses from non-researcher tool execution results.
|
| 7 |
+
|
| 8 |
+
The ToolResultChain provides professional formatting and comprehensive response
|
| 9 |
+
generation for various tool outputs (math calculations, file operations, API calls,
|
| 10 |
+
etc.) while maintaining the same quality standards as ResearcherChain and DirectAnswerChain.
|
| 11 |
+
|
| 12 |
+
The ToolResultChain is used when the ReAct workflow has executed tools other than
|
| 13 |
+
the researcher tool and needs to create a well-formatted, contextual response
|
| 14 |
+
that integrates tool results with conversation memory and user intent.
|
| 15 |
+
|
| 16 |
+
Key Features:
|
| 17 |
+
- Tool result synthesis with professional formatting
|
| 18 |
+
- Memory context integration for personalized responses
|
| 19 |
+
- Comprehensive formatting consistent with other chains
|
| 20 |
+
- Support for multiple tool result types (JSON, text, structured data)
|
| 21 |
+
- Timezone-aware timestamp integration
|
| 22 |
+
- Professional markdown structure for consistency
|
| 23 |
+
- Integration with HiveGPT system prompts for unified behavior
|
| 24 |
+
|
| 25 |
+
Author: HiveNetCode
|
| 26 |
+
License: Private
|
| 27 |
+
"""
|
| 28 |
+
|
| 29 |
+
from datetime import datetime
|
| 30 |
+
from typing import Optional, List, Dict, Any
|
| 31 |
+
from zoneinfo import ZoneInfo
|
| 32 |
+
|
| 33 |
+
from langchain_core.prompts import ChatPromptTemplate
|
| 34 |
+
from langchain_core.output_parsers import StrOutputParser
|
| 35 |
+
from langchain_openai import ChatOpenAI
|
| 36 |
+
|
| 37 |
+
from constant import Constants
|
| 38 |
+
|
| 39 |
+
class ToolResultChain:
|
| 40 |
+
"""
|
| 41 |
+
Specialized chain optimized for tool result synthesis within ReAct workflow.
|
| 42 |
+
|
| 43 |
+
This class implements a tool result-based response generation system specifically
|
| 44 |
+
designed for the ReAct (Reasoning and Acting) workflow pattern. It provides responses
|
| 45 |
+
that synthesize and contextualize tool execution results into comprehensive,
|
| 46 |
+
user-friendly answers that maintain professional presentation standards.
|
| 47 |
+
|
| 48 |
+
The ToolResultChain handles various tool output types and ensures:
|
| 49 |
+
- Professional formatting consistent with other chains
|
| 50 |
+
- Integration of tool results with user context and intent
|
| 51 |
+
- Memory-aware response generation
|
| 52 |
+
- Comprehensive explanations that go beyond raw tool output
|
| 53 |
+
|
| 54 |
+
This chain is typically used when the ReAct workflow has executed tools like:
|
| 55 |
+
- Mathematical calculations
|
| 56 |
+
- File operations
|
| 57 |
+
- API calls
|
| 58 |
+
- Data processing tools
|
| 59 |
+
- System utilities
|
| 60 |
+
And needs to present the results in a user-friendly, contextual manner.
|
| 61 |
+
"""
|
| 62 |
+
|
| 63 |
+
def __init__(self, llm: ChatOpenAI):
|
| 64 |
+
"""
|
| 65 |
+
Initialize the ToolResultChain with language model and prompt configuration.
|
| 66 |
+
|
| 67 |
+
Args:
|
| 68 |
+
llm: ChatOpenAI instance configured for response generation.
|
| 69 |
+
Should be the same model type used in other chains for consistency.
|
| 70 |
+
"""
|
| 71 |
+
self.llm = llm
|
| 72 |
+
|
| 73 |
+
# Build the system prompt for tool result synthesis
|
| 74 |
+
tool_result_system_prompt = self._build_tool_result_system_prompt()
|
| 75 |
+
|
| 76 |
+
# Create the prompt template for tool result responses
|
| 77 |
+
self.prompt = ChatPromptTemplate.from_messages([
|
| 78 |
+
("system", tool_result_system_prompt),
|
| 79 |
+
("human", self._get_human_message_template())
|
| 80 |
+
])
|
| 81 |
+
|
| 82 |
+
# Build the complete processing chain
|
| 83 |
+
self.chain = self.prompt | self.llm | StrOutputParser()
|
| 84 |
+
|
| 85 |
+
def _build_tool_result_system_prompt(self) -> str:
|
| 86 |
+
"""
|
| 87 |
+
Construct the complete system prompt for tool result synthesis.
|
| 88 |
+
|
| 89 |
+
Returns:
|
| 90 |
+
Complete system prompt combining HiveGPT base behavior with tool result instructions
|
| 91 |
+
"""
|
| 92 |
+
return Constants.GENERAL_SYSTEM_PROMPT + r"""
|
| 93 |
+
|
| 94 |
+
## TOOL RESULT SYNTHESIS INSTRUCTIONS
|
| 95 |
+
**YOU ARE SYNTHESIZING AND PRESENTING TOOL EXECUTION RESULTS.**
|
| 96 |
+
- **ANALYZE** the provided tool results and understand what was accomplished.
|
| 97 |
+
- **CONTEXTUALIZE** the results within the user's original query and intent.
|
| 98 |
+
- **PROVIDE** comprehensive explanations that go beyond just presenting raw data.
|
| 99 |
+
- **INTEGRATE** conversation context to make responses personalized and relevant.
|
| 100 |
+
- **FORMAT** responses with appropriate markdown structure for professional presentation.
|
| 101 |
+
|
| 102 |
+
### Response Quality Guidelines
|
| 103 |
+
- **Explain what was done**: Clearly describe what tool(s) were executed and why.
|
| 104 |
+
- **Present results clearly**: Format tool outputs in a user-friendly way.
|
| 105 |
+
- **Provide context**: Explain the significance or implications of the results.
|
| 106 |
+
- **Answer the user's intent**: Address the underlying question, not just the tool output.
|
| 107 |
+
- **Use professional formatting**: Employ headers, lists, code blocks as appropriate.
|
| 108 |
+
|
| 109 |
+
### Tool Result Processing
|
| 110 |
+
- **Parse and understand** different tool output formats (JSON, text, structured data).
|
| 111 |
+
- **Extract key information** and present it in an organized manner.
|
| 112 |
+
- **Explain technical details** in terms accessible to the user.
|
| 113 |
+
- **Connect results** to the user's original question or request.
|
| 114 |
+
- **Provide next steps** or additional insights when relevant.
|
| 115 |
+
|
| 116 |
+
### Professional Presentation Standards
|
| 117 |
+
- Match the formatting quality and structure used in document-based responses
|
| 118 |
+
- Provide explanations that demonstrate understanding of the tool's purpose
|
| 119 |
+
- Include practical context that helps the user understand the results
|
| 120 |
+
- Maintain consistency with HiveGPT's helpful and informative persona
|
| 121 |
+
- Use clear, professional language appropriate for the context
|
| 122 |
+
- **NEVER include technical identifiers, call IDs, or internal system references in your response**
|
| 123 |
+
- Focus on the content and meaning, not the technical implementation details
|
| 124 |
+
"""
|
| 125 |
+
|
| 126 |
+
def _get_human_message_template(self) -> str:
|
| 127 |
+
"""
|
| 128 |
+
Get the human message template for tool result synthesis.
|
| 129 |
+
|
| 130 |
+
Returns:
|
| 131 |
+
Template string for structuring tool results with user context
|
| 132 |
+
"""
|
| 133 |
+
return """**CURRENT DATE/TIME:** {currentDateTime}
|
| 134 |
+
|
| 135 |
+
**ORIGINAL USER QUERY:**
|
| 136 |
+
{query}
|
| 137 |
+
|
| 138 |
+
**TOOL EXECUTION RESULTS:**
|
| 139 |
+
{tool_results}
|
| 140 |
+
|
| 141 |
+
**CONVERSATION CONTEXT:**
|
| 142 |
+
{memory_context}
|
| 143 |
+
|
| 144 |
+
Please synthesize the tool execution results into a comprehensive, well-formatted response that addresses the user's original query. Explain what was accomplished, present the results clearly, and provide context that helps the user understand the significance of the results."""
|
| 145 |
+
|
| 146 |
+
async def ainvoke(self, query: str, tool_results: List[Any], memory_context: Optional[str] = None) -> str:
|
| 147 |
+
"""
|
| 148 |
+
Generate a comprehensive response by synthesizing tool execution results.
|
| 149 |
+
|
| 150 |
+
This method processes tool execution results and creates a well-formatted,
|
| 151 |
+
contextual response that integrates the results with the user's original
|
| 152 |
+
intent and conversation context.
|
| 153 |
+
|
| 154 |
+
The response generation process:
|
| 155 |
+
1. Analyzes and formats tool results for presentation
|
| 156 |
+
2. Integrates conversation context for personalization
|
| 157 |
+
3. Synthesizes results into a comprehensive explanation
|
| 158 |
+
4. Applies professional formatting for clarity
|
| 159 |
+
5. Ensures the response addresses the user's underlying intent
|
| 160 |
+
|
| 161 |
+
Args:
|
| 162 |
+
query: The user's original question or request that triggered tool execution.
|
| 163 |
+
Used to ensure the response addresses the user's actual intent.
|
| 164 |
+
tool_results: List of tool execution results from various tools. Can include
|
| 165 |
+
different formats (JSON strings, text, structured objects).
|
| 166 |
+
memory_context: Optional conversation context to personalize the response
|
| 167 |
+
and maintain conversation continuity.
|
| 168 |
+
|
| 169 |
+
Returns:
|
| 170 |
+
A comprehensive, well-formatted response that synthesizes tool results
|
| 171 |
+
into a user-friendly explanation with professional presentation.
|
| 172 |
+
|
| 173 |
+
Raises:
|
| 174 |
+
Exception: If response generation fails, returns an error message with
|
| 175 |
+
tool results preserved for debugging and transparency.
|
| 176 |
+
|
| 177 |
+
Example:
|
| 178 |
+
>>> chain = ToolResultChain(llm)
|
| 179 |
+
>>> tool_results = [{"status": "success", "result": 42}]
|
| 180 |
+
>>> response = await chain.ainvoke("Calculate 6*7", tool_results)
|
| 181 |
+
>>> print(response) # Comprehensive formatted response explaining the calculation
|
| 182 |
+
"""
|
| 183 |
+
try:
|
| 184 |
+
# Get current timestamp for temporal context
|
| 185 |
+
current_time = datetime.now(ZoneInfo("Europe/Rome")).strftime("%Y-%m-%d %H:%M:%S %Z")
|
| 186 |
+
|
| 187 |
+
# Format tool results for presentation
|
| 188 |
+
formatted_tool_results = self._format_tool_results(tool_results)
|
| 189 |
+
|
| 190 |
+
# Prepare memory context
|
| 191 |
+
context_text = memory_context if memory_context else "No previous conversation context available."
|
| 192 |
+
|
| 193 |
+
# Execute the tool result synthesis chain
|
| 194 |
+
result = await self.chain.ainvoke({
|
| 195 |
+
"query": query,
|
| 196 |
+
"tool_results": formatted_tool_results,
|
| 197 |
+
"memory_context": context_text,
|
| 198 |
+
"currentDateTime": current_time
|
| 199 |
+
})
|
| 200 |
+
|
| 201 |
+
return result
|
| 202 |
+
|
| 203 |
+
except Exception as e:
|
| 204 |
+
# Provide comprehensive error handling while preserving tool results
|
| 205 |
+
error_message = (
|
| 206 |
+
f"I was able to execute the requested tools, but encountered an issue synthesizing the response: {str(e)}\n\n"
|
| 207 |
+
f"Tool execution results: {self._format_tool_results(tool_results)}\n\n"
|
| 208 |
+
f"Your original query: {query}\n\n"
|
| 209 |
+
f"Please try rephrasing your question or contact support if the issue persists."
|
| 210 |
+
)
|
| 211 |
+
return error_message
|
| 212 |
+
|
| 213 |
+
def _format_tool_results(self, tool_results: List[Any]) -> str:
|
| 214 |
+
"""
|
| 215 |
+
Format tool results for presentation in the prompt.
|
| 216 |
+
|
| 217 |
+
Args:
|
| 218 |
+
tool_results: List of tool execution results in various formats
|
| 219 |
+
|
| 220 |
+
Returns:
|
| 221 |
+
Formatted string representation of tool results without technical IDs
|
| 222 |
+
"""
|
| 223 |
+
if not tool_results:
|
| 224 |
+
return "No tool results available."
|
| 225 |
+
|
| 226 |
+
formatted_results = []
|
| 227 |
+
|
| 228 |
+
for i, result in enumerate(tool_results, 1):
|
| 229 |
+
if hasattr(result, 'content'):
|
| 230 |
+
# Tool message with content attribute - exclude tool_call_id from user-facing content
|
| 231 |
+
content = result.content
|
| 232 |
+
formatted_results.append(f"Tool {i} Result:\n{content}")
|
| 233 |
+
elif isinstance(result, dict):
|
| 234 |
+
# Dictionary result
|
| 235 |
+
formatted_results.append(f"Tool {i} Result:\n{str(result)}")
|
| 236 |
+
else:
|
| 237 |
+
# Other formats
|
| 238 |
+
formatted_results.append(f"Tool {i} Result:\n{str(result)}")
|
| 239 |
+
|
| 240 |
+
return "\n\n".join(formatted_results)
|
ComputeAgent/compute_agent_graph.png
ADDED

|
ComputeAgent/graph/__init__.py
ADDED
|
File without changes
|
ComputeAgent/graph/basic_agent_graph.png
ADDED

|
ComputeAgent/graph/graph.py
ADDED
|
@@ -0,0 +1,411 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Basic Agent Main Graph Module (FastAPI Compatible - Minimal Changes)
|
| 3 |
+
|
| 4 |
+
This module implements the core workflow graph for the Basic Agent system.
|
| 5 |
+
It defines the agent's decision-making flow between model deployment and
|
| 6 |
+
React-based compute workflows.
|
| 7 |
+
|
| 8 |
+
CHANGES FROM ORIGINAL:
|
| 9 |
+
- __init__ now accepts optional tools and llm parameters
|
| 10 |
+
- Added async create() classmethod for FastAPI
|
| 11 |
+
- Fully backwards compatible with existing CLI code
|
| 12 |
+
|
| 13 |
+
Author: Your Name
|
| 14 |
+
License: Private
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
import asyncio
|
| 18 |
+
from typing import Dict, Any, List, Optional
|
| 19 |
+
import uuid
|
| 20 |
+
import json
|
| 21 |
+
import logging
|
| 22 |
+
|
| 23 |
+
from langgraph.graph import StateGraph, END, START
|
| 24 |
+
from typing_extensions import TypedDict
|
| 25 |
+
from constant import Constants
|
| 26 |
+
|
| 27 |
+
# Import node functions (to be implemented in separate files)
|
| 28 |
+
from langgraph.checkpoint.memory import MemorySaver
|
| 29 |
+
from graph.graph_deploy import DeployModelAgent
|
| 30 |
+
from graph.graph_ReAct import ReactWorkflow
|
| 31 |
+
from models.model_manager import ModelManager
|
| 32 |
+
from langchain_core.messages import HumanMessage, SystemMessage
|
| 33 |
+
from langchain_mcp_adapters.client import MultiServerMCPClient
|
| 34 |
+
from graph.state import AgentState
|
| 35 |
+
|
| 36 |
+
# Initialize model manager for dynamic LLM loading and management
|
| 37 |
+
model_manager = ModelManager()
|
| 38 |
+
|
| 39 |
+
# Global MemorySaver (persists state across requests)
|
| 40 |
+
memory_saver = MemorySaver()
|
| 41 |
+
|
| 42 |
+
logger = logging.getLogger("ComputeAgent")
|
| 43 |
+
|
| 44 |
+
mcp_client = MultiServerMCPClient(
|
| 45 |
+
{
|
| 46 |
+
"hivecompute": {
|
| 47 |
+
"command": "python",
|
| 48 |
+
"args": ["/home/hivenet/Compute_MCP/main.py"],
|
| 49 |
+
"transport": "stdio"
|
| 50 |
+
}
|
| 51 |
+
}
|
| 52 |
+
)
|
| 53 |
+
|
| 54 |
+
class ComputeAgent:
|
| 55 |
+
"""
|
| 56 |
+
Main Compute Agent class providing AI-powered decision routing and execution.
|
| 57 |
+
|
| 58 |
+
This class orchestrates the complete agent workflow including:
|
| 59 |
+
- Decision routing between model deployment and React agent
|
| 60 |
+
- Model deployment workflow with capacity estimation and approval
|
| 61 |
+
- React agent execution with compute capabilities
|
| 62 |
+
- Error handling and state management
|
| 63 |
+
|
| 64 |
+
Attributes:
|
| 65 |
+
graph: Compiled LangGraph workflow
|
| 66 |
+
model_name: Default model name for operations
|
| 67 |
+
|
| 68 |
+
Usage:
|
| 69 |
+
# For CLI (backwards compatible):
|
| 70 |
+
agent = ComputeAgent()
|
| 71 |
+
|
| 72 |
+
# For FastAPI (async):
|
| 73 |
+
agent = await ComputeAgent.create()
|
| 74 |
+
"""
|
| 75 |
+
|
| 76 |
+
def __init__(self, tools=None, llm=None):
|
| 77 |
+
"""
|
| 78 |
+
Initialize Compute Agent with optional pre-loaded dependencies.
|
| 79 |
+
|
| 80 |
+
Args:
|
| 81 |
+
tools: Pre-loaded MCP tools (optional, will load if not provided)
|
| 82 |
+
llm: Pre-loaded LLM model (optional, will load if not provided)
|
| 83 |
+
"""
|
| 84 |
+
# If tools/llm not provided, load them synchronously (for CLI)
|
| 85 |
+
if tools is None:
|
| 86 |
+
self.tools = asyncio.run(mcp_client.get_tools())
|
| 87 |
+
else:
|
| 88 |
+
self.tools = tools
|
| 89 |
+
|
| 90 |
+
if llm is None:
|
| 91 |
+
self.llm = asyncio.run(model_manager.load_llm_model(Constants.DEFAULT_LLM_FC))
|
| 92 |
+
else:
|
| 93 |
+
self.llm = llm
|
| 94 |
+
|
| 95 |
+
self.deploy_subgraph = DeployModelAgent(llm=self.llm, react_tools=self.tools)
|
| 96 |
+
self.react_subgraph = ReactWorkflow(llm=self.llm, tools=self.tools)
|
| 97 |
+
self.graph = self._create_graph()
|
| 98 |
+
|
| 99 |
+
@classmethod
|
| 100 |
+
async def create(cls):
|
| 101 |
+
"""
|
| 102 |
+
Async factory method for creating ComputeAgent.
|
| 103 |
+
Use this in FastAPI to avoid asyncio.run() issues.
|
| 104 |
+
|
| 105 |
+
Returns:
|
| 106 |
+
Initialized ComputeAgent instance
|
| 107 |
+
"""
|
| 108 |
+
logger.info("🔧 Loading tools and LLM asynchronously...")
|
| 109 |
+
tools = await mcp_client.get_tools()
|
| 110 |
+
llm = await model_manager.load_llm_model(Constants.DEFAULT_LLM_FC)
|
| 111 |
+
# Initialize DeployModelAgent with its own tools
|
| 112 |
+
deploy_subgraph = await DeployModelAgent.create(llm=llm, custom_tools=None)
|
| 113 |
+
return cls(tools=tools, llm=llm)
|
| 114 |
+
|
| 115 |
+
async def decision_node(self, state: Dict[str, Any]) -> Dict[str, Any]:
|
| 116 |
+
"""
|
| 117 |
+
Node that handles routing decisions for the ComputeAgent workflow.
|
| 118 |
+
|
| 119 |
+
Analyzes the user query to determine whether to route to:
|
| 120 |
+
- Model deployment workflow (deploy_model)
|
| 121 |
+
- React agent workflow (react_agent)
|
| 122 |
+
|
| 123 |
+
Args:
|
| 124 |
+
state: Current agent state with memory fields
|
| 125 |
+
|
| 126 |
+
Returns:
|
| 127 |
+
Updated state with routing decision
|
| 128 |
+
"""
|
| 129 |
+
# Get user context
|
| 130 |
+
user_id = state.get("user_id", "")
|
| 131 |
+
session_id = state.get("session_id", "")
|
| 132 |
+
query = state.get("query", "")
|
| 133 |
+
|
| 134 |
+
logger.info(f"🎯 Decision node processing query for {user_id}:{session_id}")
|
| 135 |
+
|
| 136 |
+
# Build memory context for decision making
|
| 137 |
+
memory_context = ""
|
| 138 |
+
if user_id and session_id:
|
| 139 |
+
try:
|
| 140 |
+
from helpers.memory import get_memory_manager
|
| 141 |
+
memory_manager = get_memory_manager()
|
| 142 |
+
memory_context = await memory_manager.build_context_for_node(user_id, session_id, "decision")
|
| 143 |
+
if memory_context:
|
| 144 |
+
logger.info(f"🧠 Using memory context for decision routing")
|
| 145 |
+
except Exception as e:
|
| 146 |
+
logger.warning(f"⚠️ Could not load memory context for decision: {e}")
|
| 147 |
+
|
| 148 |
+
try:
|
| 149 |
+
# Create a simple LLM for decision making
|
| 150 |
+
# Load main LLM using ModelManager
|
| 151 |
+
llm = await model_manager.load_llm_model(Constants.DEFAULT_LLM_NAME)
|
| 152 |
+
|
| 153 |
+
# Create decision prompt
|
| 154 |
+
decision_system_prompt = f"""
|
| 155 |
+
You are a routing assistant for ComputeAgent. Analyze the user's query and decide which workflow to use.
|
| 156 |
+
|
| 157 |
+
Choose between:
|
| 158 |
+
1. DEPLOY_MODEL - For queries about deploy AI model from HuggingFace. In this case the user MUST specify the model card name (like meta-llama/Meta-Llama-3-70B).
|
| 159 |
+
- The user can specify the hardware capacity needed.
|
| 160 |
+
- The user can ask for model analysis, deployment steps, or capacity estimation.
|
| 161 |
+
|
| 162 |
+
2. REACT_AGENT - For all the rest of queries.
|
| 163 |
+
|
| 164 |
+
{f"Conversation Context: {memory_context}" if memory_context else "No conversation context available."}
|
| 165 |
+
|
| 166 |
+
User Query: {query}
|
| 167 |
+
|
| 168 |
+
Respond with only: "DEPLOY_MODEL" or "REACT_AGENT"
|
| 169 |
+
"""
|
| 170 |
+
|
| 171 |
+
# Get routing decision
|
| 172 |
+
decision_response = await llm.ainvoke([
|
| 173 |
+
SystemMessage(content=decision_system_prompt)
|
| 174 |
+
])
|
| 175 |
+
|
| 176 |
+
routing_decision = decision_response.content.strip().upper()
|
| 177 |
+
|
| 178 |
+
# Validate and set decision
|
| 179 |
+
if "DEPLOY_MODEL" in routing_decision:
|
| 180 |
+
agent_decision = "deploy_model"
|
| 181 |
+
logger.info(f"📦 Routing to model deployment workflow")
|
| 182 |
+
elif "REACT_AGENT" in routing_decision:
|
| 183 |
+
agent_decision = "react_agent"
|
| 184 |
+
logger.info(f"⚛️ Routing to React agent workflow")
|
| 185 |
+
else:
|
| 186 |
+
# Default fallback to React agent for general queries
|
| 187 |
+
agent_decision = "react_agent"
|
| 188 |
+
logger.warning(f"⚠️ Ambiguous routing decision '{routing_decision}', defaulting to React agent")
|
| 189 |
+
|
| 190 |
+
# Update state with decision
|
| 191 |
+
updated_state = state.copy()
|
| 192 |
+
updated_state["agent_decision"] = agent_decision
|
| 193 |
+
updated_state["current_step"] = "decision_complete"
|
| 194 |
+
|
| 195 |
+
logger.info(f"✅ Decision node complete: {agent_decision}")
|
| 196 |
+
return updated_state
|
| 197 |
+
|
| 198 |
+
except Exception as e:
|
| 199 |
+
logger.error(f"❌ Error in decision node: {e}")
|
| 200 |
+
|
| 201 |
+
# Update state with fallback decision
|
| 202 |
+
updated_state = state.copy()
|
| 203 |
+
updated_state["error"] = f"Decision error (fallback used): {str(e)}"
|
| 204 |
+
|
| 205 |
+
return updated_state
|
| 206 |
+
|
| 207 |
+
def _create_graph(self) -> StateGraph:
|
| 208 |
+
"""
|
| 209 |
+
Create and configure the Compute Agent workflow graph.
|
| 210 |
+
|
| 211 |
+
This method builds the complete workflow including:
|
| 212 |
+
1. Initial decision node - routes to deployment or React agent
|
| 213 |
+
2. Model deployment path:
|
| 214 |
+
- Fetch model card from HuggingFace
|
| 215 |
+
- Extract model information
|
| 216 |
+
- Estimate capacity requirements
|
| 217 |
+
- Human approval checkpoint
|
| 218 |
+
- Deploy model or provide info
|
| 219 |
+
3. React agent path:
|
| 220 |
+
- Execute React agent with compute MCP capabilities
|
| 221 |
+
|
| 222 |
+
Returns:
|
| 223 |
+
Compiled StateGraph ready for execution
|
| 224 |
+
"""
|
| 225 |
+
workflow = StateGraph(AgentState)
|
| 226 |
+
|
| 227 |
+
# Add decision node
|
| 228 |
+
workflow.add_node("decision", self.decision_node)
|
| 229 |
+
|
| 230 |
+
# Add model deployment workflow nodes
|
| 231 |
+
workflow.add_node("deploy_model", self.deploy_subgraph.get_compiled_graph())
|
| 232 |
+
|
| 233 |
+
# Add React agent node
|
| 234 |
+
workflow.add_node("react_agent", self.react_subgraph.get_compiled_graph())
|
| 235 |
+
|
| 236 |
+
# Set entry point
|
| 237 |
+
workflow.set_entry_point("decision")
|
| 238 |
+
|
| 239 |
+
# Add conditional edges from decision node
|
| 240 |
+
workflow.add_conditional_edges(
|
| 241 |
+
"decision",
|
| 242 |
+
lambda state: state["agent_decision"],
|
| 243 |
+
{
|
| 244 |
+
"deploy_model": "deploy_model",
|
| 245 |
+
"react_agent": "react_agent",
|
| 246 |
+
}
|
| 247 |
+
)
|
| 248 |
+
|
| 249 |
+
# Add edges to END
|
| 250 |
+
workflow.add_edge("deploy_model", END)
|
| 251 |
+
workflow.add_edge("react_agent", END)
|
| 252 |
+
|
| 253 |
+
# Compile with checkpointer
|
| 254 |
+
return workflow.compile(checkpointer=memory_saver)
|
| 255 |
+
|
| 256 |
+
def get_compiled_graph(self):
|
| 257 |
+
"""Return the compiled graph for use in FastAPI"""
|
| 258 |
+
return self.graph
|
| 259 |
+
|
| 260 |
+
def invoke(self, query: str, user_id: str = "default_user", session_id: str = "default_session") -> Dict[str, Any]:
|
| 261 |
+
"""
|
| 262 |
+
Execute the graph with a given query and memory context (synchronous wrapper for async).
|
| 263 |
+
|
| 264 |
+
Args:
|
| 265 |
+
query: User's query
|
| 266 |
+
user_id: User identifier for memory management
|
| 267 |
+
session_id: Session identifier for memory management
|
| 268 |
+
|
| 269 |
+
Returns:
|
| 270 |
+
Final result from the graph execution
|
| 271 |
+
"""
|
| 272 |
+
return asyncio.run(self.ainvoke(query, user_id, session_id))
|
| 273 |
+
|
| 274 |
+
async def ainvoke(self, query: str, user_id: str = "default_user", session_id: str = "default_session") -> Dict[str, Any]:
|
| 275 |
+
"""
|
| 276 |
+
Execute the graph with a given query and memory context (async).
|
| 277 |
+
|
| 278 |
+
Args:
|
| 279 |
+
query: User's query
|
| 280 |
+
user_id: User identifier for memory management
|
| 281 |
+
session_id: Session identifier for memory management
|
| 282 |
+
|
| 283 |
+
Returns:
|
| 284 |
+
Final result from the graph execution containing:
|
| 285 |
+
- response: Final response to user
|
| 286 |
+
- agent_decision: Which path was taken
|
| 287 |
+
- deployment_result: If deployment path was taken
|
| 288 |
+
- react_results: If React agent path was taken
|
| 289 |
+
"""
|
| 290 |
+
initial_state = {
|
| 291 |
+
"user_id": user_id,
|
| 292 |
+
"session_id": session_id,
|
| 293 |
+
"query": query,
|
| 294 |
+
"response": "",
|
| 295 |
+
"current_step": "start",
|
| 296 |
+
"agent_decision": "",
|
| 297 |
+
"deployment_approved": False,
|
| 298 |
+
"model_name": "",
|
| 299 |
+
"model_card": {},
|
| 300 |
+
"model_info": {},
|
| 301 |
+
"capacity_estimate": {},
|
| 302 |
+
"deployment_result": {},
|
| 303 |
+
"react_results": {},
|
| 304 |
+
"tool_calls": [],
|
| 305 |
+
"tool_results": [],
|
| 306 |
+
"messages": [],
|
| 307 |
+
# Approval fields for ReactWorkflow
|
| 308 |
+
"pending_tool_calls": [],
|
| 309 |
+
"approved_tool_calls": [],
|
| 310 |
+
"rejected_tool_calls": [],
|
| 311 |
+
"modified_tool_calls": [],
|
| 312 |
+
"needs_re_reasoning": False,
|
| 313 |
+
"re_reasoning_feedback": ""
|
| 314 |
+
}
|
| 315 |
+
|
| 316 |
+
# Create config with thread_id for checkpointer
|
| 317 |
+
config = {
|
| 318 |
+
"configurable": {
|
| 319 |
+
"thread_id": f"{user_id}_{session_id}"
|
| 320 |
+
}
|
| 321 |
+
}
|
| 322 |
+
|
| 323 |
+
try:
|
| 324 |
+
result = await self.graph.ainvoke(initial_state, config)
|
| 325 |
+
return result
|
| 326 |
+
|
| 327 |
+
except Exception as e:
|
| 328 |
+
logger.error(f"Error in graph execution: {e}")
|
| 329 |
+
return {
|
| 330 |
+
**initial_state,
|
| 331 |
+
"error": str(e),
|
| 332 |
+
"error_step": initial_state.get("current_step", "unknown"),
|
| 333 |
+
"response": f"An error occurred during execution: {str(e)}"
|
| 334 |
+
}
|
| 335 |
+
|
| 336 |
+
async def astream_generate_nodes(self, query: str, user_id: str = "default_user", session_id: str = "default_session"):
|
| 337 |
+
"""
|
| 338 |
+
Stream the graph execution node by node (async).
|
| 339 |
+
|
| 340 |
+
Args:
|
| 341 |
+
query: User's query
|
| 342 |
+
user_id: User identifier for memory management
|
| 343 |
+
session_id: Session identifier for memory management
|
| 344 |
+
|
| 345 |
+
Yields:
|
| 346 |
+
Dict containing node execution updates
|
| 347 |
+
"""
|
| 348 |
+
initial_state = {
|
| 349 |
+
"user_id": user_id,
|
| 350 |
+
"session_id": session_id,
|
| 351 |
+
"query": query,
|
| 352 |
+
"response": "",
|
| 353 |
+
"current_step": "start",
|
| 354 |
+
"agent_decision": "",
|
| 355 |
+
"deployment_approved": False,
|
| 356 |
+
"model_name": "",
|
| 357 |
+
"model_card": {},
|
| 358 |
+
"model_info": {},
|
| 359 |
+
"capacity_estimate": {},
|
| 360 |
+
"deployment_result": {},
|
| 361 |
+
"react_results": {},
|
| 362 |
+
"tool_calls": [],
|
| 363 |
+
"tool_results": [],
|
| 364 |
+
"messages": [],
|
| 365 |
+
# Approval fields for ReactWorkflow
|
| 366 |
+
"pending_tool_calls": [],
|
| 367 |
+
"approved_tool_calls": [],
|
| 368 |
+
"rejected_tool_calls": [],
|
| 369 |
+
"modified_tool_calls": [],
|
| 370 |
+
"needs_re_reasoning": False,
|
| 371 |
+
"re_reasoning_feedback": ""
|
| 372 |
+
}
|
| 373 |
+
|
| 374 |
+
# Create config with thread_id for checkpointer
|
| 375 |
+
config = {
|
| 376 |
+
"configurable": {
|
| 377 |
+
"thread_id": f"{user_id}_{session_id}"
|
| 378 |
+
}
|
| 379 |
+
}
|
| 380 |
+
|
| 381 |
+
try:
|
| 382 |
+
# Stream through the graph execution
|
| 383 |
+
async for chunk in self.graph.astream(initial_state, config):
|
| 384 |
+
# Each chunk contains the node name and its output
|
| 385 |
+
for node_name, node_output in chunk.items():
|
| 386 |
+
yield {
|
| 387 |
+
"node": node_name,
|
| 388 |
+
"output": node_output,
|
| 389 |
+
**node_output # Include all state updates
|
| 390 |
+
}
|
| 391 |
+
|
| 392 |
+
except Exception as e:
|
| 393 |
+
logger.error(f"Error in graph streaming: {e}")
|
| 394 |
+
yield {
|
| 395 |
+
"error": str(e),
|
| 396 |
+
"status": "error",
|
| 397 |
+
"error_step": initial_state.get("current_step", "unknown")
|
| 398 |
+
}
|
| 399 |
+
|
| 400 |
+
def draw_graph(self, output_file_path: str = "basic_agent_graph.png"):
|
| 401 |
+
"""
|
| 402 |
+
Generate and save a visual representation of the Basic Agent workflow graph.
|
| 403 |
+
|
| 404 |
+
Args:
|
| 405 |
+
output_file_path: Path where to save the graph PNG file
|
| 406 |
+
"""
|
| 407 |
+
try:
|
| 408 |
+
self.graph.get_graph().draw_mermaid_png(output_file_path=output_file_path)
|
| 409 |
+
logger.info(f"✅ Basic Agent graph visualization saved to: {output_file_path}")
|
| 410 |
+
except Exception as e:
|
| 411 |
+
logger.error(f"❌ Failed to generate Basic Agent graph visualization: {e}")
|
ComputeAgent/graph/graph_ReAct.py
ADDED
|
@@ -0,0 +1,331 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
"""
|
| 3 |
+
HiveGPT Agent ReAct Graph Module
|
| 4 |
+
|
| 5 |
+
This module implements the ReAct workflow for the HiveGPT Agent system.
|
| 6 |
+
It orchestrates agent reasoning, human approval, tool execution, and response refinement
|
| 7 |
+
using LangGraph for workflow management and memory support.
|
| 8 |
+
|
| 9 |
+
Key Features:
|
| 10 |
+
- Human-in-the-loop approval for tool execution
|
| 11 |
+
- MCP tool integration
|
| 12 |
+
- Memory-enabled state management
|
| 13 |
+
- Modular node functions for extensibility
|
| 14 |
+
|
| 15 |
+
Author: HiveNetCode
|
| 16 |
+
License: Private
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
from typing import Sequence, Dict, Any
|
| 20 |
+
from langchain_core.tools import BaseTool
|
| 21 |
+
from langchain_core.messages import HumanMessage
|
| 22 |
+
from langgraph.graph import StateGraph, END
|
| 23 |
+
import logging
|
| 24 |
+
from typing_extensions import TypedDict
|
| 25 |
+
from typing import Dict, Any, Sequence, List
|
| 26 |
+
from langchain_core.messages import BaseMessage
|
| 27 |
+
from langchain_core.tools import BaseTool
|
| 28 |
+
from langchain_openai.chat_models import ChatOpenAI
|
| 29 |
+
from graph.state import AgentState
|
| 30 |
+
|
| 31 |
+
from nodes.ReAct import (
|
| 32 |
+
agent_reasoning_node,
|
| 33 |
+
human_approval_node,
|
| 34 |
+
auto_approval_node,
|
| 35 |
+
tool_execution_node,
|
| 36 |
+
generate_node,
|
| 37 |
+
tool_rejection_exit_node,
|
| 38 |
+
should_continue_to_approval,
|
| 39 |
+
should_continue_after_approval,
|
| 40 |
+
should_continue_after_execution
|
| 41 |
+
)
|
| 42 |
+
logger = logging.getLogger("ReAct Workflow")
|
| 43 |
+
|
| 44 |
+
# Global registries (to avoid serialization issues with checkpointer)
|
| 45 |
+
# Nodes access tools and LLM from here instead of storing them in state
|
| 46 |
+
_TOOLS_REGISTRY = {}
|
| 47 |
+
_LLM_REGISTRY = {}
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
# State class for ReAct workflow
|
| 51 |
+
class ReactState(AgentState):
|
| 52 |
+
"""
|
| 53 |
+
ReactState extends HiveGPTMemoryState to support ReAct workflow fields.
|
| 54 |
+
"""
|
| 55 |
+
pass
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
# Main workflow class for ReAct
|
| 59 |
+
class ReactWorkflow:
|
| 60 |
+
"""
|
| 61 |
+
Orchestrates the ReAct workflow:
|
| 62 |
+
1. Agent reasoning and tool selection
|
| 63 |
+
2. Human approval for tool execution
|
| 64 |
+
3. Tool execution (special handling for researcher tool)
|
| 65 |
+
4. Response refinement (skipped for researcher tool)
|
| 66 |
+
|
| 67 |
+
Features:
|
| 68 |
+
- MCP tool integration
|
| 69 |
+
- Human-in-the-loop approval for all tool calls
|
| 70 |
+
- Special handling for researcher tool (bypasses refinement, uses generate_node)
|
| 71 |
+
- Memory management with conversation summaries and recent message context
|
| 72 |
+
- Proper state management following AgenticRAG pattern
|
| 73 |
+
"""
|
| 74 |
+
def __init__(self, llm, tools: Sequence[BaseTool]):
|
| 75 |
+
"""
|
| 76 |
+
Initialize ReAct workflow with LLMs, tools, and optional memory checkpointer.
|
| 77 |
+
|
| 78 |
+
Args:
|
| 79 |
+
llm: Main LLM for reasoning (will be bound with tools)
|
| 80 |
+
refining_llm: LLM for response refinement
|
| 81 |
+
tools: Sequence of MCP tools for execution
|
| 82 |
+
checkpointer: Optional memory checkpointer for conversation memory
|
| 83 |
+
"""
|
| 84 |
+
self.llm = llm.bind_tools(tools)
|
| 85 |
+
self.tools = tools
|
| 86 |
+
|
| 87 |
+
# Register tools and LLM in global registry to avoid serialization issues
|
| 88 |
+
# Nodes will access them from the registry instead of state
|
| 89 |
+
self.workflow_id = id(self)
|
| 90 |
+
_TOOLS_REGISTRY[self.workflow_id] = tools
|
| 91 |
+
_LLM_REGISTRY[self.workflow_id] = self.llm
|
| 92 |
+
logger.info(f"✅ Registered {len(tools)} tools and LLM in global registry (ID: {self.workflow_id})")
|
| 93 |
+
|
| 94 |
+
self.graph = self._create_graph()
|
| 95 |
+
|
| 96 |
+
def _initialize_react_state(self, state: Dict[str, Any]) -> Dict[str, Any]:
|
| 97 |
+
"""
|
| 98 |
+
Initialize or update state with workflow_id.
|
| 99 |
+
The workflow_id is used to retrieve both tools and LLM from the global registry,
|
| 100 |
+
avoiding serialization issues with the checkpointer.
|
| 101 |
+
|
| 102 |
+
Args:
|
| 103 |
+
state: Current state (may be from parent graph)
|
| 104 |
+
|
| 105 |
+
Returns:
|
| 106 |
+
Updated state with workflow_id
|
| 107 |
+
"""
|
| 108 |
+
updated_state = state.copy()
|
| 109 |
+
|
| 110 |
+
# Store workflow ID for registry lookup (both tools and LLM)
|
| 111 |
+
if not updated_state.get("workflow_id"):
|
| 112 |
+
updated_state["workflow_id"] = self.workflow_id
|
| 113 |
+
logger.info(f"✅ Workflow ID set in state: {self.workflow_id}")
|
| 114 |
+
|
| 115 |
+
# Initialize messages if empty (when coming from parent graph)
|
| 116 |
+
if not updated_state.get("messages"):
|
| 117 |
+
query = updated_state.get("query", "")
|
| 118 |
+
if query:
|
| 119 |
+
updated_state["messages"] = [HumanMessage(content=query)]
|
| 120 |
+
logger.info(f"💬 Initialized messages with query for ReACT workflow")
|
| 121 |
+
else:
|
| 122 |
+
updated_state["messages"] = []
|
| 123 |
+
logger.warning(f"⚠️ No query found to initialize messages")
|
| 124 |
+
|
| 125 |
+
return updated_state
|
| 126 |
+
|
| 127 |
+
def _create_graph(self) -> StateGraph:
|
| 128 |
+
"""
|
| 129 |
+
Creates and configures the ReAct workflow graph with memory support.
|
| 130 |
+
|
| 131 |
+
Returns:
|
| 132 |
+
Compiled StateGraph for ReAct workflow
|
| 133 |
+
"""
|
| 134 |
+
workflow = StateGraph(ReactState)
|
| 135 |
+
|
| 136 |
+
# Add initialization node to set up LLM and tools
|
| 137 |
+
workflow.add_node("initialize_react", self._initialize_react_state)
|
| 138 |
+
|
| 139 |
+
# Add nodes - REMOVED refinement node, always use generate for final response
|
| 140 |
+
workflow.add_node("agent_reasoning", agent_reasoning_node)
|
| 141 |
+
workflow.add_node("human_approval", human_approval_node)
|
| 142 |
+
workflow.add_node("auto_approval", auto_approval_node)
|
| 143 |
+
workflow.add_node("tool_execution", tool_execution_node)
|
| 144 |
+
workflow.add_node("generate", generate_node)
|
| 145 |
+
workflow.add_node("tool_rejection_exit", tool_rejection_exit_node)
|
| 146 |
+
|
| 147 |
+
# Set entry point - start with initialization
|
| 148 |
+
workflow.set_entry_point("initialize_react")
|
| 149 |
+
|
| 150 |
+
# Connect initialization to agent reasoning
|
| 151 |
+
workflow.add_edge("initialize_react", "agent_reasoning")
|
| 152 |
+
|
| 153 |
+
# Add conditional edges from agent reasoning
|
| 154 |
+
workflow.add_conditional_edges(
|
| 155 |
+
"agent_reasoning",
|
| 156 |
+
should_continue_to_approval,
|
| 157 |
+
{
|
| 158 |
+
"human_approval": "human_approval",
|
| 159 |
+
"auto_approval": "auto_approval",
|
| 160 |
+
"generate": "generate", # Changed from refinement to generate
|
| 161 |
+
}
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
# Add conditional edges from human approval
|
| 165 |
+
workflow.add_conditional_edges(
|
| 166 |
+
"human_approval",
|
| 167 |
+
should_continue_after_approval,
|
| 168 |
+
{
|
| 169 |
+
"tool_execution": "tool_execution",
|
| 170 |
+
"tool_rejection_exit": "tool_rejection_exit",
|
| 171 |
+
"agent_reasoning": "agent_reasoning", # For re-reasoning
|
| 172 |
+
}
|
| 173 |
+
)
|
| 174 |
+
|
| 175 |
+
# Add conditional edges from auto approval (for consistency with human approval)
|
| 176 |
+
workflow.add_conditional_edges(
|
| 177 |
+
"auto_approval",
|
| 178 |
+
should_continue_after_approval,
|
| 179 |
+
{
|
| 180 |
+
"tool_execution": "tool_execution",
|
| 181 |
+
"tool_rejection_exit": "tool_rejection_exit",
|
| 182 |
+
"agent_reasoning": "agent_reasoning", # For re-reasoning
|
| 183 |
+
}
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
# Add conditional edges from tool execution
|
| 187 |
+
workflow.add_conditional_edges(
|
| 188 |
+
"tool_execution",
|
| 189 |
+
should_continue_after_execution,
|
| 190 |
+
{
|
| 191 |
+
"agent_reasoning": "agent_reasoning",
|
| 192 |
+
"generate": "generate", # Always generate, never refinement
|
| 193 |
+
}
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
# Generate goes directly to END (response formatting is done in generate_node)
|
| 197 |
+
workflow.add_edge("generate", END)
|
| 198 |
+
|
| 199 |
+
# Generation goes directly to END (response formatting is done in generate_node)
|
| 200 |
+
workflow.add_edge("generate", END)
|
| 201 |
+
|
| 202 |
+
# Tool rejection exit goes to END
|
| 203 |
+
workflow.add_edge("tool_rejection_exit", END)
|
| 204 |
+
|
| 205 |
+
# Compile with memory checkpointer if provided
|
| 206 |
+
return workflow.compile()
|
| 207 |
+
|
| 208 |
+
def get_compiled_graph(self):
|
| 209 |
+
"""Return the compiled graph for embedding in parent graph"""
|
| 210 |
+
return self.graph
|
| 211 |
+
|
| 212 |
+
async def ainvoke(self, query: str, user_id: str = "default_user", session_id: str = "default_session") -> Dict[str, Any]:
|
| 213 |
+
"""
|
| 214 |
+
Execute the ReAct workflow with a given query and memory context (async version).
|
| 215 |
+
|
| 216 |
+
Args:
|
| 217 |
+
query: The user's question/request
|
| 218 |
+
user_id: User identifier for memory management
|
| 219 |
+
session_id: Session identifier for memory management
|
| 220 |
+
|
| 221 |
+
Returns:
|
| 222 |
+
Final state with response and execution details
|
| 223 |
+
"""
|
| 224 |
+
initial_state = {
|
| 225 |
+
# Memory fields
|
| 226 |
+
"user_id": user_id,
|
| 227 |
+
"session_id": session_id,
|
| 228 |
+
"summary": "", # Will be loaded from memory if available
|
| 229 |
+
|
| 230 |
+
# Core fields
|
| 231 |
+
"query": query,
|
| 232 |
+
"response": "",
|
| 233 |
+
"messages": [HumanMessage(content=query)],
|
| 234 |
+
|
| 235 |
+
# Tool-related state
|
| 236 |
+
"tools": self.tools,
|
| 237 |
+
"pending_tool_calls": [],
|
| 238 |
+
"approved_tool_calls": [],
|
| 239 |
+
"rejected_tool_calls": [],
|
| 240 |
+
"tool_results": [],
|
| 241 |
+
|
| 242 |
+
# LLM instances
|
| 243 |
+
"llm": self.llm,
|
| 244 |
+
|
| 245 |
+
# Flow control
|
| 246 |
+
"current_step": "initialized",
|
| 247 |
+
"skip_refinement": False,
|
| 248 |
+
"researcher_executed": False,
|
| 249 |
+
|
| 250 |
+
# Retrieved data (for researcher integration)
|
| 251 |
+
"retrieved_documents": [],
|
| 252 |
+
"search_results": "",
|
| 253 |
+
"web_search": "No",
|
| 254 |
+
|
| 255 |
+
# Final response formatting
|
| 256 |
+
"final_response_dict": {}
|
| 257 |
+
}
|
| 258 |
+
|
| 259 |
+
# Configure thread for memory if checkpointer is available
|
| 260 |
+
config = None
|
| 261 |
+
if self.checkpointer:
|
| 262 |
+
from helpers.memory import get_memory_manager
|
| 263 |
+
memory_manager = get_memory_manager()
|
| 264 |
+
thread_id = f"{user_id}:{session_id}"
|
| 265 |
+
config = {"configurable": {"thread_id": thread_id}}
|
| 266 |
+
|
| 267 |
+
# Add user message to memory
|
| 268 |
+
await memory_manager.add_user_message(user_id, session_id, query)
|
| 269 |
+
|
| 270 |
+
logger.info(f"🚀 Starting ReAct workflow for user {user_id}, session {session_id}")
|
| 271 |
+
|
| 272 |
+
if config:
|
| 273 |
+
result = await self.graph.ainvoke(initial_state, config)
|
| 274 |
+
else:
|
| 275 |
+
result = await self.graph.ainvoke(initial_state)
|
| 276 |
+
|
| 277 |
+
# Add AI response to memory if checkpointer is available
|
| 278 |
+
if self.checkpointer and result.get("response"):
|
| 279 |
+
from helpers.memory import get_memory_manager
|
| 280 |
+
memory_manager = get_memory_manager()
|
| 281 |
+
await memory_manager.add_ai_response(user_id, session_id, result["response"])
|
| 282 |
+
|
| 283 |
+
logger.info("✅ ReAct workflow completed successfully")
|
| 284 |
+
return result
|
| 285 |
+
|
| 286 |
+
def invoke(self, query: str, user_id: str = "default_user", session_id: str = "default_session") -> Dict[str, Any]:
|
| 287 |
+
"""
|
| 288 |
+
Synchronous wrapper for async workflow with memory support.
|
| 289 |
+
|
| 290 |
+
Args:
|
| 291 |
+
query: The user's question/request
|
| 292 |
+
user_id: User identifier for memory management
|
| 293 |
+
session_id: Session identifier for memory management
|
| 294 |
+
|
| 295 |
+
Returns:
|
| 296 |
+
Final state with response and execution details
|
| 297 |
+
"""
|
| 298 |
+
import asyncio
|
| 299 |
+
try:
|
| 300 |
+
# Try to get existing event loop
|
| 301 |
+
loop = asyncio.get_event_loop()
|
| 302 |
+
if loop.is_running():
|
| 303 |
+
# If loop is running, create a task
|
| 304 |
+
import concurrent.futures
|
| 305 |
+
with concurrent.futures.ThreadPoolExecutor() as executor:
|
| 306 |
+
future = executor.submit(asyncio.run, self.ainvoke(query, user_id, session_id))
|
| 307 |
+
return future.result()
|
| 308 |
+
else:
|
| 309 |
+
# Run directly
|
| 310 |
+
return loop.run_until_complete(self.ainvoke(query, user_id, session_id))
|
| 311 |
+
except RuntimeError:
|
| 312 |
+
# No event loop, create new one
|
| 313 |
+
return asyncio.run(self.ainvoke(query, user_id, session_id))
|
| 314 |
+
|
| 315 |
+
def draw_graph(self, output_file_path: str = "react_workflow_graph.png"):
|
| 316 |
+
"""
|
| 317 |
+
Generate and save a visual representation of the ReAct workflow graph.
|
| 318 |
+
|
| 319 |
+
Args:
|
| 320 |
+
output_file_path: Path where to save the graph PNG file
|
| 321 |
+
"""
|
| 322 |
+
try:
|
| 323 |
+
self.graph.get_graph().draw_mermaid_png(output_file_path=output_file_path)
|
| 324 |
+
logger.info(f"✅ ReAct graph visualization saved to: {output_file_path}")
|
| 325 |
+
except Exception as e:
|
| 326 |
+
logger.error(f"❌ Failed to generate ReAct graph visualization: {e}")
|
| 327 |
+
print(f"Error generating ReAct graph: {e}")
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
# Legacy ReactAgent class for backward compatibility
|
| 331 |
+
ReactAgent = ReactWorkflow
|
ComputeAgent/graph/graph_deploy.py
ADDED
|
@@ -0,0 +1,363 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Deploy Model Graph - FIXED
|
| 3 |
+
|
| 4 |
+
This module implements the model deployment workflow graph for the ComputeAgent.
|
| 5 |
+
|
| 6 |
+
KEY FIX: DeployModelState now correctly inherits from AgentState (TypedDict)
|
| 7 |
+
instead of StateGraph.
|
| 8 |
+
|
| 9 |
+
Author: ComputeAgent Team
|
| 10 |
+
License: Private
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
import logging
|
| 14 |
+
from typing import Dict, Any, Optional
|
| 15 |
+
from langgraph.graph import StateGraph, END
|
| 16 |
+
from langgraph.graph.state import CompiledStateGraph
|
| 17 |
+
from graph.graph_ReAct import ReactWorkflow
|
| 18 |
+
from graph.state import AgentState
|
| 19 |
+
|
| 20 |
+
# Import nodes from ReAct_DeployModel package
|
| 21 |
+
from nodes.ReAct_DeployModel.extract_model_info import extract_model_info_node
|
| 22 |
+
from nodes.ReAct_DeployModel.generate_additional_info import generate_additional_info_node
|
| 23 |
+
from nodes.ReAct_DeployModel.capacity_estimation import capacity_estimation_node
|
| 24 |
+
from nodes.ReAct_DeployModel.capacity_approval import capacity_approval_node, auto_capacity_approval_node
|
| 25 |
+
from models.model_manager import ModelManager
|
| 26 |
+
from langchain_mcp_adapters.client import MultiServerMCPClient
|
| 27 |
+
|
| 28 |
+
# Import constants for human approval settings
|
| 29 |
+
from constant import Constants
|
| 30 |
+
|
| 31 |
+
# Initialize model manager for dynamic LLM loading and management
|
| 32 |
+
model_manager = ModelManager()
|
| 33 |
+
|
| 34 |
+
logger = logging.getLogger("ComputeAgent")
|
| 35 |
+
|
| 36 |
+
mcp_client = MultiServerMCPClient(
|
| 37 |
+
{
|
| 38 |
+
"hivecompute": {
|
| 39 |
+
"command": "python",
|
| 40 |
+
"args": ["/home/hivenet/Compute_MCP/main.py"],
|
| 41 |
+
"transport": "stdio"
|
| 42 |
+
}
|
| 43 |
+
}
|
| 44 |
+
)
|
| 45 |
+
|
| 46 |
+
logger = logging.getLogger("DeployModelGraph")
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
# Now inherits from AgentState (TypedDict) instead of StateGraph
|
| 50 |
+
class DeployModelState(AgentState):
|
| 51 |
+
"""
|
| 52 |
+
DeployModelState extends AgentState to inherit all base agent fields.
|
| 53 |
+
|
| 54 |
+
Inherited from AgentState (TypedDict):
|
| 55 |
+
- query: str
|
| 56 |
+
- response: str
|
| 57 |
+
- current_step: str
|
| 58 |
+
- messages: List[Dict[str, Any]]
|
| 59 |
+
- agent_decision: str
|
| 60 |
+
- deployment_approved: bool
|
| 61 |
+
- model_name: str
|
| 62 |
+
- llm: Any
|
| 63 |
+
- model_card: Dict[str, Any]
|
| 64 |
+
- model_info: Dict[str, Any]
|
| 65 |
+
- capacity_estimate: Dict[str, Any]
|
| 66 |
+
- deployment_result: Dict[str, Any]
|
| 67 |
+
- react_results: Dict[str, Any]
|
| 68 |
+
- tool_calls: List[Dict[str, Any]]
|
| 69 |
+
- tool_results: List[Dict[str, Any]]
|
| 70 |
+
|
| 71 |
+
All fields are inherited from AgentState - no additional fields needed.
|
| 72 |
+
"""
|
| 73 |
+
pass # Inherits all fields from AgentState
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class DeployModelAgent:
|
| 77 |
+
"""
|
| 78 |
+
Standalone Deploy Model Agent class with memory and streaming support.
|
| 79 |
+
|
| 80 |
+
This class provides a dedicated interface for model deployment workflows
|
| 81 |
+
with full memory management and streaming capabilities.
|
| 82 |
+
"""
|
| 83 |
+
|
| 84 |
+
def __init__(self, llm, react_tools):
|
| 85 |
+
self.llm = llm
|
| 86 |
+
self.react_tools = react_tools
|
| 87 |
+
self.react_subgraph = ReactWorkflow(llm=self.llm, tools=self.react_tools)
|
| 88 |
+
self.graph = self._create_graph()
|
| 89 |
+
|
| 90 |
+
@classmethod
|
| 91 |
+
async def create(cls, llm=None, custom_tools=None):
|
| 92 |
+
"""
|
| 93 |
+
Async factory method for DeployModelAgent.
|
| 94 |
+
|
| 95 |
+
Args:
|
| 96 |
+
llm: Optional pre-loaded LLM
|
| 97 |
+
custom_tools: Optional pre-loaded tools for the nested ReactWorkflow
|
| 98 |
+
|
| 99 |
+
Returns:
|
| 100 |
+
DeployModelAgent instance
|
| 101 |
+
"""
|
| 102 |
+
if llm is None:
|
| 103 |
+
llm = await model_manager.load_llm_model(Constants.DEFAULT_LLM_FC)
|
| 104 |
+
|
| 105 |
+
if custom_tools is None:
|
| 106 |
+
# Load a separate MCP toolset for deployment React
|
| 107 |
+
custom_tools = await mcp_client.get_tools()
|
| 108 |
+
|
| 109 |
+
return cls(llm=llm, react_tools=custom_tools)
|
| 110 |
+
|
| 111 |
+
def _create_graph(self) -> CompiledStateGraph:
|
| 112 |
+
"""
|
| 113 |
+
Creates and configures the deploy model workflow.
|
| 114 |
+
|
| 115 |
+
✅ FIXED: Now correctly creates StateGraph with DeployModelState (TypedDict)
|
| 116 |
+
"""
|
| 117 |
+
# ✅ This now works because DeployModelState is a TypedDict (via AgentState)
|
| 118 |
+
workflow = StateGraph(DeployModelState)
|
| 119 |
+
|
| 120 |
+
# Add nodes
|
| 121 |
+
workflow.add_node("extract_model_info", extract_model_info_node)
|
| 122 |
+
workflow.add_node("generate_model_name", generate_additional_info_node)
|
| 123 |
+
workflow.add_node("capacity_estimation", capacity_estimation_node)
|
| 124 |
+
workflow.add_node("capacity_approval", capacity_approval_node)
|
| 125 |
+
workflow.add_node("auto_capacity_approval", auto_capacity_approval_node)
|
| 126 |
+
workflow.add_node("react_deployment", self.react_subgraph.get_compiled_graph())
|
| 127 |
+
|
| 128 |
+
# Set entry point
|
| 129 |
+
workflow.set_entry_point("extract_model_info")
|
| 130 |
+
|
| 131 |
+
# Add conditional edges - Decision point after model extraction
|
| 132 |
+
workflow.add_conditional_edges(
|
| 133 |
+
"extract_model_info",
|
| 134 |
+
self.should_validate_or_generate,
|
| 135 |
+
{
|
| 136 |
+
"generate_model_name": "generate_model_name",
|
| 137 |
+
"capacity_estimation": "capacity_estimation"
|
| 138 |
+
}
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
# Add conditional edges from capacity estimation to approval
|
| 142 |
+
workflow.add_conditional_edges(
|
| 143 |
+
"capacity_estimation",
|
| 144 |
+
self.should_continue_to_capacity_approval,
|
| 145 |
+
{
|
| 146 |
+
"capacity_approval": "capacity_approval",
|
| 147 |
+
"auto_capacity_approval": "auto_capacity_approval",
|
| 148 |
+
"end": END
|
| 149 |
+
}
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
# Add conditional edges from capacity approval
|
| 153 |
+
workflow.add_conditional_edges(
|
| 154 |
+
"capacity_approval",
|
| 155 |
+
self.should_continue_after_capacity_approval,
|
| 156 |
+
{
|
| 157 |
+
"react_deployment": "react_deployment",
|
| 158 |
+
"capacity_estimation": "capacity_estimation",
|
| 159 |
+
"end": END
|
| 160 |
+
}
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
# Auto approval always goes to deployment
|
| 164 |
+
workflow.add_edge("auto_capacity_approval", "react_deployment")
|
| 165 |
+
|
| 166 |
+
# Final edges
|
| 167 |
+
workflow.add_edge("generate_model_name", END)
|
| 168 |
+
workflow.add_edge("react_deployment", END)
|
| 169 |
+
|
| 170 |
+
# Compile
|
| 171 |
+
return workflow.compile()
|
| 172 |
+
|
| 173 |
+
def get_compiled_graph(self):
|
| 174 |
+
"""Return the compiled graph for embedding in parent graph"""
|
| 175 |
+
return self.graph
|
| 176 |
+
|
| 177 |
+
def should_validate_or_generate(self, state: Dict[str, Any]) -> str:
|
| 178 |
+
"""
|
| 179 |
+
Decision routing function after model extraction.
|
| 180 |
+
|
| 181 |
+
Path 1: If model found and valid → proceed to capacity estimation
|
| 182 |
+
Path 1A: If no model info or invalid → generate helpful response with suggestions
|
| 183 |
+
|
| 184 |
+
Args:
|
| 185 |
+
state: Current workflow state
|
| 186 |
+
|
| 187 |
+
Returns:
|
| 188 |
+
Next node name or END
|
| 189 |
+
"""
|
| 190 |
+
if state.get("model_name") and state.get("model_info") and not state.get("model_info", {}).get("error"):
|
| 191 |
+
return "capacity_estimation" # Path 1: Valid model case
|
| 192 |
+
else:
|
| 193 |
+
return "generate_model_name" # Path 1A: No info case
|
| 194 |
+
|
| 195 |
+
def should_continue_to_capacity_approval(self, state: Dict[str, Any]) -> str:
|
| 196 |
+
"""
|
| 197 |
+
Determine whether to proceed to human approval, auto-approval, or end.
|
| 198 |
+
|
| 199 |
+
This function controls the flow after capacity estimation based on HUMAN_APPROVAL_CAPACITY setting:
|
| 200 |
+
- If HUMAN_APPROVAL_CAPACITY is True: Route to capacity_approval for manual approval
|
| 201 |
+
- If HUMAN_APPROVAL_CAPACITY is False: Route to auto_capacity_approval for automatic approval
|
| 202 |
+
- If capacity estimation failed: Route to end
|
| 203 |
+
|
| 204 |
+
Args:
|
| 205 |
+
state: Current workflow state containing capacity estimation results
|
| 206 |
+
|
| 207 |
+
Returns:
|
| 208 |
+
Next node name: "capacity_approval", "auto_capacity_approval", or "end"
|
| 209 |
+
"""
|
| 210 |
+
# Check if capacity estimation was successful
|
| 211 |
+
if state.get("capacity_estimation_status") != "success":
|
| 212 |
+
logger.info("🔄 Capacity estimation failed - routing to end")
|
| 213 |
+
return "end"
|
| 214 |
+
|
| 215 |
+
# Check if human approval is enabled
|
| 216 |
+
HUMAN_APPROVAL_CAPACITY = True if Constants.HUMAN_APPROVAL_CAPACITY == "true" else False
|
| 217 |
+
if not HUMAN_APPROVAL_CAPACITY:
|
| 218 |
+
logger.info("🔄 HUMAN_APPROVAL_CAPACITY disabled - routing to auto-approval")
|
| 219 |
+
return "auto_capacity_approval"
|
| 220 |
+
else:
|
| 221 |
+
logger.info("🔄 HUMAN_APPROVAL_CAPACITY enabled - routing to human approval")
|
| 222 |
+
return "capacity_approval"
|
| 223 |
+
|
| 224 |
+
def should_continue_after_capacity_approval(self, state: Dict[str, Any]) -> str:
|
| 225 |
+
"""
|
| 226 |
+
Decide whether to proceed to ReAct deployment, re-estimate capacity, or end.
|
| 227 |
+
"""
|
| 228 |
+
logger.info(f"🔍 Routing after capacity approval:")
|
| 229 |
+
logger.info(f" - capacity_approved: {state.get('capacity_approved')}")
|
| 230 |
+
logger.info(f" - needs_re_estimation: {state.get('needs_re_estimation')}")
|
| 231 |
+
logger.info(f" - capacity_approval_status: {state.get('capacity_approval_status')}")
|
| 232 |
+
|
| 233 |
+
# 1. FIRST check for re-estimation (highest priority)
|
| 234 |
+
needs_re_estimation = state.get("needs_re_estimation")
|
| 235 |
+
if needs_re_estimation is True:
|
| 236 |
+
logger.info("🔄 Re-estimation requested - routing to capacity_estimation")
|
| 237 |
+
return "capacity_estimation"
|
| 238 |
+
|
| 239 |
+
# 2. THEN check if APPROVED (explicit True check)
|
| 240 |
+
capacity_approved = state.get("capacity_approved")
|
| 241 |
+
if capacity_approved is True:
|
| 242 |
+
logger.info("✅ Capacity approved - proceeding to react_deployment")
|
| 243 |
+
return "react_deployment"
|
| 244 |
+
|
| 245 |
+
# 3. Check if REJECTED (explicit False check)
|
| 246 |
+
if capacity_approved is False:
|
| 247 |
+
logger.info("❌ Capacity rejected - ending workflow")
|
| 248 |
+
return "end"
|
| 249 |
+
|
| 250 |
+
# 4. If capacity_approved is None and no re-estimation, something is wrong
|
| 251 |
+
logger.warning(f"⚠️ Unexpected state in capacity approval routing")
|
| 252 |
+
logger.warning(f" capacity_approved: {capacity_approved} (type: {type(capacity_approved)})")
|
| 253 |
+
logger.warning(f" needs_re_estimation: {needs_re_estimation} (type: {type(needs_re_estimation)})")
|
| 254 |
+
logger.warning(f" Full state keys: {list(state.keys())}")
|
| 255 |
+
|
| 256 |
+
# Default to end to prevent infinite loops
|
| 257 |
+
return "end"
|
| 258 |
+
|
| 259 |
+
async def ainvoke(self,
|
| 260 |
+
query: str,
|
| 261 |
+
user_id: str = "default_user",
|
| 262 |
+
session_id: str = "default_session",
|
| 263 |
+
enable_memory: bool = False,
|
| 264 |
+
config: Optional[Dict] = None) -> Dict[str, Any]:
|
| 265 |
+
"""
|
| 266 |
+
Asynchronously invoke the Deploy Model Agent workflow.
|
| 267 |
+
|
| 268 |
+
Args:
|
| 269 |
+
query: User's model deployment query
|
| 270 |
+
user_id: User identifier for memory management
|
| 271 |
+
session_id: Session identifier for memory management
|
| 272 |
+
enable_memory: Whether to enable conversation memory management
|
| 273 |
+
config: Optional config dict
|
| 274 |
+
|
| 275 |
+
Returns:
|
| 276 |
+
Final workflow state with deployment results
|
| 277 |
+
"""
|
| 278 |
+
# Initialize state with all required fields from AgentState
|
| 279 |
+
initial_state = {
|
| 280 |
+
# Core fields
|
| 281 |
+
"query": query,
|
| 282 |
+
"response": "",
|
| 283 |
+
"current_step": "initialized",
|
| 284 |
+
"messages": [],
|
| 285 |
+
|
| 286 |
+
# Decision fields
|
| 287 |
+
"agent_decision": "",
|
| 288 |
+
"deployment_approved": False,
|
| 289 |
+
|
| 290 |
+
# Model deployment fields
|
| 291 |
+
"model_name": "",
|
| 292 |
+
"llm": None,
|
| 293 |
+
"model_card": {},
|
| 294 |
+
"model_info": {},
|
| 295 |
+
"capacity_estimate": {},
|
| 296 |
+
"deployment_result": {},
|
| 297 |
+
|
| 298 |
+
# React agent fields
|
| 299 |
+
"react_results": {},
|
| 300 |
+
"tool_calls": [],
|
| 301 |
+
"tool_results": [],
|
| 302 |
+
}
|
| 303 |
+
|
| 304 |
+
# Extract approval from config if provided
|
| 305 |
+
if config and "configurable" in config:
|
| 306 |
+
if "capacity_approved" in config["configurable"]:
|
| 307 |
+
initial_state["deployment_approved"] = config["configurable"]["capacity_approved"]
|
| 308 |
+
logger.info(f"📋 DeployModelAgent received approval: {config['configurable']['capacity_approved']}")
|
| 309 |
+
|
| 310 |
+
# Configure memory if checkpointer is available
|
| 311 |
+
memory_config = None
|
| 312 |
+
if self.checkpointer:
|
| 313 |
+
thread_id = f"{user_id}:{session_id}"
|
| 314 |
+
memory_config = {"configurable": {"thread_id": thread_id}}
|
| 315 |
+
|
| 316 |
+
# Merge configs
|
| 317 |
+
final_config = memory_config or {}
|
| 318 |
+
if config:
|
| 319 |
+
if "configurable" in final_config:
|
| 320 |
+
final_config["configurable"].update(config.get("configurable", {}))
|
| 321 |
+
else:
|
| 322 |
+
final_config = config
|
| 323 |
+
|
| 324 |
+
logger.info(f"🚀 Starting Deploy Model workflow")
|
| 325 |
+
|
| 326 |
+
# Execute the graph
|
| 327 |
+
if final_config:
|
| 328 |
+
result = await self.graph.ainvoke(initial_state, final_config)
|
| 329 |
+
else:
|
| 330 |
+
result = await self.graph.ainvoke(initial_state)
|
| 331 |
+
|
| 332 |
+
return result
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
def invoke(self, query: str, user_id: str = "default_user", session_id: str = "default_session", enable_memory: bool = False) -> Dict[str, Any]:
|
| 336 |
+
"""
|
| 337 |
+
Synchronously invoke the Deploy Model Agent workflow.
|
| 338 |
+
|
| 339 |
+
Args:
|
| 340 |
+
query: User's model deployment query
|
| 341 |
+
user_id: User identifier for memory management
|
| 342 |
+
session_id: Session identifier for memory management
|
| 343 |
+
enable_memory: Whether to enable conversation memory management
|
| 344 |
+
|
| 345 |
+
Returns:
|
| 346 |
+
Final workflow state with deployment results
|
| 347 |
+
"""
|
| 348 |
+
import asyncio
|
| 349 |
+
return asyncio.run(self.ainvoke(query, user_id, session_id, enable_memory))
|
| 350 |
+
|
| 351 |
+
def draw_graph(self, output_file_path: str = "deploy_model_graph.png"):
|
| 352 |
+
"""
|
| 353 |
+
Generate and save a visual representation of the Deploy Model workflow graph.
|
| 354 |
+
|
| 355 |
+
Args:
|
| 356 |
+
output_file_path: Path where to save the graph PNG file
|
| 357 |
+
"""
|
| 358 |
+
try:
|
| 359 |
+
self.graph.get_graph().draw_mermaid_png(output_file_path=output_file_path)
|
| 360 |
+
logger.info(f"✅ Graph visualization saved to: {output_file_path}")
|
| 361 |
+
except Exception as e:
|
| 362 |
+
logger.error(f"❌ Failed to generate graph visualization: {e}")
|
| 363 |
+
print(f"Error generating graph: {e}")
|
ComputeAgent/graph/state.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, Any, List
|
| 2 |
+
from typing_extensions import TypedDict
|
| 3 |
+
|
| 4 |
+
class AgentState(TypedDict):
|
| 5 |
+
"""
|
| 6 |
+
AgentState extends HiveGPTMemoryState to provide a unified state structure for the Compute Agent workflow.
|
| 7 |
+
|
| 8 |
+
Inherits all memory-related fields and adds compute agent-specific workflow fields:
|
| 9 |
+
|
| 10 |
+
Core Fields:
|
| 11 |
+
- query: User's input query
|
| 12 |
+
- response: Final response to user
|
| 13 |
+
- current_step: Current workflow step identifier
|
| 14 |
+
|
| 15 |
+
Decision Fields:
|
| 16 |
+
- agent_decision: Routing decision ('deploy_model' or 'react_agent')
|
| 17 |
+
- deployment_approved: Whether human approved deployment
|
| 18 |
+
|
| 19 |
+
Model Deployment Fields:
|
| 20 |
+
- model_name: Name/ID of the model to deploy
|
| 21 |
+
- model_card: Raw model card data from HuggingFace
|
| 22 |
+
- model_info: Extracted model information (JSON)
|
| 23 |
+
- capacity_estimate: Estimated compute resources needed
|
| 24 |
+
- deployment_result: Result of model deployment
|
| 25 |
+
|
| 26 |
+
React Agent Fields:
|
| 27 |
+
- react_results: Results from React agent execution
|
| 28 |
+
- tool_calls: List of tool calls made by React agent
|
| 29 |
+
- tool_results: Results from tool executions
|
| 30 |
+
|
| 31 |
+
Error Handling:
|
| 32 |
+
- error: Error message if any step fails
|
| 33 |
+
- error_step: Step where error occurred
|
| 34 |
+
"""
|
| 35 |
+
# Core fields
|
| 36 |
+
query: str
|
| 37 |
+
response: str
|
| 38 |
+
current_step: str
|
| 39 |
+
messages: List[Dict[str, Any]]
|
| 40 |
+
|
| 41 |
+
# Decision fields
|
| 42 |
+
agent_decision: str
|
| 43 |
+
deployment_approved: bool
|
| 44 |
+
|
| 45 |
+
# Model deployment fields
|
| 46 |
+
model_name: str
|
| 47 |
+
model_card: Dict[str, Any]
|
| 48 |
+
model_info: Dict[str, Any]
|
| 49 |
+
capacity_estimate: Dict[str, Any]
|
| 50 |
+
deployment_result: Dict[str, Any]
|
| 51 |
+
capacity_estimation_status: str
|
| 52 |
+
capacity_approval_status: str
|
| 53 |
+
capacity_approved: bool
|
| 54 |
+
estimated_gpu_memory: float
|
| 55 |
+
gpu_requirements: Dict[str, Any]
|
| 56 |
+
cost_estimates: Dict[str, Any]
|
| 57 |
+
need_reestimation: bool
|
| 58 |
+
|
| 59 |
+
# React agent fields
|
| 60 |
+
react_results: Dict[str, Any]
|
| 61 |
+
tool_calls: List[Dict[str, Any]]
|
| 62 |
+
tool_results: List[Dict[str, Any]]
|
| 63 |
+
|
| 64 |
+
# Tool approval fields (for human-in-the-loop)
|
| 65 |
+
pending_tool_calls: List[Dict[str, Any]]
|
| 66 |
+
approved_tool_calls: List[Dict[str, Any]]
|
| 67 |
+
rejected_tool_calls: List[Dict[str, Any]]
|
| 68 |
+
modified_tool_calls: List[Dict[str, Any]]
|
| 69 |
+
needs_re_reasoning: bool
|
| 70 |
+
re_reasoning_feedback: str
|
| 71 |
+
|
| 72 |
+
# User identification
|
| 73 |
+
user_id: str
|
| 74 |
+
session_id: str
|
| 75 |
+
|
| 76 |
+
# Workflow identification (for tools registry lookup)
|
| 77 |
+
workflow_id: int
|
| 78 |
+
|
| 79 |
+
# Compute instance fields (for HiveCompute deployment)
|
| 80 |
+
instance_id: str
|
| 81 |
+
instance_status: str
|
| 82 |
+
instance_created: bool
|
| 83 |
+
|
| 84 |
+
|
ComputeAgent/hivenet.jpg
ADDED

|
ComputeAgent/main.py
ADDED
|
@@ -0,0 +1,284 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This allows importing modules from the top-level project directory
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
sys.path.append("/home/hivenet")
|
| 5 |
+
"""
|
| 6 |
+
ComputeAgent FastAPI Main Application
|
| 7 |
+
|
| 8 |
+
This is the main entry point for the ComputeAgent FastAPI application.
|
| 9 |
+
It creates the FastAPI app, includes routers, and manages the application lifecycle.
|
| 10 |
+
|
| 11 |
+
Features:
|
| 12 |
+
- FastAPI application setup
|
| 13 |
+
- Router inclusion for modular organization
|
| 14 |
+
- Application lifecycle management (startup/shutdown)
|
| 15 |
+
- CORS middleware configuration
|
| 16 |
+
- Global error handlers
|
| 17 |
+
- Background task management for memory operations
|
| 18 |
+
- Interactive API documentation
|
| 19 |
+
|
| 20 |
+
Usage:
|
| 21 |
+
python main.py
|
| 22 |
+
|
| 23 |
+
Or with uvicorn directly:
|
| 24 |
+
uvicorn main:app --host 0.0.0.0 --port 8000 --reload
|
| 25 |
+
|
| 26 |
+
Author: ComputeAgent Team
|
| 27 |
+
License: Private
|
| 28 |
+
"""
|
| 29 |
+
|
| 30 |
+
import asyncio
|
| 31 |
+
import logging
|
| 32 |
+
from contextlib import asynccontextmanager
|
| 33 |
+
|
| 34 |
+
from fastapi import FastAPI, Request
|
| 35 |
+
from fastapi.responses import JSONResponse, RedirectResponse
|
| 36 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 37 |
+
import uvicorn
|
| 38 |
+
|
| 39 |
+
# Import the compute agent router and initialization function
|
| 40 |
+
from routers.compute_agent_HITL import compute_agent_router, initialize_agent
|
| 41 |
+
|
| 42 |
+
# Initialize logging
|
| 43 |
+
logging.basicConfig(
|
| 44 |
+
level=logging.INFO,
|
| 45 |
+
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
|
| 46 |
+
)
|
| 47 |
+
logger = logging.getLogger("ComputeAgent Main")
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
@asynccontextmanager
|
| 51 |
+
async def lifespan(app: FastAPI):
|
| 52 |
+
"""
|
| 53 |
+
Lifespan context manager for FastAPI application.
|
| 54 |
+
Handles startup and shutdown events.
|
| 55 |
+
|
| 56 |
+
Args:
|
| 57 |
+
app: FastAPI application instance
|
| 58 |
+
"""
|
| 59 |
+
# Startup
|
| 60 |
+
logger.info("=" * 80)
|
| 61 |
+
logger.info("🚀 Starting ComputeAgent API Application...")
|
| 62 |
+
logger.info("=" * 80)
|
| 63 |
+
|
| 64 |
+
try:
|
| 65 |
+
# Initialize the ComputeAgent
|
| 66 |
+
await initialize_agent()
|
| 67 |
+
logger.info("✅ ComputeAgent API ready to serve requests")
|
| 68 |
+
|
| 69 |
+
except Exception as e:
|
| 70 |
+
logger.error(f"❌ Failed to initialize application: {e}")
|
| 71 |
+
raise
|
| 72 |
+
|
| 73 |
+
logger.info("=" * 80)
|
| 74 |
+
logger.info("📚 API Documentation available at:")
|
| 75 |
+
logger.info(" - Swagger UI: http://localhost:8000/docs")
|
| 76 |
+
logger.info(" - ReDoc: http://localhost:8000/redoc")
|
| 77 |
+
logger.info("=" * 80)
|
| 78 |
+
|
| 79 |
+
yield
|
| 80 |
+
|
| 81 |
+
# Shutdown
|
| 82 |
+
logger.info("=" * 80)
|
| 83 |
+
logger.info("👋 Shutting down ComputeAgent API Application...")
|
| 84 |
+
|
| 85 |
+
logger.info("✅ ComputeAgent API shutdown complete")
|
| 86 |
+
logger.info("=" * 80)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
# Create FastAPI application
|
| 90 |
+
app = FastAPI(
|
| 91 |
+
title="ComputeAgent API",
|
| 92 |
+
description="""
|
| 93 |
+
AI-powered agent system for model deployment and compute workflows.
|
| 94 |
+
|
| 95 |
+
## Features
|
| 96 |
+
|
| 97 |
+
* **Model Deployment**: Deploy AI models from HuggingFace with capacity estimation
|
| 98 |
+
* **React Agent**: Execute compute tasks with MCP tool integration
|
| 99 |
+
* **Memory Management**: Persistent conversations across sessions
|
| 100 |
+
* **Streaming Support**: Real-time updates via Server-Sent Events
|
| 101 |
+
* **Human-in-the-Loop**: Approval workflow for capacity decisions
|
| 102 |
+
|
| 103 |
+
## Endpoints
|
| 104 |
+
|
| 105 |
+
### ComputeAgent
|
| 106 |
+
- **POST /api/compute/query** - Process queries (non-streaming)
|
| 107 |
+
- **POST /api/compute/query/stream** - Process queries (streaming)
|
| 108 |
+
- **POST /api/compute/memory/clear** - Clear conversation memory
|
| 109 |
+
- **POST /api/compute/memory/inspect** - Inspect memory status
|
| 110 |
+
- **GET /api/compute/health** - Health check
|
| 111 |
+
- **GET /api/compute/examples** - Example queries
|
| 112 |
+
- **GET /api/compute/info** - Router information
|
| 113 |
+
|
| 114 |
+
## Getting Started
|
| 115 |
+
|
| 116 |
+
1. Check API health: `GET /api/compute/health`
|
| 117 |
+
2. Get example queries: `GET /api/compute/examples`
|
| 118 |
+
3. Process a query: `POST /api/compute/query`
|
| 119 |
+
|
| 120 |
+
For streaming responses, use: `POST /api/compute/query/stream`
|
| 121 |
+
""",
|
| 122 |
+
version="1.0.0",
|
| 123 |
+
lifespan=lifespan,
|
| 124 |
+
docs_url="/docs",
|
| 125 |
+
redoc_url="/redoc"
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
# Add CORS middleware
|
| 129 |
+
app.add_middleware(
|
| 130 |
+
CORSMiddleware,
|
| 131 |
+
allow_origins=["*"], # Configure appropriately for production
|
| 132 |
+
allow_credentials=True,
|
| 133 |
+
allow_methods=["*"],
|
| 134 |
+
allow_headers=["*"],
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
# Include routers
|
| 138 |
+
app.include_router(compute_agent_router)
|
| 139 |
+
|
| 140 |
+
# Root endpoint
|
| 141 |
+
@app.get("/", tags=["root"])
|
| 142 |
+
async def root():
|
| 143 |
+
"""
|
| 144 |
+
Root endpoint - redirects to API documentation.
|
| 145 |
+
|
| 146 |
+
Returns:
|
| 147 |
+
Redirect to Swagger UI documentation
|
| 148 |
+
"""
|
| 149 |
+
return RedirectResponse(url="/docs")
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
@app.get("/health", tags=["root"])
|
| 153 |
+
async def global_health_check():
|
| 154 |
+
"""
|
| 155 |
+
Global health check endpoint.
|
| 156 |
+
|
| 157 |
+
Returns:
|
| 158 |
+
Application health status
|
| 159 |
+
"""
|
| 160 |
+
return {
|
| 161 |
+
"status": "healthy",
|
| 162 |
+
"application": "ComputeAgent API",
|
| 163 |
+
"version": "1.0.0",
|
| 164 |
+
"docs": "/docs",
|
| 165 |
+
"compute_agent_health": "/api/compute/health"
|
| 166 |
+
}
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
# Global error handlers
|
| 170 |
+
@app.exception_handler(404)
|
| 171 |
+
async def not_found_handler(request: Request, exc: Exception):
|
| 172 |
+
"""
|
| 173 |
+
Custom 404 handler for not found endpoints.
|
| 174 |
+
|
| 175 |
+
Args:
|
| 176 |
+
request: The incoming request
|
| 177 |
+
exc: The exception raised
|
| 178 |
+
|
| 179 |
+
Returns:
|
| 180 |
+
JSON response with error details
|
| 181 |
+
"""
|
| 182 |
+
return JSONResponse(
|
| 183 |
+
status_code=404,
|
| 184 |
+
content={
|
| 185 |
+
"success": False,
|
| 186 |
+
"error": "Endpoint not found",
|
| 187 |
+
"path": str(request.url.path),
|
| 188 |
+
"message": "The requested endpoint does not exist. Visit /docs for available endpoints."
|
| 189 |
+
}
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
@app.exception_handler(500)
|
| 194 |
+
async def internal_error_handler(request: Request, exc: Exception):
|
| 195 |
+
"""
|
| 196 |
+
Custom 500 handler for internal server errors.
|
| 197 |
+
|
| 198 |
+
Args:
|
| 199 |
+
request: The incoming request
|
| 200 |
+
exc: The exception raised
|
| 201 |
+
|
| 202 |
+
Returns:
|
| 203 |
+
JSON response with error details
|
| 204 |
+
"""
|
| 205 |
+
logger.error(f"Internal server error on {request.url.path}: {exc}")
|
| 206 |
+
return JSONResponse(
|
| 207 |
+
status_code=500,
|
| 208 |
+
content={
|
| 209 |
+
"success": False,
|
| 210 |
+
"error": "Internal server error",
|
| 211 |
+
"detail": str(exc),
|
| 212 |
+
"message": "An unexpected error occurred. Please try again or contact support."
|
| 213 |
+
}
|
| 214 |
+
)
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
@app.exception_handler(Exception)
|
| 218 |
+
async def general_exception_handler(request: Request, exc: Exception):
|
| 219 |
+
"""
|
| 220 |
+
General exception handler for uncaught exceptions.
|
| 221 |
+
|
| 222 |
+
Args:
|
| 223 |
+
request: The incoming request
|
| 224 |
+
exc: The exception raised
|
| 225 |
+
|
| 226 |
+
Returns:
|
| 227 |
+
JSON response with error details
|
| 228 |
+
"""
|
| 229 |
+
logger.error(f"Unhandled exception on {request.url.path}: {exc}", exc_info=True)
|
| 230 |
+
return JSONResponse(
|
| 231 |
+
status_code=500,
|
| 232 |
+
content={
|
| 233 |
+
"success": False,
|
| 234 |
+
"error": "Unexpected error",
|
| 235 |
+
"detail": str(exc),
|
| 236 |
+
"message": "An unexpected error occurred. Please check logs for details."
|
| 237 |
+
}
|
| 238 |
+
)
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
# Middleware for logging
|
| 242 |
+
@app.middleware("http")
|
| 243 |
+
async def log_requests(request: Request, call_next):
|
| 244 |
+
"""
|
| 245 |
+
Middleware to log all incoming requests.
|
| 246 |
+
|
| 247 |
+
Args:
|
| 248 |
+
request: The incoming request
|
| 249 |
+
call_next: The next middleware or route handler
|
| 250 |
+
|
| 251 |
+
Returns:
|
| 252 |
+
Response from the route handler
|
| 253 |
+
"""
|
| 254 |
+
logger.info(f"📨 {request.method} {request.url.path}")
|
| 255 |
+
|
| 256 |
+
try:
|
| 257 |
+
response = await call_next(request)
|
| 258 |
+
logger.info(f"✅ {request.method} {request.url.path} - Status: {response.status_code}")
|
| 259 |
+
return response
|
| 260 |
+
except Exception as e:
|
| 261 |
+
logger.error(f"❌ {request.method} {request.url.path} - Error: {e}")
|
| 262 |
+
raise
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
if __name__ == "__main__":
|
| 266 |
+
"""
|
| 267 |
+
Run the FastAPI application with uvicorn.
|
| 268 |
+
|
| 269 |
+
Configuration:
|
| 270 |
+
- Host: 0.0.0.0 (accessible from network)
|
| 271 |
+
- Port: 8000
|
| 272 |
+
- Reload: Enabled for development
|
| 273 |
+
- Log level: info
|
| 274 |
+
"""
|
| 275 |
+
logger.info("🎬 Starting uvicorn server...")
|
| 276 |
+
|
| 277 |
+
uvicorn.run(
|
| 278 |
+
"main:app",
|
| 279 |
+
host="0.0.0.0",
|
| 280 |
+
port=8000,
|
| 281 |
+
reload=False,
|
| 282 |
+
log_level="info",
|
| 283 |
+
access_log=True
|
| 284 |
+
)
|
ComputeAgent/models/__init__.py
ADDED
|
File without changes
|
ComputeAgent/models/doc.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
from typing import List, Optional, Union
|
| 3 |
+
from pydantic import BaseModel, Field
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class SourceDocument(BaseModel):
|
| 7 |
+
filename: Optional[str] = Field(
|
| 8 |
+
None, alias="file_name", description="Name of the source document file"
|
| 9 |
+
)
|
| 10 |
+
title: Optional[str] = Field(
|
| 11 |
+
None, alias="title", description="Title of the source document"
|
| 12 |
+
)
|
| 13 |
+
type: Optional[str] = Field(
|
| 14 |
+
None,
|
| 15 |
+
alias="file_type",
|
| 16 |
+
description="Data source type of the source document (e.g., confluence, hiveDisk, slack, etc.).",
|
| 17 |
+
)
|
| 18 |
+
content: Optional[str] = Field(
|
| 19 |
+
None,
|
| 20 |
+
description="Relevant content in the source document used as a piece of context to generate the response.",
|
| 21 |
+
)
|
| 22 |
+
url: Optional[str] = Field(
|
| 23 |
+
None, alias="doc_url", description="Link to the source document, if available."
|
| 24 |
+
)
|
| 25 |
+
created_date: Optional[str] = Field(
|
| 26 |
+
None, description="Date when the source document was created."
|
| 27 |
+
)
|
| 28 |
+
created_by: Optional[str] = Field(
|
| 29 |
+
None, description="Author of the source document."
|
| 30 |
+
)
|
| 31 |
+
mongodb_link: Optional[Union[str, bool]] = Field(
|
| 32 |
+
None,
|
| 33 |
+
description="Unique identifier of the source document in the MongoDB. This will use to check whether there is an image in the MongoDB or not related to this document.",
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
model_config = {
|
| 37 |
+
"extra": "allow"
|
| 38 |
+
}
|
| 39 |
+
|
| 40 |
+
def __str__(self):
|
| 41 |
+
return (
|
| 42 |
+
f"SourceDocument(\n"
|
| 43 |
+
f" Title: {self.title or 'N/A'}\n"
|
| 44 |
+
f" Type: {self.type or 'N/A'}\n"
|
| 45 |
+
f" Author: {self.created_by or 'N/A'}\n"
|
| 46 |
+
f" Content: {self.content or 'N/A'}\n"
|
| 47 |
+
f" URL: {self.url or 'N/A'}\n"
|
| 48 |
+
f" Created Date: {self.created_date or 'N/A'}\n"
|
| 49 |
+
f" Updated Date: {self.updated_date or 'N/A'}\n"
|
| 50 |
+
f")"
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
class DocumentCollection(BaseModel):
|
| 55 |
+
list_of_doc: List[SourceDocument]
|
ComputeAgent/models/model_manager.py
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Model Manager Module
|
| 3 |
+
|
| 4 |
+
This module provides centralized management of AI models for the HiveGPT Agent
|
| 5 |
+
system. It handles loading, caching, and lifecycle management of both LLM and
|
| 6 |
+
reranking models with thread-safe operations.
|
| 7 |
+
|
| 8 |
+
The ModelManager class offers:
|
| 9 |
+
- Lazy loading and caching of language models
|
| 10 |
+
- Thread-safe model access with async locks
|
| 11 |
+
- Integration with ModelRouter for model discovery
|
| 12 |
+
- Memory-efficient model reuse across requests
|
| 13 |
+
|
| 14 |
+
Key Features:
|
| 15 |
+
- Singleton pattern for consistent model access
|
| 16 |
+
- Async/await support for non-blocking operations
|
| 17 |
+
- Automatic model caching to improve performance
|
| 18 |
+
- Error handling for model loading failures
|
| 19 |
+
|
| 20 |
+
Author: HiveNetCode
|
| 21 |
+
License: Private
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
import asyncio
|
| 25 |
+
from typing import Dict, Any, Optional
|
| 26 |
+
|
| 27 |
+
from langchain_openai import ChatOpenAI
|
| 28 |
+
|
| 29 |
+
from models.model_router import ModelRouter, LLMModel
|
| 30 |
+
from constant import Constants
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class ModelManager:
|
| 34 |
+
"""
|
| 35 |
+
Centralized manager for AI model loading, caching, and lifecycle management.
|
| 36 |
+
|
| 37 |
+
This class implements a thread-safe caching system for language models and
|
| 38 |
+
reranking models, providing efficient model reuse across the application.
|
| 39 |
+
It integrates with ModelRouter to discover available models and handles
|
| 40 |
+
the initialization and configuration of ChatOpenAI instances.
|
| 41 |
+
|
| 42 |
+
The ModelManager follows a singleton-like pattern where models are cached
|
| 43 |
+
at the class level to ensure memory efficiency and consistent model access
|
| 44 |
+
throughout the application lifecycle.
|
| 45 |
+
|
| 46 |
+
Attributes:
|
| 47 |
+
_llm_models: Cache of loaded language models
|
| 48 |
+
_reranker_models: Cache of loaded reranking models
|
| 49 |
+
_llm_lock: Async lock for thread-safe LLM loading
|
| 50 |
+
_reranker_lock: Async lock for thread-safe reranker loading
|
| 51 |
+
model_router: Interface to model discovery service
|
| 52 |
+
reranking_model_name: Name of the default reranking model
|
| 53 |
+
reranker: Cached reranking model instance
|
| 54 |
+
"""
|
| 55 |
+
|
| 56 |
+
def __init__(self):
|
| 57 |
+
"""
|
| 58 |
+
Initialize the ModelManager with empty caches and async locks.
|
| 59 |
+
|
| 60 |
+
Sets up the internal data structures for model caching and thread-safe
|
| 61 |
+
access. Initializes the ModelRouter for model discovery and sets the
|
| 62 |
+
default reranking model configuration.
|
| 63 |
+
"""
|
| 64 |
+
# Model caches for efficient reuse
|
| 65 |
+
self._llm_models: Dict[str, ChatOpenAI] = {}
|
| 66 |
+
|
| 67 |
+
# Thread safety locks for concurrent access
|
| 68 |
+
self._llm_lock = asyncio.Lock()
|
| 69 |
+
|
| 70 |
+
# Model discovery and configuration
|
| 71 |
+
self.model_router = ModelRouter()
|
| 72 |
+
|
| 73 |
+
async def load_llm_model(self, model_name: str) -> ChatOpenAI:
|
| 74 |
+
"""
|
| 75 |
+
Asynchronously loads and returns a language model for the specified model name.
|
| 76 |
+
|
| 77 |
+
This method checks if the model is already loaded and cached in the class-level
|
| 78 |
+
dictionary `_llm_models`. If not, it acquires a lock to ensure thread-safe
|
| 79 |
+
model loading, retrieves the model information from the Model Router, initializes
|
| 80 |
+
a `ChatOpenAI` instance with the given parameters, and caches it for future use.
|
| 81 |
+
|
| 82 |
+
Args:
|
| 83 |
+
model_name (str): The name of the language model to load.
|
| 84 |
+
|
| 85 |
+
Returns:
|
| 86 |
+
ChatOpenAI: An instance of the loaded language model.
|
| 87 |
+
"""
|
| 88 |
+
if model_name in self._llm_models:
|
| 89 |
+
return self._llm_models[model_name]
|
| 90 |
+
async with self._llm_lock:
|
| 91 |
+
if model_name not in self._llm_models:
|
| 92 |
+
loaded_model: LLMModel = self.model_router.get_llm_model(model_name)
|
| 93 |
+
llm = ChatOpenAI(
|
| 94 |
+
model_name=model_name,
|
| 95 |
+
api_key=Constants.MODEL_ROUTER_TOKEN,
|
| 96 |
+
base_url=loaded_model.openai_endpoint,
|
| 97 |
+
temperature=0.1,
|
| 98 |
+
)
|
| 99 |
+
self._llm_models[model_name] = llm
|
| 100 |
+
return self._llm_models[model_name]
|
ComputeAgent/models/model_router.py
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
import logging
|
| 3 |
+
from constant import Constants
|
| 4 |
+
import requests
|
| 5 |
+
from dataclasses import dataclass
|
| 6 |
+
from typing import Dict, List, Optional, Union
|
| 7 |
+
|
| 8 |
+
from collections import OrderedDict
|
| 9 |
+
|
| 10 |
+
logger = logging.getLogger("Reranker")
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@dataclass
|
| 14 |
+
class Model:
|
| 15 |
+
"""
|
| 16 |
+
Abstract base class representing a model served by the HiveGPT Model Router.
|
| 17 |
+
|
| 18 |
+
Attributes:
|
| 19 |
+
name (str): The HuggingFace repository path for the model, e.g., "meta-llama/Meta-Llama-3.1-8B".
|
| 20 |
+
alias (str): A shorter, more user-friendly alias or identifier for the model.
|
| 21 |
+
openai_endpoint (str): The base openai endpoint through which the model can be accessed.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
name: str
|
| 25 |
+
alias: str
|
| 26 |
+
openai_endpoint: str
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
@dataclass
|
| 30 |
+
class LLMModel(Model):
|
| 31 |
+
"""
|
| 32 |
+
Represents an LLM served by the HiveGPT Model Router.
|
| 33 |
+
|
| 34 |
+
Attributes:
|
| 35 |
+
name (str): The HuggingFace repository path for the model, e.g., "meta-llama/Meta-Llama-3.1-8B".
|
| 36 |
+
alias (str): A shorter, more user-friendly alias or identifier for the model.
|
| 37 |
+
openai_endpoint (str): The base openai endpoint through which the model can be accessed.
|
| 38 |
+
max_len (int): The maximum sequence length that the model can handle.
|
| 39 |
+
"""
|
| 40 |
+
|
| 41 |
+
max_len: int
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
class ModelRouter:
|
| 48 |
+
"""
|
| 49 |
+
A wrapper class that fetches info from the HiveGPT Model Router
|
| 50 |
+
"""
|
| 51 |
+
|
| 52 |
+
def __init__(self, host: str = Constants.MODEL_ROUTER_HOST, port: str = Constants.MODEL_ROUTER_PORT):
|
| 53 |
+
"""
|
| 54 |
+
Initializes the ModelRouter.
|
| 55 |
+
|
| 56 |
+
Args:
|
| 57 |
+
host (str): The hostname of the Model Router server.
|
| 58 |
+
port (int): The port number of the Model Router server.
|
| 59 |
+
|
| 60 |
+
Note: The ModelRouter will automatically refresh the map of served models upon initialization.
|
| 61 |
+
"""
|
| 62 |
+
self.host = host
|
| 63 |
+
self.port = port
|
| 64 |
+
self.models_health_endpoint = f"http://{self.host}:{self.port}/v1/models"
|
| 65 |
+
self.served_models: Dict[str, LLMModel] = {}
|
| 66 |
+
self.logger = logging.getLogger("HiveGPT Model Router")
|
| 67 |
+
self.refresh()
|
| 68 |
+
|
| 69 |
+
def _generate_openai_base(self, alias: str, base_endpoint: str = "/v1") -> str:
|
| 70 |
+
"""
|
| 71 |
+
Generates the base OpenAI endpoint URL for a given alias.
|
| 72 |
+
|
| 73 |
+
Args:
|
| 74 |
+
alias (str): The alias of the model.
|
| 75 |
+
base_endpoint (str): The base endpoint for the OpenAI API.
|
| 76 |
+
|
| 77 |
+
Returns:
|
| 78 |
+
str: The base OpenAI endpoint URL for the given alias.
|
| 79 |
+
"""
|
| 80 |
+
return f"http://{self.host}:{self.port}/{alias}{base_endpoint}"
|
| 81 |
+
|
| 82 |
+
def _sort_language_models(self):
|
| 83 |
+
"""
|
| 84 |
+
Sort returned models by alias in ascending order
|
| 85 |
+
and put the default LLM always on top.
|
| 86 |
+
"""
|
| 87 |
+
default_model_key = Constants.DEFAULT_LLM_NAME
|
| 88 |
+
|
| 89 |
+
# Get the default model
|
| 90 |
+
default_model = {default_model_key: self.served_models[default_model_key]} if default_model_key in self.served_models else None
|
| 91 |
+
|
| 92 |
+
# Sort remaining models in ascending order
|
| 93 |
+
other_models = {k: v for k, v in self.served_models.items() if k != default_model_key}
|
| 94 |
+
sorted_other_models = OrderedDict(sorted(other_models.items(), key=lambda item: item[0]))
|
| 95 |
+
|
| 96 |
+
# Combine the default model and the sorted models
|
| 97 |
+
sorted_llms = sorted_other_models
|
| 98 |
+
if default_model is not None:
|
| 99 |
+
sorted_llms = OrderedDict(**default_model, **sorted_other_models)
|
| 100 |
+
|
| 101 |
+
# Update the served_models dictionary
|
| 102 |
+
self.served_models = sorted_llms
|
| 103 |
+
|
| 104 |
+
def refresh(self):
|
| 105 |
+
"""Refreshes the map of served models."""
|
| 106 |
+
try:
|
| 107 |
+
response = requests.get(self.models_health_endpoint)
|
| 108 |
+
response.raise_for_status()
|
| 109 |
+
models_json = response.json()
|
| 110 |
+
|
| 111 |
+
models = {}
|
| 112 |
+
for model in models_json:
|
| 113 |
+
alias = model["model_alias"]
|
| 114 |
+
name = model["model_name"]
|
| 115 |
+
max_len = model["max_model_len"]
|
| 116 |
+
openai_endpoint = self._generate_openai_base(alias=alias)
|
| 117 |
+
models[name] = LLMModel(name=name, alias=alias, openai_endpoint=openai_endpoint, max_len=max_len)
|
| 118 |
+
|
| 119 |
+
self.served_models = models
|
| 120 |
+
self._sort_language_models()
|
| 121 |
+
self.logger.info("Models map successfully refreshed.")
|
| 122 |
+
|
| 123 |
+
except requests.RequestException as e:
|
| 124 |
+
self.logger.error(f"Failed to refresh models map: {e}")
|
| 125 |
+
self.served_models = {}
|
| 126 |
+
|
| 127 |
+
def get_llm_model(self, name: str) -> Optional[LLMModel]:
|
| 128 |
+
"""Gets the LLMModel object for the specified model name.
|
| 129 |
+
|
| 130 |
+
Args:
|
| 131 |
+
name (str): The HuggingFace repository path for the model. for example, "meta-llama/Meta-Llama-3.1-8B"
|
| 132 |
+
|
| 133 |
+
Returns:
|
| 134 |
+
Optional[Model]: The Model object.
|
| 135 |
+
Returns None if the model name is not found.
|
| 136 |
+
"""
|
| 137 |
+
return self.served_models.get(name)
|
| 138 |
+
|
| 139 |
+
def get_all_llm_models(self) -> Dict[str, LLMModel]:
|
| 140 |
+
"""Returns a map of all served LLMs.
|
| 141 |
+
|
| 142 |
+
Returns:
|
| 143 |
+
Dict[str, LLMModel]: A dictionary where keys are LLM names and values are LLMModel objects.
|
| 144 |
+
"""
|
| 145 |
+
self._sort_language_models()
|
| 146 |
+
return self.served_models
|
ComputeAgent/nodes/ReAct/__init__.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ReAct (Reasoning and Acting) Agent Implementation
|
| 3 |
+
|
| 4 |
+
This module implements the ReAct pattern for the HiveGPT agent system, providing
|
| 5 |
+
a human-in-the-loop workflow for intelligent tool selection and execution.
|
| 6 |
+
|
| 7 |
+
The ReAct pattern combines reasoning and acting in language models, allowing AI agents
|
| 8 |
+
to interleave thought, action, and observation steps to solve complex tasks effectively.
|
| 9 |
+
|
| 10 |
+
Key Components:
|
| 11 |
+
- Agent Reasoning: Two-phase approach for tool selection vs direct answers
|
| 12 |
+
- Human Approval: Interactive approval system for tool execution (optional based on HUMAN_APPROVAL setting)
|
| 13 |
+
- Tool Execution: Managed execution of approved tools with error handling
|
| 14 |
+
- Response Generation: Memory-aware response generation using retrieved data
|
| 15 |
+
- Response Refinement: LLM-based refinement for non-researcher tool results
|
| 16 |
+
- Decision Functions: Routing logic between workflow nodes
|
| 17 |
+
|
| 18 |
+
Features:
|
| 19 |
+
- Memory context integration for personalized responses
|
| 20 |
+
- Configurable human approval workflow (HUMAN_APPROVAL environment variable)
|
| 21 |
+
- Special handling for researcher tool with document retrieval
|
| 22 |
+
- Comprehensive error handling and fallback mechanisms
|
| 23 |
+
- Structured API response formatting with source attribution
|
| 24 |
+
- Extensive logging for debugging and monitoring
|
| 25 |
+
|
| 26 |
+
Environment Configuration:
|
| 27 |
+
HUMAN_APPROVAL: Set to "False" to automatically approve all tools and bypass
|
| 28 |
+
human approval step. Defaults to "True" for interactive approval.
|
| 29 |
+
|
| 30 |
+
Example:
|
| 31 |
+
>>> from nodes.ReAct import agent_reasoning_node
|
| 32 |
+
>>> state = {"messages": [...], "llm": model, "tools": tools}
|
| 33 |
+
>>> result = await agent_reasoning_node(state)
|
| 34 |
+
"""
|
| 35 |
+
|
| 36 |
+
from .agent_reasoning_node import agent_reasoning_node
|
| 37 |
+
from .human_approval_node import human_approval_node
|
| 38 |
+
from .auto_approval_node import auto_approval_node
|
| 39 |
+
from .tool_execution_node import tool_execution_node
|
| 40 |
+
from .generate_node import generate_node
|
| 41 |
+
from .tool_rejection_exit_node import tool_rejection_exit_node
|
| 42 |
+
from .decision_functions import (
|
| 43 |
+
should_continue_to_approval,
|
| 44 |
+
should_continue_after_approval,
|
| 45 |
+
should_continue_after_execution
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
__all__ = [
|
| 49 |
+
"agent_reasoning_node",
|
| 50 |
+
"human_approval_node",
|
| 51 |
+
"auto_approval_node",
|
| 52 |
+
"tool_execution_node",
|
| 53 |
+
"generate_node",
|
| 54 |
+
"tool_rejection_exit_node",
|
| 55 |
+
"should_continue_to_approval",
|
| 56 |
+
"should_continue_after_approval",
|
| 57 |
+
"should_continue_after_execution"
|
| 58 |
+
]
|
ComputeAgent/nodes/ReAct/agent_reasoning_node.py
ADDED
|
@@ -0,0 +1,399 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Agent Reasoning Node for ReAct Pattern - Enhanced Version
|
| 3 |
+
|
| 4 |
+
This module implements enhanced agent reasoning with support for:
|
| 5 |
+
1. Initial tool selection based on query
|
| 6 |
+
2. Re-reasoning after tool execution with results
|
| 7 |
+
3. Re-reasoning after user feedback/modifications
|
| 8 |
+
4. Memory context integration
|
| 9 |
+
|
| 10 |
+
Key Enhancements:
|
| 11 |
+
- User feedback integration for re-reasoning
|
| 12 |
+
- Modified tool context awareness
|
| 13 |
+
- Conversation history preservation
|
| 14 |
+
- Memory-enhanced reasoning
|
| 15 |
+
|
| 16 |
+
Author: ComputeAgent Team
|
| 17 |
+
"""
|
| 18 |
+
|
| 19 |
+
from typing import Dict, Any
|
| 20 |
+
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
|
| 21 |
+
from constant import Constants
|
| 22 |
+
import logging
|
| 23 |
+
|
| 24 |
+
logger = logging.getLogger("ReAct Agent Reasoning")
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
def _get_llm_from_registry(workflow_id: int):
|
| 28 |
+
"""
|
| 29 |
+
Get LLM from the global registry using workflow ID.
|
| 30 |
+
This avoids storing non-serializable LLM objects in state.
|
| 31 |
+
"""
|
| 32 |
+
from graph.graph_ReAct import _LLM_REGISTRY
|
| 33 |
+
llm = _LLM_REGISTRY.get(workflow_id)
|
| 34 |
+
if llm is None:
|
| 35 |
+
raise ValueError(f"LLM not found in registry for workflow_id: {workflow_id}")
|
| 36 |
+
return llm
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
async def agent_reasoning_node(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 40 |
+
"""
|
| 41 |
+
Enhanced agent reasoning node that handles initial reasoning and re-reasoning.
|
| 42 |
+
|
| 43 |
+
Supports three reasoning scenarios:
|
| 44 |
+
1. Initial reasoning: Fresh query, no prior tool executions
|
| 45 |
+
2. Post-execution reasoning: After tools executed, decide if more tools needed
|
| 46 |
+
3. Re-reasoning: After user feedback/modifications, reconsider approach
|
| 47 |
+
|
| 48 |
+
Special handling for deployment workflow:
|
| 49 |
+
- Detects when in deployment mode (capacity_approved=True)
|
| 50 |
+
- Provides specific instructions for calling create_compute_instance
|
| 51 |
+
- Passes deployment parameters from capacity estimation
|
| 52 |
+
|
| 53 |
+
Args:
|
| 54 |
+
state: Current ReAct state
|
| 55 |
+
|
| 56 |
+
Returns:
|
| 57 |
+
Updated state with tool calls or completion decision
|
| 58 |
+
"""
|
| 59 |
+
# Extract state information
|
| 60 |
+
query = state.get("query", "")
|
| 61 |
+
messages = state.get("messages", [])
|
| 62 |
+
tool_results = state.get("tool_results", [])
|
| 63 |
+
user_id = state.get("user_id", "")
|
| 64 |
+
session_id = state.get("session_id", "")
|
| 65 |
+
needs_re_reasoning = state.get("needs_re_reasoning", False)
|
| 66 |
+
re_reasoning_feedback = state.get("re_reasoning_feedback", "")
|
| 67 |
+
modified_tool_calls = state.get("modified_tool_calls", [])
|
| 68 |
+
|
| 69 |
+
# Extract deployment-specific information
|
| 70 |
+
capacity_approved = state.get("capacity_approved", False)
|
| 71 |
+
model_name = state.get("model_name", "")
|
| 72 |
+
model_info = state.get("model_info", {})
|
| 73 |
+
gpu_requirements = state.get("gpu_requirements", {})
|
| 74 |
+
estimated_gpu_memory = state.get("estimated_gpu_memory", 0)
|
| 75 |
+
|
| 76 |
+
# Get LLM from registry using workflow_id (avoids serialization issues)
|
| 77 |
+
workflow_id = state.get("workflow_id")
|
| 78 |
+
if not workflow_id:
|
| 79 |
+
logger.error("❌ No workflow_id in state - cannot retrieve LLM")
|
| 80 |
+
updated_state = state.copy()
|
| 81 |
+
updated_state["pending_tool_calls"] = []
|
| 82 |
+
updated_state["current_step"] = "agent_reasoning_error"
|
| 83 |
+
updated_state["error"] = "Missing workflow_id"
|
| 84 |
+
return updated_state
|
| 85 |
+
|
| 86 |
+
try:
|
| 87 |
+
llm = _get_llm_from_registry(workflow_id)
|
| 88 |
+
logger.info(f"✅ Retrieved LLM from registry")
|
| 89 |
+
except ValueError as e:
|
| 90 |
+
logger.error(f"❌ {e}")
|
| 91 |
+
updated_state = state.copy()
|
| 92 |
+
updated_state["pending_tool_calls"] = []
|
| 93 |
+
updated_state["current_step"] = "agent_reasoning_error"
|
| 94 |
+
updated_state["error"] = str(e)
|
| 95 |
+
return updated_state
|
| 96 |
+
|
| 97 |
+
# Determine reasoning scenario
|
| 98 |
+
if needs_re_reasoning:
|
| 99 |
+
logger.info("🔄 Re-reasoning mode: User requested reconsideration")
|
| 100 |
+
reasoning_mode = "re_reasoning"
|
| 101 |
+
elif tool_results:
|
| 102 |
+
logger.info("🔄 Post-execution mode: Evaluating if more tools needed")
|
| 103 |
+
reasoning_mode = "post_execution"
|
| 104 |
+
else:
|
| 105 |
+
logger.info("🎯 Initial reasoning mode: Processing fresh query")
|
| 106 |
+
reasoning_mode = "initial"
|
| 107 |
+
|
| 108 |
+
# Build memory context if available
|
| 109 |
+
memory_context = ""
|
| 110 |
+
if user_id and session_id:
|
| 111 |
+
try:
|
| 112 |
+
from helpers.memory import get_memory_manager
|
| 113 |
+
memory_manager = get_memory_manager()
|
| 114 |
+
memory_context = await memory_manager.build_context_for_node(
|
| 115 |
+
user_id,
|
| 116 |
+
session_id,
|
| 117 |
+
"agent_reasoning"
|
| 118 |
+
)
|
| 119 |
+
if memory_context:
|
| 120 |
+
logger.info("🧠 Using memory context for reasoning")
|
| 121 |
+
except Exception as e:
|
| 122 |
+
logger.warning(f"⚠️ Could not load memory context: {e}")
|
| 123 |
+
|
| 124 |
+
# Build reasoning prompt based on scenario
|
| 125 |
+
reasoning_prompt = _build_reasoning_prompt(
|
| 126 |
+
query=query,
|
| 127 |
+
reasoning_mode=reasoning_mode,
|
| 128 |
+
memory_context=memory_context,
|
| 129 |
+
tool_results=tool_results,
|
| 130 |
+
re_reasoning_feedback=re_reasoning_feedback,
|
| 131 |
+
modified_tool_calls=modified_tool_calls,
|
| 132 |
+
# Pass deployment context
|
| 133 |
+
capacity_approved=capacity_approved,
|
| 134 |
+
model_name=model_name,
|
| 135 |
+
model_info=model_info,
|
| 136 |
+
gpu_requirements=gpu_requirements,
|
| 137 |
+
estimated_gpu_memory=estimated_gpu_memory
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
# Prepare messages for LLM - ALWAYS include conversation history for context
|
| 141 |
+
if messages:
|
| 142 |
+
# Include conversation history so agent can reference previous responses
|
| 143 |
+
llm_messages = messages + [HumanMessage(content=reasoning_prompt)]
|
| 144 |
+
logger.info(f"📝 Including {len(messages)} previous messages for context")
|
| 145 |
+
else:
|
| 146 |
+
# First message in conversation
|
| 147 |
+
llm_messages = [HumanMessage(content=reasoning_prompt)]
|
| 148 |
+
logger.info("📝 Starting new conversation (no previous messages)")
|
| 149 |
+
|
| 150 |
+
logger.info(f"🤖 Invoking LLM for {reasoning_mode} reasoning...")
|
| 151 |
+
|
| 152 |
+
try:
|
| 153 |
+
# Invoke LLM with tools bound
|
| 154 |
+
response = await llm.ainvoke(llm_messages)
|
| 155 |
+
|
| 156 |
+
# Extract tool calls if any
|
| 157 |
+
tool_calls = []
|
| 158 |
+
if hasattr(response, 'tool_calls') and response.tool_calls:
|
| 159 |
+
tool_calls = [
|
| 160 |
+
{
|
| 161 |
+
"id": tc.get("id", f"call_{i}"),
|
| 162 |
+
"name": tc.get("name"),
|
| 163 |
+
"args": tc.get("args", {})
|
| 164 |
+
}
|
| 165 |
+
for i, tc in enumerate(response.tool_calls)
|
| 166 |
+
]
|
| 167 |
+
logger.info(f"🔧 Agent selected {len(tool_calls)} tool(s)")
|
| 168 |
+
else:
|
| 169 |
+
logger.info("✅ Agent decided no tools needed - ready to generate response")
|
| 170 |
+
|
| 171 |
+
# Update state
|
| 172 |
+
updated_state = state.copy()
|
| 173 |
+
updated_state["messages"] = llm_messages + [response]
|
| 174 |
+
updated_state["pending_tool_calls"] = tool_calls
|
| 175 |
+
updated_state["current_step"] = "agent_reasoning_complete"
|
| 176 |
+
|
| 177 |
+
# Clear re-reasoning flags after processing
|
| 178 |
+
if needs_re_reasoning:
|
| 179 |
+
updated_state["needs_re_reasoning"] = False
|
| 180 |
+
updated_state["re_reasoning_feedback"] = ""
|
| 181 |
+
logger.info("🔄 Re-reasoning complete, flags cleared")
|
| 182 |
+
|
| 183 |
+
# Clear modified tool calls after processing
|
| 184 |
+
if modified_tool_calls:
|
| 185 |
+
updated_state["modified_tool_calls"] = []
|
| 186 |
+
|
| 187 |
+
# NOTE: Don't remove tools here - they may be needed for next node
|
| 188 |
+
# Tools are only removed in terminal nodes (generate, tool_rejection_exit)
|
| 189 |
+
|
| 190 |
+
return updated_state
|
| 191 |
+
|
| 192 |
+
except Exception as e:
|
| 193 |
+
logger.error(f"❌ Error in agent reasoning: {e}")
|
| 194 |
+
|
| 195 |
+
# Fallback: set empty tool calls to proceed to generation
|
| 196 |
+
updated_state = state.copy()
|
| 197 |
+
updated_state["pending_tool_calls"] = []
|
| 198 |
+
updated_state["current_step"] = "agent_reasoning_error"
|
| 199 |
+
updated_state["error"] = str(e)
|
| 200 |
+
|
| 201 |
+
# NOTE: Don't remove tools here - they may be needed for next node
|
| 202 |
+
# Tools are only removed in terminal nodes (generate, tool_rejection_exit)
|
| 203 |
+
|
| 204 |
+
return updated_state
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def _build_reasoning_prompt(
|
| 208 |
+
query: str,
|
| 209 |
+
reasoning_mode: str,
|
| 210 |
+
memory_context: str,
|
| 211 |
+
tool_results: list,
|
| 212 |
+
re_reasoning_feedback: str,
|
| 213 |
+
modified_tool_calls: list,
|
| 214 |
+
capacity_approved: bool = False,
|
| 215 |
+
model_name: str = "",
|
| 216 |
+
model_info: dict = None,
|
| 217 |
+
gpu_requirements: dict = None,
|
| 218 |
+
estimated_gpu_memory: float = 0
|
| 219 |
+
) -> str:
|
| 220 |
+
"""
|
| 221 |
+
Build appropriate reasoning prompt based on the reasoning scenario.
|
| 222 |
+
|
| 223 |
+
Args:
|
| 224 |
+
query: Original user query
|
| 225 |
+
reasoning_mode: "initial", "post_execution", or "re_reasoning"
|
| 226 |
+
memory_context: Conversation memory context
|
| 227 |
+
tool_results: Previous tool execution results
|
| 228 |
+
re_reasoning_feedback: User's feedback for re-reasoning
|
| 229 |
+
modified_tool_calls: Tools that were modified by user
|
| 230 |
+
capacity_approved: Whether in deployment workflow with approved capacity
|
| 231 |
+
model_name: Name of model to deploy
|
| 232 |
+
model_info: Model information from capacity estimation
|
| 233 |
+
gpu_requirements: GPU requirements from capacity estimation
|
| 234 |
+
estimated_gpu_memory: Estimated GPU memory
|
| 235 |
+
|
| 236 |
+
Returns:
|
| 237 |
+
Formatted reasoning prompt
|
| 238 |
+
"""
|
| 239 |
+
base_prompt = Constants.GENERAL_SYSTEM_PROMPT
|
| 240 |
+
|
| 241 |
+
# Handle deployment workflow
|
| 242 |
+
if capacity_approved and reasoning_mode == "initial":
|
| 243 |
+
# Deployment-specific reasoning
|
| 244 |
+
if model_info is None:
|
| 245 |
+
model_info = {}
|
| 246 |
+
if gpu_requirements is None:
|
| 247 |
+
gpu_requirements = {}
|
| 248 |
+
|
| 249 |
+
# Get deployment parameters
|
| 250 |
+
location = model_info.get("location", "UAE-1")
|
| 251 |
+
gpu_type = model_info.get("GPU_type", "RTX 4090")
|
| 252 |
+
num_gpus = gpu_requirements.get(gpu_type, 1)
|
| 253 |
+
config = f"{num_gpus}x {gpu_type}"
|
| 254 |
+
|
| 255 |
+
deployment_instructions = f"""
|
| 256 |
+
🚀 **DEPLOYMENT MODE ACTIVATED** 🚀
|
| 257 |
+
|
| 258 |
+
You are in a model deployment workflow. The capacity has been approved and you need to create a compute instance.
|
| 259 |
+
|
| 260 |
+
**Deployment Information:**
|
| 261 |
+
- Model to deploy: {model_name}
|
| 262 |
+
- Approved Location: {location}
|
| 263 |
+
- Required GPU Configuration: {config}
|
| 264 |
+
- GPU Memory Required: {estimated_gpu_memory:.2f} GB
|
| 265 |
+
|
| 266 |
+
**YOUR TASK:**
|
| 267 |
+
Call the `create_compute_instance` tool with appropriate arguments based on the deployment information above.
|
| 268 |
+
|
| 269 |
+
**IMPORTANT:**
|
| 270 |
+
1. Review the tool's specification to understand the valid parameter values
|
| 271 |
+
2. Use the deployment information provided to determine the correct arguments:
|
| 272 |
+
- For the `name` parameter: Format the model name "{model_name}" following these rules:
|
| 273 |
+
* Convert to lowercase
|
| 274 |
+
* Replace forward slashes (/) with hyphens (-)
|
| 275 |
+
* Replace dots (.) with hyphens (-)
|
| 276 |
+
* Replace underscores (_) with hyphens (-)
|
| 277 |
+
* Keep existing hyphens as-is
|
| 278 |
+
- For the `location` parameter: Map the approved location to the tool's valid location format (see mapping below)
|
| 279 |
+
- For the `config` parameter: Use the exact GPU configuration "{config}"
|
| 280 |
+
3. After the tool returns the instance_id and status, do NOT call any other tools
|
| 281 |
+
4. The generate node will handle creating the deployment instructions
|
| 282 |
+
|
| 283 |
+
**Location Mapping (map approved location to MCP tool format):**
|
| 284 |
+
- "UAE-1" or "uae-1" or "UAE" → use "uae"
|
| 285 |
+
- "UAE-2" or "uae-2" → use "uae-2"
|
| 286 |
+
- "France" or "FRANCE" → use "france"
|
| 287 |
+
- "Texas" or "TEXAS" → use "texas"
|
| 288 |
+
|
| 289 |
+
**Example name formatting:**
|
| 290 |
+
- "meta-llama/Llama-3.1-8B" → "meta-llama-llama-3-1-8b"
|
| 291 |
+
- "Qwen/Qwen2.5-7B" → "qwen-qwen2-5-7b"
|
| 292 |
+
- "google/gemma-2-9b" → "google-gemma-2-9b"
|
| 293 |
+
|
| 294 |
+
Make sure your tool call arguments exactly match the MCP tool's specification format.
|
| 295 |
+
"""
|
| 296 |
+
|
| 297 |
+
prompt = f"""{base_prompt}
|
| 298 |
+
|
| 299 |
+
{deployment_instructions}
|
| 300 |
+
|
| 301 |
+
User Query: {query}
|
| 302 |
+
|
| 303 |
+
{f"Conversation Context: {memory_context}" if memory_context else ""}"""
|
| 304 |
+
|
| 305 |
+
return prompt
|
| 306 |
+
|
| 307 |
+
if reasoning_mode == "initial":
|
| 308 |
+
# Initial reasoning (non-deployment)
|
| 309 |
+
# Include available model information for tool calls
|
| 310 |
+
model_info_text = f"""
|
| 311 |
+
Available Models:
|
| 312 |
+
- For general queries: {Constants.DEFAULT_LLM_NAME}
|
| 313 |
+
- For function calling: {Constants.DEFAULT_LLM_FC}
|
| 314 |
+
|
| 315 |
+
When calling the research tool, use the model parameter: "{Constants.DEFAULT_LLM_NAME}"
|
| 316 |
+
"""
|
| 317 |
+
prompt = f"""{base_prompt}
|
| 318 |
+
|
| 319 |
+
{model_info_text}
|
| 320 |
+
|
| 321 |
+
User Query: {query}
|
| 322 |
+
|
| 323 |
+
{f"Conversation Context: {memory_context}" if memory_context else ""}
|
| 324 |
+
|
| 325 |
+
IMPORTANT INSTRUCTIONS:
|
| 326 |
+
1. **Check conversation history first**: If this is a follow-up question, review previous messages to see if you already have the information.
|
| 327 |
+
2. **Avoid redundant tool calls**: Don't call tools to fetch information you've already provided in this conversation.
|
| 328 |
+
3. **Answer directly when possible**: If you can answer based on previous responses or your knowledge, respond without calling tools.
|
| 329 |
+
4. **Use tools only when necessary**: Only call tools if you genuinely need new information that isn't available in the conversation history.
|
| 330 |
+
|
| 331 |
+
When calling tools that require a "model" parameter (like the research tool),
|
| 332 |
+
use the model "{Constants.DEFAULT_LLM_NAME}" unless the user explicitly requests a different model."""
|
| 333 |
+
|
| 334 |
+
elif reasoning_mode == "post_execution":
|
| 335 |
+
# Post-execution reasoning
|
| 336 |
+
tool_results_summary = "\n\n".join([
|
| 337 |
+
f"Tool {i+1} ({getattr(r, 'name', 'unknown')}): {getattr(r, 'content', str(r))}"
|
| 338 |
+
for i, r in enumerate(tool_results)
|
| 339 |
+
])
|
| 340 |
+
|
| 341 |
+
prompt = f"""{base_prompt}
|
| 342 |
+
|
| 343 |
+
Original Query: {query}
|
| 344 |
+
|
| 345 |
+
{f"Conversation Context: {memory_context}" if memory_context else ""}
|
| 346 |
+
|
| 347 |
+
Tool Execution Results:
|
| 348 |
+
{tool_results_summary}
|
| 349 |
+
|
| 350 |
+
IMPORTANT: Evaluate if you have enough information to answer the user's query.
|
| 351 |
+
|
| 352 |
+
Decision Logic:
|
| 353 |
+
1. If the tool results provide sufficient information to answer the query → DO NOT call any tools (respond without tool calls)
|
| 354 |
+
2. Only if critical information is still missing → Select specific tools to gather that information
|
| 355 |
+
|
| 356 |
+
Remember:
|
| 357 |
+
- The generate node will format your final response, so you don't need to call tools just to format data
|
| 358 |
+
- Be efficient - don't call tools unless absolutely necessary
|
| 359 |
+
- If you respond without calling tools, the workflow will move to generate the final answer"""
|
| 360 |
+
|
| 361 |
+
else: # re_reasoning
|
| 362 |
+
# Re-reasoning after user feedback
|
| 363 |
+
model_info = f"""
|
| 364 |
+
Available Models:
|
| 365 |
+
- For general queries: {Constants.DEFAULT_LLM_NAME}
|
| 366 |
+
- For function calling: {Constants.DEFAULT_LLM_FC}
|
| 367 |
+
|
| 368 |
+
When calling the research tool, use the model parameter: "{Constants.DEFAULT_LLM_NAME}"
|
| 369 |
+
"""
|
| 370 |
+
modified_summary = ""
|
| 371 |
+
if modified_tool_calls:
|
| 372 |
+
modified_summary = "\n\nUser Modified These Tools:\n" + "\n".join([
|
| 373 |
+
f"- Tool {mod['index']}: {mod['modified']['name']} with args {mod['modified']['args']}"
|
| 374 |
+
for mod in modified_tool_calls
|
| 375 |
+
])
|
| 376 |
+
|
| 377 |
+
prompt = f"""{base_prompt}
|
| 378 |
+
|
| 379 |
+
{model_info}
|
| 380 |
+
|
| 381 |
+
Original Query: {query}
|
| 382 |
+
|
| 383 |
+
{f"Conversation Context: {memory_context}" if memory_context else ""}
|
| 384 |
+
|
| 385 |
+
User Feedback: {re_reasoning_feedback}
|
| 386 |
+
|
| 387 |
+
{modified_summary}
|
| 388 |
+
|
| 389 |
+
The user has provided feedback on your previous tool selection. Please reconsider your approach:
|
| 390 |
+
1. Review the user's feedback carefully
|
| 391 |
+
2. Consider the modified tool arguments if provided
|
| 392 |
+
3. Determine a new strategy that addresses the user's concerns
|
| 393 |
+
|
| 394 |
+
Select appropriate tools based on this feedback, or proceed without tools if you can now answer directly.
|
| 395 |
+
|
| 396 |
+
IMPORTANT: When calling tools that require a "model" parameter (like the research tool),
|
| 397 |
+
use the model "{Constants.DEFAULT_LLM_NAME}" unless the user explicitly requests a different model."""
|
| 398 |
+
|
| 399 |
+
return prompt
|
ComputeAgent/nodes/ReAct/auto_approval_node.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Auto Approval Node for ReAct Pattern
|
| 3 |
+
|
| 4 |
+
This module implements automatic tool approval for the ReAct workflow when
|
| 5 |
+
human approval is disabled via the HUMAN_APPROVAL environment variable.
|
| 6 |
+
|
| 7 |
+
When HUMAN_APPROVAL is set to False, this node automatically approves all
|
| 8 |
+
pending tool calls without requiring user interaction, allowing for
|
| 9 |
+
fully automated tool execution in trusted environments.
|
| 10 |
+
|
| 11 |
+
Key Features:
|
| 12 |
+
- Automatic approval of all pending tool calls
|
| 13 |
+
- Consistent state management with human approval flow
|
| 14 |
+
- Comprehensive logging for audit trails
|
| 15 |
+
- Safety checks for empty pending lists
|
| 16 |
+
|
| 17 |
+
The auto approval process mirrors the human approval workflow but bypasses
|
| 18 |
+
user interaction, making it suitable for automated scenarios, testing,
|
| 19 |
+
or trusted environments where human oversight is not required.
|
| 20 |
+
|
| 21 |
+
State Updates:
|
| 22 |
+
After auto-approval, the state is updated with:
|
| 23 |
+
- approved_tool_calls: All pending tools moved to approved
|
| 24 |
+
- rejected_tool_calls: Empty list (no rejections in auto mode)
|
| 25 |
+
- pending_tool_calls: Cleared after approval process
|
| 26 |
+
|
| 27 |
+
Example:
|
| 28 |
+
>>> state = {
|
| 29 |
+
... "pending_tool_calls": [
|
| 30 |
+
... {"name": "research", "args": {"query": "AI trends"}}
|
| 31 |
+
... ]
|
| 32 |
+
... }
|
| 33 |
+
>>> result = await auto_approval_node(state)
|
| 34 |
+
>>> # All pending tools automatically approved
|
| 35 |
+
>>> print(state["approved_tool_calls"]) # Contains the research tool call
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
from typing import Dict, Any
|
| 39 |
+
import logging
|
| 40 |
+
|
| 41 |
+
logger = logging.getLogger("ReAct Auto Approval")
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
async def auto_approval_node(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 45 |
+
"""
|
| 46 |
+
Node that automatically approves all pending tool calls without user interaction.
|
| 47 |
+
|
| 48 |
+
This node is used when HUMAN_APPROVAL is disabled, providing a seamless
|
| 49 |
+
automated workflow while maintaining the same state structure as human approval.
|
| 50 |
+
|
| 51 |
+
Args:
|
| 52 |
+
state: Current ReAct state with pending tool calls
|
| 53 |
+
|
| 54 |
+
Returns:
|
| 55 |
+
Updated state with all pending tools moved to approved_tool_calls
|
| 56 |
+
"""
|
| 57 |
+
pending_tools = state.get("pending_tool_calls", [])
|
| 58 |
+
|
| 59 |
+
if not pending_tools:
|
| 60 |
+
logger.info("ℹ️ No pending tool calls for auto-approval")
|
| 61 |
+
return state
|
| 62 |
+
|
| 63 |
+
logger.info(f"🤖 Auto-approving {len(pending_tools)} tool call(s)")
|
| 64 |
+
|
| 65 |
+
# Log each tool being auto-approved for audit trail
|
| 66 |
+
for tool_call in pending_tools:
|
| 67 |
+
logger.info(f"✅ Auto-approved tool: '{tool_call['name']}' with args: {tool_call['args']}")
|
| 68 |
+
|
| 69 |
+
# Update state with auto-approval results
|
| 70 |
+
updated_state = state.copy()
|
| 71 |
+
updated_state["approved_tool_calls"] = pending_tools.copy() # Approve all pending tools
|
| 72 |
+
updated_state["rejected_tool_calls"] = [] # No rejections in auto mode
|
| 73 |
+
updated_state["pending_tool_calls"] = [] # Clear pending calls
|
| 74 |
+
updated_state["current_step"] = "auto_approval_complete"
|
| 75 |
+
|
| 76 |
+
# NOTE: Don't remove tools here - tool_execution needs them next
|
| 77 |
+
# Tools are only removed in terminal nodes (generate, tool_rejection_exit)
|
| 78 |
+
|
| 79 |
+
logger.info(f"📊 Auto-approval complete: {len(pending_tools)} tools approved, 0 rejected")
|
| 80 |
+
|
| 81 |
+
return updated_state
|
ComputeAgent/nodes/ReAct/decision_functions.py
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Decision Functions for ReAct Workflow Routing - Enhanced Version
|
| 3 |
+
|
| 4 |
+
This module contains enhanced routing logic for the ReAct workflow with support for
|
| 5 |
+
tool argument modification and re-reasoning capabilities.
|
| 6 |
+
|
| 7 |
+
Enhanced Features:
|
| 8 |
+
- Re-reasoning support when user modifies tool arguments
|
| 9 |
+
- Handles modified tool calls routing
|
| 10 |
+
- Backward compatible with existing routing logic
|
| 11 |
+
|
| 12 |
+
Functions:
|
| 13 |
+
should_continue_to_approval: Routes to human approval, direct tool execution, or refinement
|
| 14 |
+
should_continue_after_approval: Routes to execution, rejection handling, or re-reasoning
|
| 15 |
+
should_continue_after_execution: Routes based on tool execution results
|
| 16 |
+
|
| 17 |
+
New Routing Paths:
|
| 18 |
+
- Re-reasoning: When user requests changes and wants agent to reconsider
|
| 19 |
+
- Modified execution: When user modifies tool arguments but wants to proceed
|
| 20 |
+
|
| 21 |
+
Environment Variables:
|
| 22 |
+
HUMAN_APPROVAL: When set to "False", automatically approves all tools and
|
| 23 |
+
bypasses the human approval step. Defaults to "True".
|
| 24 |
+
|
| 25 |
+
Example:
|
| 26 |
+
>>> # User modifies tool arguments
|
| 27 |
+
>>> state = {"needs_re_reasoning": True, "re_reasoning_feedback": "..."}
|
| 28 |
+
>>> next_node = should_continue_after_approval(state)
|
| 29 |
+
>>> # Returns "agent_reasoning" to re-evaluate
|
| 30 |
+
"""
|
| 31 |
+
|
| 32 |
+
from typing import Dict, Any, Literal
|
| 33 |
+
import logging
|
| 34 |
+
from constant import Constants
|
| 35 |
+
|
| 36 |
+
logger = logging.getLogger("ReAct Decision Functions")
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def should_continue_to_approval(state: Dict[str, Any]) -> str:
|
| 40 |
+
"""
|
| 41 |
+
Determine whether to proceed to human approval, auto-approval, or generate.
|
| 42 |
+
|
| 43 |
+
This function controls the flow after agent reasoning based on HUMAN_APPROVAL setting:
|
| 44 |
+
- If HUMAN_APPROVAL is True: Route to human_approval for manual approval
|
| 45 |
+
- If HUMAN_APPROVAL is False: Route to auto_approval for automatic approval
|
| 46 |
+
- If no tools selected: Route directly to generate (CHANGED from refinement)
|
| 47 |
+
- If force_generate is set: Route directly to generate
|
| 48 |
+
|
| 49 |
+
Args:
|
| 50 |
+
state: Current workflow state containing pending tool calls
|
| 51 |
+
|
| 52 |
+
Returns:
|
| 53 |
+
Next node name: "human_approval", "auto_approval", or "generate"
|
| 54 |
+
"""
|
| 55 |
+
# Check if generate is forced (e.g., due to max iterations)
|
| 56 |
+
if state.get("force_refinement", False): # Keep the flag name for backward compatibility
|
| 57 |
+
logger.info("📄 Force refinement flag set - routing to generate")
|
| 58 |
+
return "generate"
|
| 59 |
+
|
| 60 |
+
pending_tools = state.get("pending_tool_calls", [])
|
| 61 |
+
|
| 62 |
+
if not pending_tools:
|
| 63 |
+
logger.info("📄 No tools selected - routing to generate")
|
| 64 |
+
return "generate"
|
| 65 |
+
|
| 66 |
+
# Check if human approval is enabled
|
| 67 |
+
HUMAN_APPROVAL = True if Constants.HUMAN_APPROVAL == "true" else False
|
| 68 |
+
if not HUMAN_APPROVAL:
|
| 69 |
+
logger.info(f"📄 HUMAN_APPROVAL disabled - routing to auto-approval for {len(pending_tools)} tool call(s)")
|
| 70 |
+
return "auto_approval"
|
| 71 |
+
else:
|
| 72 |
+
logger.info(f"📄 HUMAN_APPROVAL enabled - routing to human approval for {len(pending_tools)} tool call(s)")
|
| 73 |
+
return "human_approval"
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def should_continue_after_approval(state: Dict[str, Any]) -> Literal["tool_execution", "tool_rejection_exit", "agent_reasoning"]:
|
| 77 |
+
"""
|
| 78 |
+
Decide whether to execute tools, exit due to rejection, or re-reason.
|
| 79 |
+
|
| 80 |
+
Enhanced to support:
|
| 81 |
+
1. Execute approved tools (approved_tool_calls)
|
| 82 |
+
2. Exit if all rejected (no approved tools)
|
| 83 |
+
3. Re-reason if user requests it (needs_re_reasoning)
|
| 84 |
+
|
| 85 |
+
Args:
|
| 86 |
+
state: Current ReAct state after human approval
|
| 87 |
+
|
| 88 |
+
Returns:
|
| 89 |
+
Next node name: "tool_execution", "tool_rejection_exit", or "agent_reasoning"
|
| 90 |
+
"""
|
| 91 |
+
approved_calls = state.get("approved_tool_calls", [])
|
| 92 |
+
needs_re_reasoning = state.get("needs_re_reasoning", False)
|
| 93 |
+
|
| 94 |
+
# PRIORITY 1: Check if re-reasoning is requested
|
| 95 |
+
if needs_re_reasoning:
|
| 96 |
+
logger.info("🔄 Re-reasoning requested - routing back to agent_reasoning")
|
| 97 |
+
return "agent_reasoning"
|
| 98 |
+
|
| 99 |
+
# PRIORITY 2: Check if there are approved tools to execute
|
| 100 |
+
if approved_calls:
|
| 101 |
+
logger.info(f"📄 Routing to tool execution for {len(approved_calls)} approved tool(s)")
|
| 102 |
+
return "tool_execution"
|
| 103 |
+
|
| 104 |
+
# PRIORITY 3: No approved tools and no re-reasoning means rejection
|
| 105 |
+
logger.info("📄 No approved tools (rejected) - routing to tool rejection exit")
|
| 106 |
+
return "tool_rejection_exit"
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def should_continue_after_execution(state: Dict[str, Any]) -> Literal["agent_reasoning", "generate"]:
|
| 110 |
+
"""
|
| 111 |
+
Decide where to go after tool execution.
|
| 112 |
+
|
| 113 |
+
Strategy: ALWAYS route to agent_reasoning after tool execution.
|
| 114 |
+
Let the agent evaluate the results and intelligently decide whether to:
|
| 115 |
+
- Generate final response (no tools needed)
|
| 116 |
+
- Call additional tools (more information needed)
|
| 117 |
+
|
| 118 |
+
This gives the agent full control to decide based on the quality and
|
| 119 |
+
completeness of the tool results, regardless of which tools were used.
|
| 120 |
+
|
| 121 |
+
Args:
|
| 122 |
+
state: Current ReAct state after tool execution
|
| 123 |
+
|
| 124 |
+
Returns:
|
| 125 |
+
Next node name (always "agent_reasoning")
|
| 126 |
+
"""
|
| 127 |
+
tool_results = state.get("tool_results", [])
|
| 128 |
+
|
| 129 |
+
if tool_results:
|
| 130 |
+
logger.info(f"📄 Tool execution complete ({len(tool_results)} results) - routing to agent reasoning for evaluation")
|
| 131 |
+
return "agent_reasoning"
|
| 132 |
+
|
| 133 |
+
# No tool results - this shouldn't happen but fallback to generate
|
| 134 |
+
logger.warning("⚠️ No tool results after execution - falling back to generate")
|
| 135 |
+
return "generate"
|
ComputeAgent/nodes/ReAct/generate_node.py
ADDED
|
@@ -0,0 +1,510 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ReAct Generate Node - Simplified version with 3 clear paths
|
| 3 |
+
|
| 4 |
+
Node that generates final response using:
|
| 5 |
+
1. DirectAnswerChain for direct answers (no tools)
|
| 6 |
+
2. ResearcherChain for researcher tool results
|
| 7 |
+
3. ToolResultChain for other tool results
|
| 8 |
+
|
| 9 |
+
All chains provide consistent formatting and professional presentation with memory context support.
|
| 10 |
+
Independent implementation for ReAct workflow - no dependency on AgenticRAG.
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
from typing import Dict, Any
|
| 14 |
+
from chains.tool_result_chain import ToolResultChain
|
| 15 |
+
from models.model_manager import ModelManager
|
| 16 |
+
from constant import Constants
|
| 17 |
+
import asyncio
|
| 18 |
+
import logging
|
| 19 |
+
import json
|
| 20 |
+
from langgraph.config import get_stream_writer
|
| 21 |
+
from langchain_core.messages import HumanMessage, SystemMessage
|
| 22 |
+
|
| 23 |
+
# Initialize model manager for LLM loading
|
| 24 |
+
model_manager = ModelManager()
|
| 25 |
+
|
| 26 |
+
# Initialize logger for generate node
|
| 27 |
+
logger = logging.getLogger("ReAct Generate Node")
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def _create_error_response(state: Dict[str, Any], query: str, error_msg: str) -> Dict[str, Any]:
|
| 31 |
+
"""Create a standardized error response"""
|
| 32 |
+
final_response_dict = {
|
| 33 |
+
"query": query,
|
| 34 |
+
"final_response": f"I apologize, but I encountered an error: {error_msg}",
|
| 35 |
+
"sources": []
|
| 36 |
+
}
|
| 37 |
+
|
| 38 |
+
updated_state = state.copy()
|
| 39 |
+
updated_state["response"] = final_response_dict["final_response"]
|
| 40 |
+
updated_state["final_response_dict"] = final_response_dict
|
| 41 |
+
updated_state["current_step"] = "generate_complete"
|
| 42 |
+
|
| 43 |
+
# Send it via custom stream
|
| 44 |
+
writer = get_stream_writer()
|
| 45 |
+
writer({"final_response_dict": final_response_dict})
|
| 46 |
+
|
| 47 |
+
return updated_state
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
async def _generate_deployment_instructions(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 51 |
+
"""
|
| 52 |
+
Generate deployment instructions when instance has been created.
|
| 53 |
+
|
| 54 |
+
Args:
|
| 55 |
+
state: Current state with instance_id and deployment info
|
| 56 |
+
|
| 57 |
+
Returns:
|
| 58 |
+
Updated state with deployment instructions
|
| 59 |
+
"""
|
| 60 |
+
logger.info("📝 Generating deployment instructions")
|
| 61 |
+
|
| 62 |
+
# Extract deployment information
|
| 63 |
+
instance_id = state.get("instance_id", "")
|
| 64 |
+
instance_status = state.get("instance_status", "")
|
| 65 |
+
model_name = state.get("model_name", "Unknown Model")
|
| 66 |
+
model_info = state.get("model_info", {})
|
| 67 |
+
gpu_requirements = state.get("gpu_requirements", {})
|
| 68 |
+
estimated_gpu_memory = state.get("estimated_gpu_memory", 0)
|
| 69 |
+
|
| 70 |
+
# Get deployment configuration
|
| 71 |
+
location = model_info.get("location", "UAE-1")
|
| 72 |
+
gpu_type = model_info.get("GPU_type", "RTX 4090")
|
| 73 |
+
num_gpus = gpu_requirements.get(gpu_type, 1)
|
| 74 |
+
config = f"{num_gpus}x {gpu_type}"
|
| 75 |
+
|
| 76 |
+
# Determine capacity source
|
| 77 |
+
custom_capacity = state.get("custom_capacity", {})
|
| 78 |
+
capacity_source = "custom" if custom_capacity else "estimated"
|
| 79 |
+
|
| 80 |
+
# Build SSH command
|
| 81 |
+
ssh_command = f'ssh -i ~/.ssh/id_rsa -o "ProxyCommand=ssh bastion@ssh.hivecompute.ai %h" ubuntu@{instance_id}.ssh.hivecompute.ai'
|
| 82 |
+
|
| 83 |
+
# Get capacity estimation parameters
|
| 84 |
+
max_model_len = model_info.get("max_model_len", 2048)
|
| 85 |
+
max_num_seqs = model_info.get("max_num_seqs", 256)
|
| 86 |
+
max_batched_tokens = model_info.get("max_num_batched_tokens", 2048)
|
| 87 |
+
dtype = model_info.get("dtype", "BF16")
|
| 88 |
+
kv_cache_dtype = model_info.get("kv_cache_dtype", "auto")
|
| 89 |
+
gpu_memory_utilization = model_info.get("gpu_memory_utilization", 0.9)
|
| 90 |
+
|
| 91 |
+
# Use LLM to generate optimal vLLM command based on documentation and specs
|
| 92 |
+
logger.info("🤖 Using LLM to determine optimal vLLM parameters")
|
| 93 |
+
|
| 94 |
+
# Import vLLM documentation
|
| 95 |
+
try:
|
| 96 |
+
from vllm_engine_args import get_vllm_docs
|
| 97 |
+
vllm_docs = get_vllm_docs()
|
| 98 |
+
except ImportError:
|
| 99 |
+
logger.warning("⚠️ Could not import vllm_engine_args, using basic documentation")
|
| 100 |
+
vllm_docs = "Basic vLLM parameters: --model, --dtype, --max-model-len, --gpu-memory-utilization, --tensor-parallel-size, --enable-prefix-caching, --enable-chunked-prefill"
|
| 101 |
+
|
| 102 |
+
vllm_params_prompt = f"""You are an expert in vLLM deployment. Based on the model specifications and capacity estimation, generate an optimal vLLM serve command.
|
| 103 |
+
|
| 104 |
+
**Model Information:**
|
| 105 |
+
- Model: {model_name}
|
| 106 |
+
- GPU Type: {gpu_type}
|
| 107 |
+
- Number of GPUs: {num_gpus}
|
| 108 |
+
- GPU Memory: {estimated_gpu_memory:.2f} GB
|
| 109 |
+
- Location: {location}
|
| 110 |
+
|
| 111 |
+
**Capacity Estimation Parameters:**
|
| 112 |
+
- Max Model Length: {max_model_len}
|
| 113 |
+
- Max Sequences: {max_num_seqs}
|
| 114 |
+
- Max Batched Tokens: {max_batched_tokens}
|
| 115 |
+
- Data Type: {dtype}
|
| 116 |
+
- KV Cache dtype: {kv_cache_dtype}
|
| 117 |
+
- GPU Memory Utilization: {gpu_memory_utilization}
|
| 118 |
+
|
| 119 |
+
**vLLM Engine Arguments Documentation:**
|
| 120 |
+
{vllm_docs}
|
| 121 |
+
|
| 122 |
+
**Task:**
|
| 123 |
+
Generate the optimal vLLM serve command for this deployment. Consider:
|
| 124 |
+
1. Use the capacity estimation parameters provided
|
| 125 |
+
2. For multi-GPU setups ({num_gpus} GPUs), add --tensor-parallel-size {num_gpus} if num_gpus > 1
|
| 126 |
+
3. Add --enable-chunked-prefill if max_model_len > 8192 for better long context handling
|
| 127 |
+
4. Use --quantization fp8 only if dtype contains 'fp8' or 'FP8'
|
| 128 |
+
5. Always include --enable-prefix-caching for better performance
|
| 129 |
+
6. Set --host 0.0.0.0 and --port 8888
|
| 130 |
+
7. Use --download-dir /home/ubuntu/workspace/models
|
| 131 |
+
8. Consider other relevant parameters from the documentation based on the model and hardware specs
|
| 132 |
+
|
| 133 |
+
Return ONLY the complete vLLM command without any explanation, starting with 'vllm serve'."""
|
| 134 |
+
|
| 135 |
+
try:
|
| 136 |
+
from langchain_openai import ChatOpenAI
|
| 137 |
+
from constant import Constants
|
| 138 |
+
|
| 139 |
+
llm = ChatOpenAI(
|
| 140 |
+
base_url=Constants.LLM_BASE_URL,
|
| 141 |
+
api_key=Constants.LLM_API_KEY,
|
| 142 |
+
model=Constants.DEFAULT_LLM_NAME,
|
| 143 |
+
temperature=0.0
|
| 144 |
+
)
|
| 145 |
+
|
| 146 |
+
vllm_response = await llm.ainvoke(vllm_params_prompt)
|
| 147 |
+
vllm_command = vllm_response.content.strip()
|
| 148 |
+
|
| 149 |
+
logger.info(f"✅ Generated vLLM command: {vllm_command}")
|
| 150 |
+
|
| 151 |
+
except Exception as e:
|
| 152 |
+
logger.error(f"❌ Failed to generate vLLM command with LLM: {e}")
|
| 153 |
+
# Fallback to basic command
|
| 154 |
+
quantization = "fp8" if "fp8" in dtype.lower() else None
|
| 155 |
+
vllm_command = f'vllm serve {model_name} --download-dir /home/ubuntu/workspace/models --gpu-memory-utilization {gpu_memory_utilization} --max-model-len {max_model_len} --max-num-seqs {max_num_seqs} --max-num-batched-tokens {max_batched_tokens} --dtype {dtype}'
|
| 156 |
+
if quantization:
|
| 157 |
+
vllm_command += f' --quantization {quantization}'
|
| 158 |
+
if num_gpus > 1:
|
| 159 |
+
vllm_command += f' --tensor-parallel-size {num_gpus}'
|
| 160 |
+
vllm_command += f' --kv-cache-dtype {kv_cache_dtype} --enable-prefix-caching --host 0.0.0.0 --port 8888'
|
| 161 |
+
|
| 162 |
+
# Build curl test command
|
| 163 |
+
curl_command = f'''curl -k https://{instance_id}-8888.tenants.hivecompute.ai/v1/chat/completions \\
|
| 164 |
+
-H "Content-Type: application/json" \\
|
| 165 |
+
-d '{{
|
| 166 |
+
"model": "{model_name}",
|
| 167 |
+
"messages": [
|
| 168 |
+
{{"role": "user", "content": "What is the capital of France?"}}
|
| 169 |
+
],
|
| 170 |
+
"max_tokens": 512
|
| 171 |
+
}}' '''
|
| 172 |
+
|
| 173 |
+
# Build complete deployment instructions response
|
| 174 |
+
final_response = f"""
|
| 175 |
+
# 🚀 Deployment Instructions for {model_name}
|
| 176 |
+
|
| 177 |
+
## ✅ Instance Created Successfully
|
| 178 |
+
|
| 179 |
+
**Instance ID:** `{instance_id}`
|
| 180 |
+
**Status:** `{instance_status}`
|
| 181 |
+
**Location:** `{location}`
|
| 182 |
+
**Configuration:** `{config}`
|
| 183 |
+
|
| 184 |
+
---
|
| 185 |
+
|
| 186 |
+
## 📊 Capacity Configuration
|
| 187 |
+
|
| 188 |
+
- **GPU Memory Required:** {estimated_gpu_memory:.2f} GB
|
| 189 |
+
- **GPU Type:** {gpu_type}
|
| 190 |
+
- **Number of GPUs:** {num_gpus}
|
| 191 |
+
- **Capacity Source:** {capacity_source}
|
| 192 |
+
|
| 193 |
+
---
|
| 194 |
+
|
| 195 |
+
## 🔐 Step 1: SSH to the Instance
|
| 196 |
+
|
| 197 |
+
```bash
|
| 198 |
+
{ssh_command}
|
| 199 |
+
```
|
| 200 |
+
|
| 201 |
+
---
|
| 202 |
+
|
| 203 |
+
## 📁 Step 2: Create Models Directory
|
| 204 |
+
|
| 205 |
+
Once connected via SSH, create the models directory inside the workspace:
|
| 206 |
+
|
| 207 |
+
```bash
|
| 208 |
+
mkdir -p /home/ubuntu/workspace/models
|
| 209 |
+
mkdir -p /home/ubuntu/workspace/tmpdir
|
| 210 |
+
```
|
| 211 |
+
|
| 212 |
+
**Note:** Cannot use docker file in HiveCompute since there is no VM support. Use an instance from HiveCompute with Template with Pytorch.
|
| 213 |
+
|
| 214 |
+
---
|
| 215 |
+
|
| 216 |
+
## 📦 Step 3: Install Dependencies (Using UV)
|
| 217 |
+
|
| 218 |
+
Install UV package manager:
|
| 219 |
+
|
| 220 |
+
```bash
|
| 221 |
+
curl -LsSf https://astral.sh/uv/install.sh | sh
|
| 222 |
+
source $HOME/.local/bin/env
|
| 223 |
+
```
|
| 224 |
+
|
| 225 |
+
Create and activate environment:
|
| 226 |
+
|
| 227 |
+
```bash
|
| 228 |
+
uv venv --python 3.12
|
| 229 |
+
source .venv/bin/activate
|
| 230 |
+
```
|
| 231 |
+
|
| 232 |
+
Install vLLM and dependencies:
|
| 233 |
+
|
| 234 |
+
```bash
|
| 235 |
+
uv pip install vllm==0.11.0 ray[default]
|
| 236 |
+
```
|
| 237 |
+
|
| 238 |
+
---
|
| 239 |
+
|
| 240 |
+
## 🤖 Step 4: Start vLLM Server
|
| 241 |
+
|
| 242 |
+
Run the vLLM server with the following configuration:
|
| 243 |
+
|
| 244 |
+
```bash
|
| 245 |
+
{vllm_command}
|
| 246 |
+
```
|
| 247 |
+
|
| 248 |
+
**Configuration Details:**
|
| 249 |
+
The vLLM command above was intelligently generated based on:
|
| 250 |
+
- **Model Specifications:** {model_name} with {num_gpus}x {gpu_type}
|
| 251 |
+
- **Capacity Estimation:** {estimated_gpu_memory:.2f} GB GPU memory, {int(gpu_memory_utilization * 100)}% utilization
|
| 252 |
+
- **Context Length:** {max_model_len} tokens
|
| 253 |
+
- **Batch Configuration:** {max_num_seqs} max sequences, {max_batched_tokens} max batched tokens
|
| 254 |
+
- **Data Type:** {dtype} with {kv_cache_dtype} KV cache
|
| 255 |
+
- **vLLM Documentation:** Optimized parameters from https://docs.vllm.ai/en/v0.7.2/serving/engine_args.html
|
| 256 |
+
|
| 257 |
+
The LLM analyzed your deployment requirements and selected optimal parameters including tensor parallelism, chunked prefill, and caching strategies.
|
| 258 |
+
|
| 259 |
+
---
|
| 260 |
+
|
| 261 |
+
## 🧪 Step 5: Test the Deployment
|
| 262 |
+
|
| 263 |
+
Test your deployed model with a curl command:
|
| 264 |
+
|
| 265 |
+
```bash
|
| 266 |
+
{curl_command}
|
| 267 |
+
```
|
| 268 |
+
|
| 269 |
+
This will send a test request to your model and verify it's responding correctly.
|
| 270 |
+
|
| 271 |
+
---
|
| 272 |
+
|
| 273 |
+
## 📝 Additional Notes
|
| 274 |
+
|
| 275 |
+
- The vLLM server will download the model to `/home/ubuntu/workspace/models` on first run
|
| 276 |
+
- Make sure to monitor GPU memory usage during model loading
|
| 277 |
+
- The instance is accessible via the HiveCompute tenant URL: `https://{instance_id}-8888.tenants.hivecompute.ai`
|
| 278 |
+
- For production use, consider setting up monitoring and health checks
|
| 279 |
+
|
| 280 |
+
---
|
| 281 |
+
|
| 282 |
+
**Deployment Complete! 🎉**
|
| 283 |
+
"""
|
| 284 |
+
|
| 285 |
+
final_response_dict = {
|
| 286 |
+
"query": f"Deploy model {model_name}",
|
| 287 |
+
"final_response": final_response,
|
| 288 |
+
"instance_id": instance_id,
|
| 289 |
+
"instance_status": instance_status,
|
| 290 |
+
"sources": []
|
| 291 |
+
}
|
| 292 |
+
|
| 293 |
+
# Update state
|
| 294 |
+
updated_state = state.copy()
|
| 295 |
+
updated_state["response"] = final_response
|
| 296 |
+
updated_state["final_response_dict"] = final_response_dict
|
| 297 |
+
updated_state["current_step"] = "generate_complete"
|
| 298 |
+
|
| 299 |
+
# Remove tools to avoid serialization issues
|
| 300 |
+
if "tools" in updated_state:
|
| 301 |
+
del updated_state["tools"]
|
| 302 |
+
|
| 303 |
+
# Send via custom stream
|
| 304 |
+
writer = get_stream_writer()
|
| 305 |
+
writer({"final_response_dict": final_response_dict})
|
| 306 |
+
|
| 307 |
+
logger.info("✅ Deployment instructions generated successfully")
|
| 308 |
+
|
| 309 |
+
return updated_state
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
async def _handle_tool_results(state: Dict[str, Any], query: str, user_id: str, session_id: str,
|
| 313 |
+
tool_results: list, memory_context: str, llm) -> Dict[str, Any]:
|
| 314 |
+
"""Handle general tool results using ToolResultChain"""
|
| 315 |
+
try:
|
| 316 |
+
logger.info(f"🤖 Synthesizing tool results using ToolResultChain...")
|
| 317 |
+
|
| 318 |
+
tool_result_chain = ToolResultChain(llm=llm)
|
| 319 |
+
formatted_response = await tool_result_chain.ainvoke(query, tool_results, memory_context)
|
| 320 |
+
|
| 321 |
+
final_response_dict = {
|
| 322 |
+
"query": query,
|
| 323 |
+
"final_response": formatted_response,
|
| 324 |
+
"sources": []
|
| 325 |
+
}
|
| 326 |
+
|
| 327 |
+
updated_state = state.copy()
|
| 328 |
+
updated_state["response"] = formatted_response
|
| 329 |
+
updated_state["final_response_dict"] = final_response_dict
|
| 330 |
+
updated_state["current_step"] = "generate_complete"
|
| 331 |
+
|
| 332 |
+
# Send it via custom stream
|
| 333 |
+
writer = get_stream_writer()
|
| 334 |
+
writer({"final_response_dict": final_response_dict})
|
| 335 |
+
|
| 336 |
+
logger.info("✅ Tool results synthesized successfully")
|
| 337 |
+
return updated_state
|
| 338 |
+
|
| 339 |
+
except Exception as e:
|
| 340 |
+
logger.error(f"❌ ToolResultChain Error: {str(e)}")
|
| 341 |
+
# Final fallback to raw content
|
| 342 |
+
fallback_response = "I executed the requested tools but encountered formatting issues. Here are the raw results:\n\n"
|
| 343 |
+
for i, result in enumerate(tool_results, 1):
|
| 344 |
+
content = result.content if hasattr(result, 'content') else str(result)
|
| 345 |
+
fallback_response += f"Tool {i}: {content}\n"
|
| 346 |
+
|
| 347 |
+
final_response_dict = {
|
| 348 |
+
"query": query,
|
| 349 |
+
"final_response": fallback_response,
|
| 350 |
+
"sources": []
|
| 351 |
+
}
|
| 352 |
+
|
| 353 |
+
updated_state = state.copy()
|
| 354 |
+
updated_state["response"] = fallback_response
|
| 355 |
+
updated_state["final_response_dict"] = final_response_dict
|
| 356 |
+
updated_state["current_step"] = "generate_complete"
|
| 357 |
+
|
| 358 |
+
# Send it via custom stream
|
| 359 |
+
writer = get_stream_writer()
|
| 360 |
+
writer({"final_response_dict": final_response_dict})
|
| 361 |
+
|
| 362 |
+
logger.info("✅ Tool results formatted using raw content fallback")
|
| 363 |
+
return updated_state
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
async def generate_node(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 367 |
+
"""
|
| 368 |
+
Simple response generation with 4 clear paths:
|
| 369 |
+
1. Deployment Instructions (when instance_created == True)
|
| 370 |
+
2. Direct Answer (when current_step == "direct_answer_complete")
|
| 371 |
+
3. Researcher Results (when researcher_used == True)
|
| 372 |
+
4. General Tool Results (when tool_results exist but no researcher)
|
| 373 |
+
|
| 374 |
+
Args:
|
| 375 |
+
state: Current ReAct state
|
| 376 |
+
|
| 377 |
+
Returns:
|
| 378 |
+
Updated state with generated response
|
| 379 |
+
"""
|
| 380 |
+
logger.info("🤖 Starting response generation")
|
| 381 |
+
|
| 382 |
+
# Extract common variables
|
| 383 |
+
query = state.get("query", "")
|
| 384 |
+
user_id = state.get("user_id", "")
|
| 385 |
+
session_id = state.get("session_id", "")
|
| 386 |
+
current_step = state.get("current_step", "")
|
| 387 |
+
tool_results = state.get("tool_results", [])
|
| 388 |
+
existing_response = state.get("response", "")
|
| 389 |
+
researcher_used = state.get("researcher_used", False)
|
| 390 |
+
instance_created = state.get("instance_created", False)
|
| 391 |
+
|
| 392 |
+
# Debug logging to help diagnose path selection
|
| 393 |
+
logger.info(f"🔍 DEBUG - instance_created: {instance_created}, researcher_used: {researcher_used}, tool_results count: {len(tool_results)}, current_step: {current_step}, existing_response: {bool(existing_response)}")
|
| 394 |
+
|
| 395 |
+
# Special handling for deployment workflow
|
| 396 |
+
if instance_created:
|
| 397 |
+
logger.info("🚀 Deployment mode detected - generating deployment instructions")
|
| 398 |
+
return await _generate_deployment_instructions(state)
|
| 399 |
+
|
| 400 |
+
# Build memory context once
|
| 401 |
+
memory_context = ""
|
| 402 |
+
if user_id and session_id:
|
| 403 |
+
try:
|
| 404 |
+
from helpers.memory import get_memory_manager
|
| 405 |
+
memory_manager = get_memory_manager()
|
| 406 |
+
memory_context = await memory_manager.build_context_for_node(user_id, session_id, "general")
|
| 407 |
+
if memory_context:
|
| 408 |
+
logger.info("🧠 Using memory context for response generation")
|
| 409 |
+
except Exception as e:
|
| 410 |
+
logger.warning(f"⚠️ Could not load memory context: {e}")
|
| 411 |
+
|
| 412 |
+
# Get model info once
|
| 413 |
+
model_name = Constants.DEFAULT_LLM_NAME
|
| 414 |
+
if hasattr(state.get("refining_llm"), 'model_name'):
|
| 415 |
+
model_name = state.get("refining_llm").model_name
|
| 416 |
+
try:
|
| 417 |
+
llm = await model_manager.load_llm_model(model_name)
|
| 418 |
+
except Exception as e:
|
| 419 |
+
logger.error(f"❌ Failed to load model {model_name}: {e}")
|
| 420 |
+
return _create_error_response(state, query, "Failed to load language model")
|
| 421 |
+
|
| 422 |
+
# If no tool results, generate a direct response using LLM
|
| 423 |
+
if not tool_results:
|
| 424 |
+
logger.info("ℹ️ No tool results found - generating LLM response")
|
| 425 |
+
|
| 426 |
+
system_prompt = """You are a helpful AI assistant. The user has made a request and you need to provide a comprehensive and helpful response.
|
| 427 |
+
|
| 428 |
+
If there's an existing response or context, acknowledge it and build upon it.
|
| 429 |
+
Be professional, clear, and concise in your response.
|
| 430 |
+
If you don't have specific information to provide, politely explain what you can help with instead."""
|
| 431 |
+
|
| 432 |
+
context_info = f"Query: {query}"
|
| 433 |
+
if existing_response:
|
| 434 |
+
context_info += f"\nExisting context: {existing_response}"
|
| 435 |
+
if memory_context:
|
| 436 |
+
context_info += f"\nMemory context: {memory_context}"
|
| 437 |
+
|
| 438 |
+
messages = [
|
| 439 |
+
SystemMessage(content=system_prompt),
|
| 440 |
+
HumanMessage(content=context_info)
|
| 441 |
+
]
|
| 442 |
+
|
| 443 |
+
try:
|
| 444 |
+
response = await llm.ainvoke(messages)
|
| 445 |
+
direct_response = response.content
|
| 446 |
+
|
| 447 |
+
# Create clean copy without tools (tools not serializable)
|
| 448 |
+
updated_state = state.copy()
|
| 449 |
+
updated_state["response"] = direct_response
|
| 450 |
+
updated_state["current_step"] = "generate_complete"
|
| 451 |
+
if "tools" in updated_state:
|
| 452 |
+
del updated_state["tools"]
|
| 453 |
+
|
| 454 |
+
logger.info("✅ Generated LLM response successfully")
|
| 455 |
+
return updated_state
|
| 456 |
+
|
| 457 |
+
except Exception as e:
|
| 458 |
+
logger.error(f"❌ Error generating LLM response: {str(e)}")
|
| 459 |
+
return _create_error_response(state, query, f"Failed to generate response: {str(e)}")
|
| 460 |
+
|
| 461 |
+
# If we have tool results, use LLM to synthesize them
|
| 462 |
+
logger.info("🔧 Processing tool results using LLM synthesis")
|
| 463 |
+
|
| 464 |
+
# Prepare tool results summary
|
| 465 |
+
tool_results_summary = ""
|
| 466 |
+
for i, result in enumerate(tool_results, 1):
|
| 467 |
+
content = result.content if hasattr(result, 'content') else str(result)
|
| 468 |
+
tool_name = getattr(result, 'name', f'Tool {i}')
|
| 469 |
+
tool_results_summary += f"\n{tool_name}: {content}\n"
|
| 470 |
+
|
| 471 |
+
system_prompt = """You are a helpful AI assistant that synthesizes tool execution results into a comprehensive response.
|
| 472 |
+
|
| 473 |
+
Your task is to:
|
| 474 |
+
1. Analyze the tool results provided
|
| 475 |
+
2. Generate a clear, professional response that summarizes what was accomplished
|
| 476 |
+
3. Present the information in a well-structured format
|
| 477 |
+
4. If there are any errors or issues, explain them clearly
|
| 478 |
+
5. Be concise but thorough in your explanation
|
| 479 |
+
|
| 480 |
+
Always maintain a helpful and professional tone."""
|
| 481 |
+
|
| 482 |
+
context_info = f"Query: {query}\n\nTool Results:{tool_results_summary}"
|
| 483 |
+
if memory_context:
|
| 484 |
+
context_info += f"\nMemory context: {memory_context}"
|
| 485 |
+
|
| 486 |
+
messages = [
|
| 487 |
+
SystemMessage(content=system_prompt),
|
| 488 |
+
HumanMessage(content=context_info)
|
| 489 |
+
]
|
| 490 |
+
|
| 491 |
+
try:
|
| 492 |
+
response = await llm.ainvoke(messages)
|
| 493 |
+
synthesized_response = response.content
|
| 494 |
+
|
| 495 |
+
# Create clean copy without tools (tools not serializable)
|
| 496 |
+
updated_state = state.copy()
|
| 497 |
+
updated_state["response"] = synthesized_response
|
| 498 |
+
updated_state["current_step"] = "generate_complete"
|
| 499 |
+
if "tools" in updated_state:
|
| 500 |
+
del updated_state["tools"]
|
| 501 |
+
|
| 502 |
+
logger.info("✅ Synthesized tool results successfully using LLM")
|
| 503 |
+
return updated_state
|
| 504 |
+
|
| 505 |
+
except Exception as e:
|
| 506 |
+
logger.error(f"❌ Error synthesizing tool results with LLM: {str(e)}")
|
| 507 |
+
# Fallback to ToolResultChain if LLM synthesis fails
|
| 508 |
+
logger.info("🔄 Falling back to ToolResultChain")
|
| 509 |
+
return await _handle_tool_results(state, query, user_id, session_id, tool_results, memory_context, llm)
|
| 510 |
+
|
ComputeAgent/nodes/ReAct/human_approval_node.py
ADDED
|
@@ -0,0 +1,284 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Human Approval Node for ReAct Pattern - Enhanced Version
|
| 3 |
+
|
| 4 |
+
This module implements an enhanced human-in-the-loop approval system for the ReAct workflow
|
| 5 |
+
using LangGraph's interrupt() for API-friendly tool approval with argument modification support.
|
| 6 |
+
|
| 7 |
+
Key Features:
|
| 8 |
+
- LangGraph interrupt() for clean API integration
|
| 9 |
+
- Individual tool approval/rejection/modification
|
| 10 |
+
- Argument modification support with re-execution
|
| 11 |
+
- Batch approval support
|
| 12 |
+
- State management for approved/rejected/modified tools
|
| 13 |
+
|
| 14 |
+
Enhanced Capabilities:
|
| 15 |
+
- Approve: Execute tool with original arguments
|
| 16 |
+
- Reject: Skip tool execution
|
| 17 |
+
- Modify: Change tool arguments and re-execute reasoning
|
| 18 |
+
- Batch operations: Approve/reject/modify multiple tools at once
|
| 19 |
+
|
| 20 |
+
State Updates:
|
| 21 |
+
After approval, the state is updated with:
|
| 22 |
+
- approved_tool_calls: List of tools approved for execution (may include modified args)
|
| 23 |
+
- rejected_tool_calls: List of tools rejected by user
|
| 24 |
+
- modified_tool_calls: List of tools with modified arguments
|
| 25 |
+
- needs_re_reasoning: Flag to indicate if agent should re-reason with modified tools
|
| 26 |
+
- pending_tool_calls: Cleared after approval process
|
| 27 |
+
|
| 28 |
+
Example API Request:
|
| 29 |
+
>>> # Approve all tools
|
| 30 |
+
>>> user_decision = {
|
| 31 |
+
... "action": "approve_all"
|
| 32 |
+
... }
|
| 33 |
+
|
| 34 |
+
>>> # Approve specific tools
|
| 35 |
+
>>> user_decision = {
|
| 36 |
+
... "action": "approve_selected",
|
| 37 |
+
... "tool_indices": [0, 2] # Approve tools at index 0 and 2
|
| 38 |
+
... }
|
| 39 |
+
|
| 40 |
+
>>> # Reject all tools
|
| 41 |
+
>>> user_decision = {
|
| 42 |
+
... "action": "reject_all"
|
| 43 |
+
... }
|
| 44 |
+
|
| 45 |
+
>>> # Modify tool arguments
|
| 46 |
+
>>> user_decision = {
|
| 47 |
+
... "action": "modify_and_approve",
|
| 48 |
+
... "modifications": [
|
| 49 |
+
... {
|
| 50 |
+
... "tool_index": 0,
|
| 51 |
+
... "new_args": {"query": "modified search query"},
|
| 52 |
+
... "approve": True
|
| 53 |
+
... },
|
| 54 |
+
... {
|
| 55 |
+
... "tool_index": 1,
|
| 56 |
+
... "new_args": {"calculation": "2+2"},
|
| 57 |
+
... "approve": False
|
| 58 |
+
... }
|
| 59 |
+
... ]
|
| 60 |
+
... }
|
| 61 |
+
|
| 62 |
+
>>> # Request re-reasoning with tool context
|
| 63 |
+
>>> user_decision = {
|
| 64 |
+
... "action": "request_re_reasoning",
|
| 65 |
+
... "feedback": "Please search for more recent information"
|
| 66 |
+
... }
|
| 67 |
+
"""
|
| 68 |
+
|
| 69 |
+
from typing import Dict, Any, List
|
| 70 |
+
import logging
|
| 71 |
+
from langgraph.types import interrupt
|
| 72 |
+
|
| 73 |
+
logger = logging.getLogger("ReAct Human Approval")
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def _get_tools_from_registry(workflow_id: int):
|
| 77 |
+
"""
|
| 78 |
+
Get tools from the global registry using workflow ID.
|
| 79 |
+
"""
|
| 80 |
+
from graph.graph_ReAct import _TOOLS_REGISTRY
|
| 81 |
+
tools = _TOOLS_REGISTRY.get(workflow_id)
|
| 82 |
+
if tools is None:
|
| 83 |
+
logger.warning(f"⚠️ Tools not found in registry for workflow_id: {workflow_id}")
|
| 84 |
+
return []
|
| 85 |
+
return tools
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
async def human_approval_node(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 89 |
+
"""
|
| 90 |
+
Enhanced node that handles human approval for tool execution using LangGraph interrupt.
|
| 91 |
+
|
| 92 |
+
Supports:
|
| 93 |
+
1. Approve all tools
|
| 94 |
+
2. Approve selected tools by index
|
| 95 |
+
3. Reject all tools
|
| 96 |
+
4. Reject selected tools by index
|
| 97 |
+
5. Modify tool arguments and approve/reject
|
| 98 |
+
6. Request re-reasoning with feedback
|
| 99 |
+
|
| 100 |
+
Args:
|
| 101 |
+
state: Current ReAct state with pending tool calls
|
| 102 |
+
|
| 103 |
+
Returns:
|
| 104 |
+
Updated state with approved, rejected, and/or modified tool calls
|
| 105 |
+
"""
|
| 106 |
+
pending_tools = state.get("pending_tool_calls", [])
|
| 107 |
+
|
| 108 |
+
if not pending_tools:
|
| 109 |
+
logger.info("ℹ️ No pending tool calls for approval")
|
| 110 |
+
return state
|
| 111 |
+
|
| 112 |
+
logger.info(f"👤 Requesting human approval for {len(pending_tools)} tool call(s)")
|
| 113 |
+
|
| 114 |
+
# Get tools from registry for description lookup
|
| 115 |
+
workflow_id = state.get("workflow_id")
|
| 116 |
+
tools = _get_tools_from_registry(workflow_id) if workflow_id else []
|
| 117 |
+
|
| 118 |
+
# Prepare approval data to send to user
|
| 119 |
+
approval_data = {
|
| 120 |
+
"tool_calls": [
|
| 121 |
+
{
|
| 122 |
+
"index": i,
|
| 123 |
+
"id": tool.get("id"),
|
| 124 |
+
"name": tool.get("name"),
|
| 125 |
+
"args": tool.get("args"),
|
| 126 |
+
"description": _get_tool_description(tool.get("name"), tools)
|
| 127 |
+
}
|
| 128 |
+
for i, tool in enumerate(pending_tools)
|
| 129 |
+
],
|
| 130 |
+
"query": state.get("query", ""),
|
| 131 |
+
"total_tools": len(pending_tools)
|
| 132 |
+
}
|
| 133 |
+
|
| 134 |
+
# ✨ USE INTERRUPT - This pauses execution and waits for user input
|
| 135 |
+
user_decision = interrupt(approval_data)
|
| 136 |
+
|
| 137 |
+
logger.info(f"📥 Received tool approval decision: {user_decision.get('action', 'unknown')}")
|
| 138 |
+
|
| 139 |
+
# Process the approval decision
|
| 140 |
+
return await _process_tool_approval_decision(state, pending_tools, user_decision)
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
async def _process_tool_approval_decision(
|
| 144 |
+
state: Dict[str, Any],
|
| 145 |
+
pending_tools: List[Dict[str, Any]],
|
| 146 |
+
user_decision: Dict[str, Any]
|
| 147 |
+
) -> Dict[str, Any]:
|
| 148 |
+
"""
|
| 149 |
+
Process user's tool approval decision and update state accordingly.
|
| 150 |
+
|
| 151 |
+
Args:
|
| 152 |
+
state: Current workflow state
|
| 153 |
+
pending_tools: List of pending tool calls
|
| 154 |
+
user_decision: User's decision dictionary
|
| 155 |
+
|
| 156 |
+
Returns:
|
| 157 |
+
Updated state with approval results
|
| 158 |
+
"""
|
| 159 |
+
action = user_decision.get("action", "reject_all")
|
| 160 |
+
|
| 161 |
+
approved_calls = []
|
| 162 |
+
rejected_calls = []
|
| 163 |
+
modified_calls = []
|
| 164 |
+
needs_re_reasoning = False
|
| 165 |
+
|
| 166 |
+
# Handle different action types
|
| 167 |
+
if action == "approve_all":
|
| 168 |
+
logger.info("✅ User approved all tools")
|
| 169 |
+
approved_calls = pending_tools.copy()
|
| 170 |
+
|
| 171 |
+
elif action == "approve_selected":
|
| 172 |
+
tool_indices = user_decision.get("tool_indices", [])
|
| 173 |
+
logger.info(f"✅ User approved tools at indices: {tool_indices}")
|
| 174 |
+
|
| 175 |
+
for i, tool in enumerate(pending_tools):
|
| 176 |
+
if i in tool_indices:
|
| 177 |
+
approved_calls.append(tool)
|
| 178 |
+
else:
|
| 179 |
+
rejected_calls.append(tool)
|
| 180 |
+
|
| 181 |
+
elif action == "reject_all":
|
| 182 |
+
logger.info("❌ User rejected all tools")
|
| 183 |
+
rejected_calls = pending_tools.copy()
|
| 184 |
+
|
| 185 |
+
elif action == "reject_selected":
|
| 186 |
+
tool_indices = user_decision.get("tool_indices", [])
|
| 187 |
+
logger.info(f"❌ User rejected tools at indices: {tool_indices}")
|
| 188 |
+
|
| 189 |
+
for i, tool in enumerate(pending_tools):
|
| 190 |
+
if i in tool_indices:
|
| 191 |
+
rejected_calls.append(tool)
|
| 192 |
+
else:
|
| 193 |
+
approved_calls.append(tool)
|
| 194 |
+
|
| 195 |
+
elif action == "modify_and_approve":
|
| 196 |
+
modifications = user_decision.get("modifications", [])
|
| 197 |
+
logger.info(f"🔧 User requested modifications for {len(modifications)} tool(s)")
|
| 198 |
+
|
| 199 |
+
# Create a mapping of tool indices to modifications
|
| 200 |
+
mod_map = {mod["tool_index"]: mod for mod in modifications}
|
| 201 |
+
|
| 202 |
+
for i, tool in enumerate(pending_tools):
|
| 203 |
+
if i in mod_map:
|
| 204 |
+
mod = mod_map[i]
|
| 205 |
+
modified_tool = tool.copy()
|
| 206 |
+
|
| 207 |
+
# Update arguments
|
| 208 |
+
modified_tool["args"] = mod.get("new_args", tool["args"])
|
| 209 |
+
modified_calls.append({
|
| 210 |
+
"original": tool,
|
| 211 |
+
"modified": modified_tool,
|
| 212 |
+
"index": i
|
| 213 |
+
})
|
| 214 |
+
|
| 215 |
+
# Decide if this modified tool should be approved or rejected
|
| 216 |
+
if mod.get("approve", True):
|
| 217 |
+
approved_calls.append(modified_tool)
|
| 218 |
+
logger.info(f"✅ Modified and approved tool at index {i}: {modified_tool['name']}")
|
| 219 |
+
else:
|
| 220 |
+
rejected_calls.append(modified_tool)
|
| 221 |
+
logger.info(f"❌ Modified but rejected tool at index {i}: {modified_tool['name']}")
|
| 222 |
+
else:
|
| 223 |
+
# No modification for this tool, keep original
|
| 224 |
+
approved_calls.append(tool)
|
| 225 |
+
|
| 226 |
+
elif action == "request_re_reasoning":
|
| 227 |
+
logger.info("🔄 User requested re-reasoning")
|
| 228 |
+
needs_re_reasoning = True
|
| 229 |
+
rejected_calls = pending_tools.copy() # Reject current tools
|
| 230 |
+
|
| 231 |
+
# Store user feedback for re-reasoning
|
| 232 |
+
state["re_reasoning_feedback"] = user_decision.get("feedback", "")
|
| 233 |
+
|
| 234 |
+
else:
|
| 235 |
+
logger.warning(f"⚠️ Unknown action '{action}', defaulting to reject all")
|
| 236 |
+
rejected_calls = pending_tools.copy()
|
| 237 |
+
|
| 238 |
+
# Update state with approval results
|
| 239 |
+
updated_state = state.copy()
|
| 240 |
+
updated_state["approved_tool_calls"] = approved_calls
|
| 241 |
+
updated_state["rejected_tool_calls"] = rejected_calls
|
| 242 |
+
updated_state["modified_tool_calls"] = modified_calls
|
| 243 |
+
updated_state["needs_re_reasoning"] = needs_re_reasoning
|
| 244 |
+
updated_state["pending_tool_calls"] = [] # Clear pending calls
|
| 245 |
+
updated_state["current_step"] = "human_approval_complete"
|
| 246 |
+
|
| 247 |
+
# NOTE: Don't remove tools here - tool_execution needs them next
|
| 248 |
+
# Tools are only removed in terminal nodes (generate, tool_rejection_exit)
|
| 249 |
+
|
| 250 |
+
logger.info(
|
| 251 |
+
f"📊 Approval results: "
|
| 252 |
+
f"{len(approved_calls)} approved, "
|
| 253 |
+
f"{len(rejected_calls)} rejected, "
|
| 254 |
+
f"{len(modified_calls)} modified, "
|
| 255 |
+
f"re-reasoning: {needs_re_reasoning}"
|
| 256 |
+
)
|
| 257 |
+
|
| 258 |
+
return updated_state
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
def _get_tool_description(tool_name: str, tools: List[Any]) -> str:
|
| 262 |
+
"""
|
| 263 |
+
Get concise description for a tool by name (first sentence only).
|
| 264 |
+
|
| 265 |
+
Args:
|
| 266 |
+
tool_name: Name of the tool
|
| 267 |
+
tools: List of available tool objects
|
| 268 |
+
|
| 269 |
+
Returns:
|
| 270 |
+
First sentence of tool description or empty string
|
| 271 |
+
"""
|
| 272 |
+
for tool in tools:
|
| 273 |
+
if hasattr(tool, 'name') and tool.name == tool_name:
|
| 274 |
+
full_description = getattr(tool, 'description', '')
|
| 275 |
+
if full_description:
|
| 276 |
+
# Extract first sentence (split by period, newline, or question mark)
|
| 277 |
+
import re
|
| 278 |
+
# Split by sentence-ending punctuation
|
| 279 |
+
sentences = re.split(r'[.!?\n]+', full_description)
|
| 280 |
+
# Return first non-empty sentence
|
| 281 |
+
first_sentence = next((s.strip() for s in sentences if s.strip()), '')
|
| 282 |
+
return first_sentence if first_sentence else full_description
|
| 283 |
+
return ''
|
| 284 |
+
return ''
|
ComputeAgent/nodes/ReAct/tool_execution_node.py
ADDED
|
@@ -0,0 +1,190 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, Any
|
| 2 |
+
from langchain_core.messages import ToolMessage
|
| 3 |
+
import json
|
| 4 |
+
import logging
|
| 5 |
+
|
| 6 |
+
logger = logging.getLogger("ReAct Tool Execution")
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def _get_tools_from_registry(workflow_id: int):
|
| 10 |
+
"""
|
| 11 |
+
Get tools from the global registry using workflow ID.
|
| 12 |
+
This avoids storing non-serializable tool objects in state.
|
| 13 |
+
"""
|
| 14 |
+
from graph.graph_ReAct import _TOOLS_REGISTRY
|
| 15 |
+
tools = _TOOLS_REGISTRY.get(workflow_id)
|
| 16 |
+
if tools is None:
|
| 17 |
+
raise ValueError(f"Tools not found in registry for workflow_id: {workflow_id}")
|
| 18 |
+
return tools
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
async def tool_execution_node(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 22 |
+
"""
|
| 23 |
+
Node that executes approved tools and handles special researcher tool case.
|
| 24 |
+
|
| 25 |
+
Args:
|
| 26 |
+
state: Current ReAct state with approved tool calls
|
| 27 |
+
|
| 28 |
+
Returns:
|
| 29 |
+
Updated state with tool results and special handling for researcher
|
| 30 |
+
"""
|
| 31 |
+
approved_calls = state.get("approved_tool_calls", [])
|
| 32 |
+
|
| 33 |
+
if not approved_calls:
|
| 34 |
+
logger.info("ℹ️ No approved tool calls to execute")
|
| 35 |
+
return state
|
| 36 |
+
|
| 37 |
+
# Get tools from registry using workflow_id (avoids serialization issues)
|
| 38 |
+
workflow_id = state.get("workflow_id")
|
| 39 |
+
if not workflow_id:
|
| 40 |
+
logger.error("❌ No workflow_id in state - cannot retrieve tools")
|
| 41 |
+
return state
|
| 42 |
+
|
| 43 |
+
try:
|
| 44 |
+
tools = _get_tools_from_registry(workflow_id)
|
| 45 |
+
tools_dict = {tool.name: tool for tool in tools}
|
| 46 |
+
logger.info(f"✅ Retrieved {len(tools)} tools from registry")
|
| 47 |
+
except ValueError as e:
|
| 48 |
+
logger.error(f"❌ {e}")
|
| 49 |
+
return state
|
| 50 |
+
|
| 51 |
+
tool_results = []
|
| 52 |
+
researcher_executed = False
|
| 53 |
+
instance_created = False
|
| 54 |
+
|
| 55 |
+
logger.info(f"⚡ Executing {len(approved_calls)} approved tool call(s)")
|
| 56 |
+
|
| 57 |
+
for tool_call in approved_calls:
|
| 58 |
+
tool_name = tool_call['name']
|
| 59 |
+
|
| 60 |
+
try:
|
| 61 |
+
tool = tools_dict.get(tool_name)
|
| 62 |
+
if not tool:
|
| 63 |
+
error_msg = f"Error: Tool {tool_name} not found."
|
| 64 |
+
logger.error(error_msg)
|
| 65 |
+
tool_results.append(
|
| 66 |
+
ToolMessage(
|
| 67 |
+
content=error_msg,
|
| 68 |
+
tool_call_id=tool_call['id']
|
| 69 |
+
)
|
| 70 |
+
)
|
| 71 |
+
continue
|
| 72 |
+
|
| 73 |
+
logger.info(f"🔄 Executing tool: {tool_name}")
|
| 74 |
+
result = await tool.ainvoke(tool_call['args'])
|
| 75 |
+
|
| 76 |
+
# Special handling for create_compute_instance tool
|
| 77 |
+
if tool_name == "create_compute_instance":
|
| 78 |
+
instance_created = True
|
| 79 |
+
logger.info("🚀 create_compute_instance tool executed - storing instance details")
|
| 80 |
+
|
| 81 |
+
# Extract instance_id and status from result
|
| 82 |
+
# Result may be a string containing JSON or a dict
|
| 83 |
+
try:
|
| 84 |
+
logger.info(f"📋 Raw result type: {type(result)}, value: {result}")
|
| 85 |
+
|
| 86 |
+
if isinstance(result, str):
|
| 87 |
+
# Parse JSON string to dict
|
| 88 |
+
result_dict = json.loads(result)
|
| 89 |
+
elif isinstance(result, dict):
|
| 90 |
+
result_dict = result
|
| 91 |
+
else:
|
| 92 |
+
result_dict = {}
|
| 93 |
+
|
| 94 |
+
# The result may be nested in a 'result' key
|
| 95 |
+
if "result" in result_dict and isinstance(result_dict["result"], dict):
|
| 96 |
+
instance_data = result_dict["result"]
|
| 97 |
+
else:
|
| 98 |
+
instance_data = result_dict
|
| 99 |
+
|
| 100 |
+
instance_id = instance_data.get("id", "")
|
| 101 |
+
instance_status = str(instance_data.get("status", ""))
|
| 102 |
+
|
| 103 |
+
logger.info(f"📋 Extracted instance_id: '{instance_id}', status: '{instance_status}'")
|
| 104 |
+
|
| 105 |
+
# Store in state for generate node
|
| 106 |
+
state["instance_id"] = instance_id
|
| 107 |
+
state["instance_status"] = instance_status
|
| 108 |
+
state["instance_created"] = True
|
| 109 |
+
|
| 110 |
+
logger.info(f"✅ Instance created and stored in state: {instance_id} (status: {instance_status})")
|
| 111 |
+
except (json.JSONDecodeError, AttributeError) as e:
|
| 112 |
+
logger.warning(f"⚠️ Could not parse result from create_compute_instance: {e}")
|
| 113 |
+
logger.warning(f"⚠️ Result: {result}")
|
| 114 |
+
state["instance_created"] = False
|
| 115 |
+
|
| 116 |
+
# Store the result for tool results
|
| 117 |
+
tool_results.append(
|
| 118 |
+
ToolMessage(
|
| 119 |
+
content=str(result),
|
| 120 |
+
tool_call_id=tool_call['id']
|
| 121 |
+
)
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
# Special handling for researcher tool
|
| 125 |
+
elif tool_name == "research":
|
| 126 |
+
researcher_executed = True
|
| 127 |
+
logger.info("🌐 Researcher tool executed - storing results for generation")
|
| 128 |
+
|
| 129 |
+
# Set flag to indicate researcher was used
|
| 130 |
+
state["researcher_used"] = True
|
| 131 |
+
|
| 132 |
+
# Store the research result for the generate node to use
|
| 133 |
+
tool_results.append(
|
| 134 |
+
ToolMessage(
|
| 135 |
+
content=str(result),
|
| 136 |
+
tool_call_id=tool_call['id']
|
| 137 |
+
)
|
| 138 |
+
)
|
| 139 |
+
|
| 140 |
+
logger.info("✅ Researcher tool completed - results stored for generation")
|
| 141 |
+
else:
|
| 142 |
+
# Regular tool execution
|
| 143 |
+
tool_results.append(
|
| 144 |
+
ToolMessage(
|
| 145 |
+
content=str(result),
|
| 146 |
+
tool_call_id=tool_call['id']
|
| 147 |
+
)
|
| 148 |
+
)
|
| 149 |
+
logger.info(f"✅ Tool {tool_name} executed successfully")
|
| 150 |
+
|
| 151 |
+
except Exception as e:
|
| 152 |
+
error_msg = f"Error executing tool {tool_name}: {str(e)}"
|
| 153 |
+
logger.error(error_msg)
|
| 154 |
+
tool_results.append(
|
| 155 |
+
ToolMessage(
|
| 156 |
+
content=error_msg,
|
| 157 |
+
tool_call_id=tool_call['id']
|
| 158 |
+
)
|
| 159 |
+
)
|
| 160 |
+
|
| 161 |
+
# Update state with execution results
|
| 162 |
+
updated_state = state.copy()
|
| 163 |
+
|
| 164 |
+
# Append new tool results to existing ones for multi-tool scenarios
|
| 165 |
+
existing_results = updated_state.get("tool_results", [])
|
| 166 |
+
updated_state["tool_results"] = existing_results + tool_results
|
| 167 |
+
|
| 168 |
+
updated_state["messages"] = state["messages"] + tool_results
|
| 169 |
+
updated_state["approved_tool_calls"] = [] # Clear approved calls
|
| 170 |
+
updated_state["researcher_executed"] = researcher_executed
|
| 171 |
+
updated_state["skip_refinement"] = researcher_executed # Skip refinement if researcher executed
|
| 172 |
+
updated_state["current_step"] = "tool_execution_complete"
|
| 173 |
+
|
| 174 |
+
# Ensure instance creation flags are preserved in updated_state
|
| 175 |
+
if state.get("instance_created"):
|
| 176 |
+
updated_state["instance_created"] = state["instance_created"]
|
| 177 |
+
updated_state["instance_id"] = state.get("instance_id", "")
|
| 178 |
+
updated_state["instance_status"] = state.get("instance_status", "")
|
| 179 |
+
logger.info(f"✅ Instance creation flags preserved in state: {updated_state['instance_id']}")
|
| 180 |
+
|
| 181 |
+
# Clear force_refinement flag after tool execution
|
| 182 |
+
if "force_refinement" in updated_state:
|
| 183 |
+
del updated_state["force_refinement"]
|
| 184 |
+
|
| 185 |
+
# NOTE: Don't remove tools here - agent_reasoning needs them next
|
| 186 |
+
# Tools are only removed in terminal nodes (generate, tool_rejection_exit)
|
| 187 |
+
|
| 188 |
+
logger.info(f"📈 Tool execution completed: {len(tool_results)} new results, {len(updated_state['tool_results'])} total results")
|
| 189 |
+
|
| 190 |
+
return updated_state
|
ComputeAgent/nodes/ReAct/tool_rejection_exit_node.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, Any
|
| 2 |
+
from langchain_core.messages import HumanMessage
|
| 3 |
+
from models.model_manager import ModelManager
|
| 4 |
+
from constant import Constants
|
| 5 |
+
import logging
|
| 6 |
+
|
| 7 |
+
logger = logging.getLogger("ReAct Tool Rejection Exit")
|
| 8 |
+
|
| 9 |
+
# Initialize model manager for LLM loading
|
| 10 |
+
model_manager = ModelManager()
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
async def tool_rejection_exit_node(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 14 |
+
"""
|
| 15 |
+
Node that handles the case when human declines all tool executions.
|
| 16 |
+
Provides a helpful, personalized response using memory context and LLM.
|
| 17 |
+
|
| 18 |
+
Args:
|
| 19 |
+
state: Current ReAct state with memory fields
|
| 20 |
+
|
| 21 |
+
Returns:
|
| 22 |
+
Updated state with helpful exit message and final response
|
| 23 |
+
"""
|
| 24 |
+
logger.info("🚪 User declined all tool executions - generating helpful response")
|
| 25 |
+
|
| 26 |
+
# Get original query and user context
|
| 27 |
+
query = state.get("query", "")
|
| 28 |
+
user_id = state.get("user_id", "")
|
| 29 |
+
session_id = state.get("session_id", "")
|
| 30 |
+
|
| 31 |
+
# Build memory context for personalized response
|
| 32 |
+
memory_context = ""
|
| 33 |
+
if user_id and session_id:
|
| 34 |
+
try:
|
| 35 |
+
from helpers.memory import get_memory_manager
|
| 36 |
+
memory_manager = get_memory_manager()
|
| 37 |
+
memory_context = await memory_manager.build_context_for_node(user_id, session_id, "general")
|
| 38 |
+
if memory_context:
|
| 39 |
+
logger.info(f"🧠 Using memory context for tool rejection response")
|
| 40 |
+
except Exception as e:
|
| 41 |
+
logger.warning(f"⚠️ Could not load memory context for tool rejection: {e}")
|
| 42 |
+
|
| 43 |
+
# Generate a more helpful and personalized response using LLM
|
| 44 |
+
try:
|
| 45 |
+
# Load LLM for generating helpful response
|
| 46 |
+
llm = await model_manager.load_llm_model(Constants.DEFAULT_LLM_NAME)
|
| 47 |
+
|
| 48 |
+
# Get information about what tools were proposed
|
| 49 |
+
pending_tool_calls = state.get("pending_tool_calls", [])
|
| 50 |
+
tool_names = [tool.get('name', 'unknown tool') for tool in pending_tool_calls] if pending_tool_calls else ["tools"]
|
| 51 |
+
|
| 52 |
+
# Create prompt for helpful response
|
| 53 |
+
system_prompt = Constants.GENERAL_SYSTEM_PROMPT + r"""
|
| 54 |
+
You are ComputeAgent, a helpful AI assistant. The user has chosen **not to use** the recommended {', '.join(tool_names)} for their query.
|
| 55 |
+
|
| 56 |
+
Your task is to respond in a **positive, supportive, and helpful way** that:
|
| 57 |
+
1. Respectfully acknowledges their choice.
|
| 58 |
+
2. Suggests alternative ways to assist them.
|
| 59 |
+
3. Offers ideas on how they might **rephrase or clarify** their query for better results.
|
| 60 |
+
4. Personalizes the response using any available conversation context.
|
| 61 |
+
|
| 62 |
+
User's Query: {query}
|
| 63 |
+
|
| 64 |
+
{f"Conversation Context: {memory_context}" if memory_context else ""}
|
| 65 |
+
|
| 66 |
+
Provide a **helpful, encouraging, and concise response** (2-3 sentences) that guides the user toward next steps without pressuring them to use the tool.
|
| 67 |
+
"""
|
| 68 |
+
|
| 69 |
+
response = await llm.ainvoke([HumanMessage(content=system_prompt)])
|
| 70 |
+
exit_message = response.content.strip()
|
| 71 |
+
|
| 72 |
+
logger.info(f"🤖 Generated personalized tool rejection response for user {user_id}, session {session_id}")
|
| 73 |
+
|
| 74 |
+
except Exception as e:
|
| 75 |
+
logger.warning(f"⚠️ Could not generate LLM response for tool rejection: {e}")
|
| 76 |
+
# Fallback to enhanced static message
|
| 77 |
+
if memory_context:
|
| 78 |
+
exit_message = f"I understand you'd prefer not to use the suggested tools. Based on our conversation, I can try to help you in other ways. Could you please rephrase your question or let me know what specific information you're looking for? I'm here to assist you however I can."
|
| 79 |
+
else:
|
| 80 |
+
exit_message = "I understand you'd prefer not to use the suggested tools. I'm happy to help you in other ways! Could you please rephrase your question or provide more details about what you're looking for? I'm here to assist you with direct answers whenever possible."
|
| 81 |
+
|
| 82 |
+
# Update state with final response
|
| 83 |
+
updated_state = state.copy()
|
| 84 |
+
updated_state["response"] = exit_message
|
| 85 |
+
updated_state["current_step"] = "tool_rejection_exit"
|
| 86 |
+
|
| 87 |
+
# Remove tools from state to avoid serialization issues
|
| 88 |
+
if "tools" in updated_state:
|
| 89 |
+
del updated_state["tools"]
|
| 90 |
+
|
| 91 |
+
logger.info("✅ Tool rejection exit complete with helpful response")
|
| 92 |
+
|
| 93 |
+
return updated_state
|
ComputeAgent/nodes/ReAct_DeployModel/__init__.py
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
ReAct DeployModel Package
|
| 3 |
+
|
| 4 |
+
This package contains specialized nodes for the model deployment workflow.
|
| 5 |
+
Each node handles a specific aspect of the deployment process:
|
| 6 |
+
|
| 7 |
+
- extract_model_info: Extracts model information from user queries
|
| 8 |
+
- generate_model_name: Generates model names when information is unknown
|
| 9 |
+
- capacity_estimation: Estimates compute capacity requirements
|
| 10 |
+
|
| 11 |
+
Author: ComputeAgent Team
|
| 12 |
+
License: Private
|
| 13 |
+
"""
|
ComputeAgent/nodes/ReAct_DeployModel/capacity_approval.py
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Capacity Approval Node Using LangGraph Interrupt
|
| 3 |
+
|
| 4 |
+
This version uses LangGraph's native interrupt() for human-in-the-loop approval.
|
| 5 |
+
Much cleaner than the previous implementation!
|
| 6 |
+
|
| 7 |
+
Key Changes:
|
| 8 |
+
1. Uses interrupt() to pause execution and wait for approval
|
| 9 |
+
2. Returns approval decision directly from interrupt
|
| 10 |
+
3. Simpler state management
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
import logging
|
| 14 |
+
from typing import Dict, Any
|
| 15 |
+
from langgraph.types import interrupt
|
| 16 |
+
from constant import Constants
|
| 17 |
+
|
| 18 |
+
logger = logging.getLogger("CapacityApproval")
|
| 19 |
+
|
| 20 |
+
LOCATION_GPU_MAP = {
|
| 21 |
+
"France": ["RTX 4090"],
|
| 22 |
+
"UAE-1": ["RTX 4090"],
|
| 23 |
+
"Texas": ["RTX 5090"],
|
| 24 |
+
"UAE-2": ["RTX 5090"]
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
# Reverse mapping for finding locations by GPU type
|
| 28 |
+
GPU_LOCATION_MAP = {}
|
| 29 |
+
for location, gpu_types in LOCATION_GPU_MAP.items():
|
| 30 |
+
for gpu_type in gpu_types:
|
| 31 |
+
if gpu_type not in GPU_LOCATION_MAP:
|
| 32 |
+
GPU_LOCATION_MAP[gpu_type] = []
|
| 33 |
+
GPU_LOCATION_MAP[gpu_type].append(location)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
async def capacity_approval_node(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 37 |
+
"""
|
| 38 |
+
Node that handles human approval for capacity estimation using LangGraph interrupt.
|
| 39 |
+
|
| 40 |
+
Uses interrupt() to pause execution and wait for approval decision from API/UI.
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
state: Current deployment state with capacity estimation results
|
| 44 |
+
|
| 45 |
+
Returns:
|
| 46 |
+
Updated state with approval results
|
| 47 |
+
"""
|
| 48 |
+
logger.info("👤 Starting capacity estimation approval process")
|
| 49 |
+
|
| 50 |
+
# Check if capacity estimation was successful
|
| 51 |
+
if state.get("capacity_estimation_status") != "success":
|
| 52 |
+
logger.error("❌ Cannot approve capacity - estimation not successful")
|
| 53 |
+
state["capacity_approval_status"] = "error"
|
| 54 |
+
state["error"] = "Capacity estimation must be successful before approval"
|
| 55 |
+
return state
|
| 56 |
+
|
| 57 |
+
# Extract capacity estimation details
|
| 58 |
+
model_name = state.get("model_name", "Unknown Model")
|
| 59 |
+
estimated_gpu_memory = state.get("estimated_gpu_memory", 0)
|
| 60 |
+
gpu_requirements = state.get("gpu_requirements", {})
|
| 61 |
+
|
| 62 |
+
logger.info(f"📊 Requesting approval for {model_name}: {estimated_gpu_memory:.2f} GB")
|
| 63 |
+
|
| 64 |
+
# Prepare approval data to send to user
|
| 65 |
+
capacity_response = state.get("response", "")
|
| 66 |
+
|
| 67 |
+
approval_data = {
|
| 68 |
+
"model_name": model_name,
|
| 69 |
+
"estimated_gpu_memory": estimated_gpu_memory,
|
| 70 |
+
"gpu_requirements": gpu_requirements,
|
| 71 |
+
"formatted_response": capacity_response,
|
| 72 |
+
"model_info": state.get("model_info", {}),
|
| 73 |
+
"capacity_estimate": state.get("capacity_estimate", {}),
|
| 74 |
+
"gpu_type": state.get("model_info", {}).get("GPU_type", "RTX 4090"),
|
| 75 |
+
"location": state.get("model_info", {}).get("location", "UAE-1"),
|
| 76 |
+
"cost_estimates": state.get("capacity_estimate", {}).get("cost_estimates", {})
|
| 77 |
+
}
|
| 78 |
+
|
| 79 |
+
# ✨ USE INTERRUPT - This pauses execution and waits for user input
|
| 80 |
+
user_decision = interrupt(approval_data)
|
| 81 |
+
|
| 82 |
+
logger.info(f"📥 Received approval decision: {user_decision}")
|
| 83 |
+
|
| 84 |
+
# Process the approval decision
|
| 85 |
+
if isinstance(user_decision, dict):
|
| 86 |
+
capacity_approved = user_decision.get("capacity_approved")
|
| 87 |
+
custom_config = user_decision.get("custom_config", {})
|
| 88 |
+
needs_re_estimation = user_decision.get("needs_re_estimation", False)
|
| 89 |
+
|
| 90 |
+
# Handle re-estimation FIRST (highest priority)
|
| 91 |
+
if needs_re_estimation is True:
|
| 92 |
+
logger.info(f"🔄 Re-estimation requested with custom config")
|
| 93 |
+
|
| 94 |
+
# Update model_info with new config
|
| 95 |
+
model_info = state.get("model_info", {}).copy()
|
| 96 |
+
model_info.update(custom_config)
|
| 97 |
+
state["model_info"] = model_info
|
| 98 |
+
|
| 99 |
+
# Clear previous estimation results
|
| 100 |
+
state["capacity_estimate"] = {}
|
| 101 |
+
state["estimated_gpu_memory"] = 0
|
| 102 |
+
state["gpu_requirements"] = {}
|
| 103 |
+
|
| 104 |
+
# Set routing flags
|
| 105 |
+
state["needs_re_estimation"] = True
|
| 106 |
+
state["capacity_approval_status"] = "re_estimation_requested"
|
| 107 |
+
state["current_step"] = "capacity_re_estimation"
|
| 108 |
+
state["capacity_approved"] = None
|
| 109 |
+
|
| 110 |
+
logger.info(f"🔄 State prepared for re-estimation")
|
| 111 |
+
return state
|
| 112 |
+
|
| 113 |
+
# Handle approval
|
| 114 |
+
if capacity_approved is True:
|
| 115 |
+
logger.info(f"✅ Capacity estimation approved for {model_name}")
|
| 116 |
+
state["capacity_approved"] = True
|
| 117 |
+
state["capacity_approval_status"] = "approved"
|
| 118 |
+
state["current_step"] = "capacity_approved"
|
| 119 |
+
state["needs_re_estimation"] = False
|
| 120 |
+
|
| 121 |
+
# Apply custom configuration if provided
|
| 122 |
+
if custom_config:
|
| 123 |
+
logger.info(f"🔧 Applying custom inference configuration")
|
| 124 |
+
model_info = state.get("model_info", {}).copy()
|
| 125 |
+
model_info.update(custom_config)
|
| 126 |
+
state["model_info"] = model_info
|
| 127 |
+
|
| 128 |
+
# Handle rejection
|
| 129 |
+
elif capacity_approved is False:
|
| 130 |
+
logger.info(f"❌ Capacity estimation rejected for {model_name}")
|
| 131 |
+
state["capacity_approved"] = False
|
| 132 |
+
state["capacity_approval_status"] = "rejected"
|
| 133 |
+
state["current_step"] = "capacity_rejected"
|
| 134 |
+
state["needs_re_estimation"] = False
|
| 135 |
+
|
| 136 |
+
else:
|
| 137 |
+
# Simple boolean response (backward compatibility)
|
| 138 |
+
if user_decision:
|
| 139 |
+
logger.info(f"✅ Capacity estimation approved for {model_name}")
|
| 140 |
+
state["capacity_approved"] = True
|
| 141 |
+
state["capacity_approval_status"] = "approved"
|
| 142 |
+
state["current_step"] = "capacity_approved"
|
| 143 |
+
state["needs_re_estimation"] = False
|
| 144 |
+
else:
|
| 145 |
+
logger.info(f"❌ Capacity estimation rejected for {model_name}")
|
| 146 |
+
state["capacity_approved"] = False
|
| 147 |
+
state["capacity_approval_status"] = "rejected"
|
| 148 |
+
state["current_step"] = "capacity_rejected"
|
| 149 |
+
state["needs_re_estimation"] = False
|
| 150 |
+
|
| 151 |
+
return state
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
async def auto_capacity_approval_node(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 155 |
+
"""
|
| 156 |
+
Node that automatically approves capacity estimation when human approval is disabled.
|
| 157 |
+
|
| 158 |
+
Args:
|
| 159 |
+
state: Current deployment state with capacity estimation results
|
| 160 |
+
|
| 161 |
+
Returns:
|
| 162 |
+
Updated state with automatic approval
|
| 163 |
+
"""
|
| 164 |
+
logger.info("🤖 Auto-approving capacity estimation")
|
| 165 |
+
|
| 166 |
+
# Check if capacity estimation was successful
|
| 167 |
+
if state.get("capacity_estimation_status") != "success":
|
| 168 |
+
logger.error("❌ Cannot auto-approve capacity - estimation not successful")
|
| 169 |
+
state["capacity_approval_status"] = "error"
|
| 170 |
+
state["error"] = "Capacity estimation must be successful before auto-approval"
|
| 171 |
+
return state
|
| 172 |
+
|
| 173 |
+
model_name = state.get("model_name", "Unknown Model")
|
| 174 |
+
|
| 175 |
+
# Automatically approve the capacity estimation
|
| 176 |
+
state["capacity_approved"] = True
|
| 177 |
+
state["capacity_approval_status"] = "auto_approved"
|
| 178 |
+
state["custom_capacity"] = {}
|
| 179 |
+
state["current_step"] = "capacity_auto_approved"
|
| 180 |
+
|
| 181 |
+
logger.info(f"✅ Capacity estimation auto-approved for {model_name}")
|
| 182 |
+
|
| 183 |
+
return state
|
ComputeAgent/nodes/ReAct_DeployModel/capacity_estimation.py
ADDED
|
@@ -0,0 +1,387 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Capacity Estimation Node
|
| 3 |
+
|
| 4 |
+
This node handles the estimation of compute capacity requirements for model deployment.
|
| 5 |
+
Currently minimal implementation - placeholder for future capacity estimation logic.
|
| 6 |
+
|
| 7 |
+
Key Features:
|
| 8 |
+
- Compute capacity estimation (placeholder)
|
| 9 |
+
- Resource requirement analysis (placeholder)
|
| 10 |
+
- State management for workflow
|
| 11 |
+
|
| 12 |
+
Author: ComputeAgent Team
|
| 13 |
+
License: Private
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
import logging
|
| 17 |
+
import math
|
| 18 |
+
from typing import Dict, Any
|
| 19 |
+
|
| 20 |
+
logger = logging.getLogger("CapacityEstimation")
|
| 21 |
+
|
| 22 |
+
# Mapping dtype to factor (bytes per parameter)
|
| 23 |
+
DTYPE_FACTOR = {
|
| 24 |
+
# Standard PyTorch dtypes
|
| 25 |
+
"auto": 2,
|
| 26 |
+
"half": 2,
|
| 27 |
+
"float16": 2,
|
| 28 |
+
"fp16": 2,
|
| 29 |
+
"bfloat16": 2,
|
| 30 |
+
"bf16": 2,
|
| 31 |
+
"float": 4,
|
| 32 |
+
"float32": 4,
|
| 33 |
+
"fp32": 4,
|
| 34 |
+
# Quantized dtypes
|
| 35 |
+
"fp8": 1,
|
| 36 |
+
"fp8_e4m3": 1,
|
| 37 |
+
"fp8_e5m2": 1,
|
| 38 |
+
"f8_e4m3": 1, # HuggingFace naming convention
|
| 39 |
+
"f8_e5m2": 1,
|
| 40 |
+
"int8": 1,
|
| 41 |
+
"int4": 0.5,
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
KV_CACHE_DTYPE_FACTOR = {
|
| 45 |
+
"auto": None, # Will be set to model dtype factor
|
| 46 |
+
"float32": 4,
|
| 47 |
+
"fp32": 4,
|
| 48 |
+
"float16": 2,
|
| 49 |
+
"fp16": 2,
|
| 50 |
+
"bfloat16": 2,
|
| 51 |
+
"bf16": 2,
|
| 52 |
+
"fp8": 1,
|
| 53 |
+
"fp8_e5m2": 1,
|
| 54 |
+
"fp8_e4m3": 1,
|
| 55 |
+
"f8_e4m3": 1, # HuggingFace naming convention
|
| 56 |
+
"f8_e5m2": 1,
|
| 57 |
+
"int8": 1,
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
# GPU specifications (in GB)
|
| 61 |
+
GPU_SPECS = {
|
| 62 |
+
"RTX 4090": 24,
|
| 63 |
+
"RTX 5090": 32,
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
# GPU pricing (in EUR per hour)
|
| 67 |
+
GPU_PRICING = {
|
| 68 |
+
"RTX 4090": 0.2,
|
| 69 |
+
"RTX 5090": 0.4,
|
| 70 |
+
}
|
| 71 |
+
|
| 72 |
+
def normalize_dtype(dtype: str) -> str:
|
| 73 |
+
"""
|
| 74 |
+
Normalize dtype string to a canonical form for consistent lookup.
|
| 75 |
+
|
| 76 |
+
Args:
|
| 77 |
+
dtype: Raw dtype string (e.g., "F8_E4M3", "BF16", "float16")
|
| 78 |
+
|
| 79 |
+
Returns:
|
| 80 |
+
Normalized dtype string in lowercase with underscores
|
| 81 |
+
"""
|
| 82 |
+
if not dtype:
|
| 83 |
+
return "auto"
|
| 84 |
+
|
| 85 |
+
# Convert to lowercase and handle common variations
|
| 86 |
+
normalized = dtype.lower()
|
| 87 |
+
|
| 88 |
+
# Handle HuggingFace safetensors naming conventions
|
| 89 |
+
# F8_E4M3 -> f8_e4m3, BF16 -> bf16, etc.
|
| 90 |
+
return normalized
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def get_dtype_factor(dtype: str, default: int = 2) -> float:
|
| 94 |
+
"""
|
| 95 |
+
Get the bytes-per-parameter factor for a given dtype.
|
| 96 |
+
|
| 97 |
+
Args:
|
| 98 |
+
dtype: Data type string
|
| 99 |
+
default: Default factor if dtype not found
|
| 100 |
+
|
| 101 |
+
Returns:
|
| 102 |
+
Factor (bytes per parameter)
|
| 103 |
+
"""
|
| 104 |
+
normalized = normalize_dtype(dtype)
|
| 105 |
+
return DTYPE_FACTOR.get(normalized, default)
|
| 106 |
+
|
| 107 |
+
def estimate_vllm_gpu_memory(
|
| 108 |
+
num_params: int,
|
| 109 |
+
dtype: str = "auto",
|
| 110 |
+
num_hidden_layers: int = None,
|
| 111 |
+
hidden_size: int = None,
|
| 112 |
+
intermediate_size: int = None,
|
| 113 |
+
num_key_value_heads: int = None,
|
| 114 |
+
head_dim: int = None,
|
| 115 |
+
max_model_len: int = 2048,
|
| 116 |
+
max_num_seqs: int = 256,
|
| 117 |
+
max_num_batched_tokens: int = 2048,
|
| 118 |
+
kv_cache_dtype: str = "auto",
|
| 119 |
+
gpu_memory_utilization: float = 0.9,
|
| 120 |
+
cpu_offload_gb: float = 0.0,
|
| 121 |
+
is_quantized: bool = None # NEW: indicate if num_params is already quantized
|
| 122 |
+
) -> float:
|
| 123 |
+
"""
|
| 124 |
+
Estimate GPU memory for a model. Handles:
|
| 125 |
+
1. Full parameter info -> detailed estimation
|
| 126 |
+
2. Only num_params and dtype -> rough estimation
|
| 127 |
+
Returns memory in GB
|
| 128 |
+
|
| 129 |
+
Args:
|
| 130 |
+
num_params: Number of parameters. For quantized models from HF API,
|
| 131 |
+
this is already in the quantized format.
|
| 132 |
+
is_quantized: If True, num_params represents quantized size.
|
| 133 |
+
If None, auto-detect from dtype.
|
| 134 |
+
"""
|
| 135 |
+
constant_margin = 1.5
|
| 136 |
+
|
| 137 |
+
dtype_factor = get_dtype_factor(dtype, default=2)
|
| 138 |
+
|
| 139 |
+
# Auto-detect if model is quantized
|
| 140 |
+
if is_quantized is None:
|
| 141 |
+
quantized_dtypes = ["fp8", "f8_e4m3", "f8_e5m2", "int8", "int4", "fp8_e4m3", "fp8_e5m2"]
|
| 142 |
+
is_quantized = normalize_dtype(dtype) in quantized_dtypes
|
| 143 |
+
|
| 144 |
+
# Case 1: Only num_params available (simplified)
|
| 145 |
+
if None in [num_hidden_layers, hidden_size, intermediate_size, num_key_value_heads, head_dim]:
|
| 146 |
+
if is_quantized:
|
| 147 |
+
# num_params already represents quantized size
|
| 148 |
+
# HF API returns parameter count in the quantized dtype
|
| 149 |
+
# So we DON'T multiply by dtype_factor again
|
| 150 |
+
model_weight = num_params / 1e9 # Already accounts for quantization
|
| 151 |
+
else:
|
| 152 |
+
# For non-quantized models, calculate weight from params
|
| 153 |
+
model_weight = (num_params * dtype_factor) / 1e9
|
| 154 |
+
|
| 155 |
+
# Rough activation estimate (typically FP16 regardless of weight dtype)
|
| 156 |
+
# Activation memory is roughly 1-2x model weight for transformer models
|
| 157 |
+
activation_estimate = model_weight * 1.5
|
| 158 |
+
|
| 159 |
+
estimated_gpu_memory = (model_weight + activation_estimate + constant_margin) / gpu_memory_utilization - cpu_offload_gb
|
| 160 |
+
return estimated_gpu_memory
|
| 161 |
+
|
| 162 |
+
# Case 2: Full info available -> detailed vLLM formula
|
| 163 |
+
if is_quantized:
|
| 164 |
+
model_weight = num_params / 1e9
|
| 165 |
+
else:
|
| 166 |
+
model_weight = (num_params * dtype_factor) / 1e9
|
| 167 |
+
|
| 168 |
+
if kv_cache_dtype == "auto":
|
| 169 |
+
# For quantized models, KV cache often uses FP16/BF16, not FP8
|
| 170 |
+
kv_cache_dtype_factor = 2 if is_quantized else dtype_factor
|
| 171 |
+
else:
|
| 172 |
+
normalized_kv = normalize_dtype(kv_cache_dtype)
|
| 173 |
+
kv_cache_dtype_factor = KV_CACHE_DTYPE_FACTOR.get(normalized_kv, 2)
|
| 174 |
+
|
| 175 |
+
per_seq_kv_cache_memory = (2 * num_key_value_heads * head_dim * num_hidden_layers *
|
| 176 |
+
kv_cache_dtype_factor * max_model_len) / 1e9
|
| 177 |
+
|
| 178 |
+
total_kv_cache_memory = min(
|
| 179 |
+
per_seq_kv_cache_memory * max_num_seqs,
|
| 180 |
+
(2 * num_hidden_layers * hidden_size * kv_cache_dtype_factor * max_num_batched_tokens) / 1e9
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
# Activations are typically FP16/BF16 even for quantized models
|
| 184 |
+
activation_dtype_factor = 2 # Assume FP16 activations
|
| 185 |
+
activation_peak_memory = max_model_len * ((18 * hidden_size) + (4 * intermediate_size)) * activation_dtype_factor / 1e9
|
| 186 |
+
|
| 187 |
+
required_gpu_memory = (model_weight + total_kv_cache_memory + activation_peak_memory + constant_margin) / gpu_memory_utilization - cpu_offload_gb
|
| 188 |
+
|
| 189 |
+
return required_gpu_memory
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
def calculate_gpu_requirements(estimated_memory_gb: float) -> Dict[str, Any]:
|
| 193 |
+
"""
|
| 194 |
+
Calculate number of GPUs needed and costs for different GPU types.
|
| 195 |
+
|
| 196 |
+
Args:
|
| 197 |
+
estimated_memory_gb: Estimated GPU memory requirement in GB
|
| 198 |
+
|
| 199 |
+
Returns:
|
| 200 |
+
Dictionary containing GPU requirements and cost information
|
| 201 |
+
"""
|
| 202 |
+
gpu_requirements = {}
|
| 203 |
+
cost_estimates = {}
|
| 204 |
+
|
| 205 |
+
for gpu_type, gpu_memory in GPU_SPECS.items():
|
| 206 |
+
# Account for ~10% overhead for communication and fragmentation in multi-GPU setup
|
| 207 |
+
usable_memory = gpu_memory * 0.9
|
| 208 |
+
num_gpus = math.ceil(estimated_memory_gb / usable_memory)
|
| 209 |
+
|
| 210 |
+
# Calculate costs
|
| 211 |
+
hourly_cost = num_gpus * GPU_PRICING[gpu_type]
|
| 212 |
+
daily_cost = hourly_cost * 24
|
| 213 |
+
weekly_cost = hourly_cost * 24 * 7
|
| 214 |
+
|
| 215 |
+
gpu_requirements[gpu_type] = num_gpus
|
| 216 |
+
cost_estimates[gpu_type] = {
|
| 217 |
+
"hourly": hourly_cost,
|
| 218 |
+
"daily": daily_cost,
|
| 219 |
+
"weekly": weekly_cost
|
| 220 |
+
}
|
| 221 |
+
|
| 222 |
+
return {
|
| 223 |
+
"gpu_requirements": gpu_requirements,
|
| 224 |
+
"cost_estimates": cost_estimates
|
| 225 |
+
}
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
async def capacity_estimation_node(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 229 |
+
"""
|
| 230 |
+
Estimate GPU memory for a model deployment using vLLM-based computation.
|
| 231 |
+
Handles both initial estimation and re-estimation with custom inference config.
|
| 232 |
+
"""
|
| 233 |
+
# Check if this is a re-estimation
|
| 234 |
+
is_re_estimation = state.get("needs_re_estimation", False)
|
| 235 |
+
if is_re_estimation:
|
| 236 |
+
logger.info("🔄 Starting capacity re-estimation with custom inference configuration")
|
| 237 |
+
# Reset the re-estimation flag
|
| 238 |
+
state["needs_re_estimation"] = False
|
| 239 |
+
state["capacity_approved"] = False
|
| 240 |
+
else:
|
| 241 |
+
logger.info("⚡ Starting capacity estimation node")
|
| 242 |
+
|
| 243 |
+
try:
|
| 244 |
+
model_name = state.get("model_name")
|
| 245 |
+
model_info = state.get("model_info")
|
| 246 |
+
|
| 247 |
+
if not model_name or not model_info:
|
| 248 |
+
logger.error("❌ Missing model information")
|
| 249 |
+
state["capacity_estimation_status"] = "error"
|
| 250 |
+
state["error"] = "Model information required for capacity estimation"
|
| 251 |
+
return state
|
| 252 |
+
|
| 253 |
+
# Extract safetensors info
|
| 254 |
+
dtype = model_info.get("dtype", "auto")
|
| 255 |
+
num_params = model_info.get("num_params", None)
|
| 256 |
+
|
| 257 |
+
# Extract required parameters for GPU memory estimation
|
| 258 |
+
params = {
|
| 259 |
+
"num_params": num_params,
|
| 260 |
+
"dtype": dtype,
|
| 261 |
+
"num_hidden_layers": model_info.get("num_hidden_layers"),
|
| 262 |
+
"hidden_size": model_info.get("hidden_size"),
|
| 263 |
+
"intermediate_size": model_info.get("intermediate_size"),
|
| 264 |
+
"num_key_value_heads": model_info.get("num_key_value_heads"),
|
| 265 |
+
"head_dim": model_info.get("head_dim"),
|
| 266 |
+
"max_model_len": model_info.get("max_model_len", 2048),
|
| 267 |
+
"max_num_seqs": model_info.get("max_num_seqs", 256),
|
| 268 |
+
"max_num_batched_tokens": model_info.get("max_num_batched_tokens", 2048),
|
| 269 |
+
"kv_cache_dtype": model_info.get("kv_cache_dtype", "auto"),
|
| 270 |
+
"gpu_memory_utilization": model_info.get("gpu_memory_utilization", 0.9),
|
| 271 |
+
"cpu_offload_gb": model_info.get("cpu_offload_gb", 0.0)
|
| 272 |
+
}
|
| 273 |
+
|
| 274 |
+
estimated_gpu_memory = estimate_vllm_gpu_memory(**params)
|
| 275 |
+
|
| 276 |
+
# Calculate GPU requirements and costs
|
| 277 |
+
gpu_data = calculate_gpu_requirements(estimated_gpu_memory)
|
| 278 |
+
gpu_requirements = gpu_data["gpu_requirements"]
|
| 279 |
+
cost_estimates = gpu_data["cost_estimates"]
|
| 280 |
+
|
| 281 |
+
# Store in state
|
| 282 |
+
state["estimated_gpu_memory"] = estimated_gpu_memory
|
| 283 |
+
state["gpu_requirements"] = gpu_requirements
|
| 284 |
+
state["cost_estimates"] = cost_estimates
|
| 285 |
+
state["capacity_estimation_status"] = "success"
|
| 286 |
+
|
| 287 |
+
# Build comprehensive response
|
| 288 |
+
model_size_b = num_params / 1e9 if num_params else "Unknown"
|
| 289 |
+
|
| 290 |
+
# Model architecture details
|
| 291 |
+
architecture_info = []
|
| 292 |
+
if model_info.get("num_hidden_layers"):
|
| 293 |
+
architecture_info.append(f"**Layers:** {model_info['num_hidden_layers']}")
|
| 294 |
+
if model_info.get("hidden_size"):
|
| 295 |
+
architecture_info.append(f"**Hidden Size:** {model_info['hidden_size']}")
|
| 296 |
+
if model_info.get("num_attention_heads"):
|
| 297 |
+
architecture_info.append(f"**Attention Heads:** {model_info['num_attention_heads']}")
|
| 298 |
+
if model_info.get("num_key_value_heads"):
|
| 299 |
+
architecture_info.append(f"**KV Heads:** {model_info['num_key_value_heads']}")
|
| 300 |
+
if model_info.get("intermediate_size"):
|
| 301 |
+
architecture_info.append(f"**Intermediate Size:** {model_info['intermediate_size']}")
|
| 302 |
+
if model_info.get("max_position_embeddings"):
|
| 303 |
+
architecture_info.append(f"**Max Position Embeddings:** {model_info['max_position_embeddings']}")
|
| 304 |
+
|
| 305 |
+
architecture_section = "\n ".join(architecture_info) if architecture_info else "Limited architecture information available"
|
| 306 |
+
|
| 307 |
+
# Inference configuration
|
| 308 |
+
inference_config = f"""**Max Model Length:** {params['max_model_len']}
|
| 309 |
+
**Max Sequences:** {params['max_num_seqs']}
|
| 310 |
+
**Max Batched Tokens:** {params['max_num_batched_tokens']}
|
| 311 |
+
**KV Cache dtype:** {params['kv_cache_dtype']}
|
| 312 |
+
**GPU Memory Utilization:** {params['gpu_memory_utilization']*100:.0f}%"""
|
| 313 |
+
|
| 314 |
+
# GPU requirements and cost section
|
| 315 |
+
gpu_req_lines = []
|
| 316 |
+
cost_lines = []
|
| 317 |
+
|
| 318 |
+
# Highlight RTX 4090 and 5090
|
| 319 |
+
for gpu_type in ["RTX 4090", "RTX 5090"]:
|
| 320 |
+
if gpu_type in gpu_requirements:
|
| 321 |
+
num_gpus = gpu_requirements[gpu_type]
|
| 322 |
+
gpu_memory = GPU_SPECS[gpu_type]
|
| 323 |
+
costs = cost_estimates[gpu_type]
|
| 324 |
+
|
| 325 |
+
gpu_req_lines.append(f"**{gpu_type}** ({gpu_memory}GB): **{num_gpus} GPU{'s' if num_gpus > 1 else ''}**")
|
| 326 |
+
cost_lines.append(f"**{gpu_type}:** €{costs['hourly']:.2f}/hour | €{costs['daily']:.2f}/day | €{costs['weekly']:.2f}/week")
|
| 327 |
+
|
| 328 |
+
gpu_requirements_section = "\n ".join(gpu_req_lines)
|
| 329 |
+
cost_section = "\n ".join(cost_lines)
|
| 330 |
+
|
| 331 |
+
# Build final response
|
| 332 |
+
estimation_title = "**Capacity Re-Estimation Complete**" if is_re_estimation else "**Capacity Estimation Complete**"
|
| 333 |
+
custom_note = "*Note: Re-estimated with custom inference configuration. " if is_re_estimation else "*Note: "
|
| 334 |
+
|
| 335 |
+
GPU_type = state['custom_inference_config']['GPU_type'] if is_re_estimation else model_info.get('GPU_type', 'RTX 4090')
|
| 336 |
+
location = state['custom_inference_config']['location'] if is_re_estimation else model_info.get('location', 'UAE-1')
|
| 337 |
+
|
| 338 |
+
state["response"] = f"""
|
| 339 |
+
{estimation_title}
|
| 340 |
+
|
| 341 |
+
**Model Information:**
|
| 342 |
+
**Name:** {model_name}
|
| 343 |
+
**Parameters:** {model_size_b:.2f}B
|
| 344 |
+
**Data Type:** {dtype}
|
| 345 |
+
|
| 346 |
+
**Architecture Details:**
|
| 347 |
+
{architecture_section}
|
| 348 |
+
|
| 349 |
+
**Inference Configuration:**
|
| 350 |
+
{inference_config}
|
| 351 |
+
|
| 352 |
+
**Estimated GPU Memory Required:** {estimated_gpu_memory:.2f} GB
|
| 353 |
+
|
| 354 |
+
**GPU Requirements:**
|
| 355 |
+
{gpu_requirements_section}
|
| 356 |
+
|
| 357 |
+
**Cost Estimates:**
|
| 358 |
+
{cost_section}
|
| 359 |
+
|
| 360 |
+
**Selected GPU Type:** {GPU_type}
|
| 361 |
+
**Deployment Location:** {location}
|
| 362 |
+
|
| 363 |
+
{custom_note}This estimation includes model weights, KV cache, activation peak, and a safety margin. Multi-GPU setups account for ~10% overhead for communication.*"""
|
| 364 |
+
|
| 365 |
+
logger.info(f"✅ Estimated GPU memory: {estimated_gpu_memory:.2f} GB")
|
| 366 |
+
logger.info(f"📊 GPU Requirements: RTX 4090: {gpu_requirements.get('RTX 4090', 'N/A')}, RTX 5090: {gpu_requirements.get('RTX 5090', 'N/A')}")
|
| 367 |
+
|
| 368 |
+
# Prepare state for human approval - set pending capacity approval
|
| 369 |
+
state["pending_capacity_approval"] = True
|
| 370 |
+
state["needs_re_estimation"] = False # Reset flag after processing
|
| 371 |
+
state["current_step"] = "capacity_estimation_complete"
|
| 372 |
+
|
| 373 |
+
except Exception as e:
|
| 374 |
+
logger.error(f"❌ Error in capacity estimation: {str(e)}")
|
| 375 |
+
state["capacity_estimation_status"] = "error"
|
| 376 |
+
state["error"] = str(e)
|
| 377 |
+
state["response"] = f"""❌ **Capacity Estimation Failed**
|
| 378 |
+
|
| 379 |
+
**Model:** {state.get('model_name', 'Unknown')}
|
| 380 |
+
**Error:** {str(e)}
|
| 381 |
+
|
| 382 |
+
Please check if:
|
| 383 |
+
1. The model exists on HuggingFace
|
| 384 |
+
2. You have access to the model (if it's gated)
|
| 385 |
+
3. Your HuggingFace token is valid"""
|
| 386 |
+
|
| 387 |
+
return state
|
ComputeAgent/nodes/ReAct_DeployModel/extract_model_info.py
ADDED
|
@@ -0,0 +1,291 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Extract Model Info Node
|
| 3 |
+
|
| 4 |
+
This node handles the extraction of model information from user queries.
|
| 5 |
+
It uses LLM to extract HuggingFace model names and fetches model metadata from the API.
|
| 6 |
+
|
| 7 |
+
Key Features:
|
| 8 |
+
- LLM-based model name extraction
|
| 9 |
+
- HuggingFace API integration
|
| 10 |
+
- Error handling for invalid models
|
| 11 |
+
- State management for workflow
|
| 12 |
+
|
| 13 |
+
Author: ComputeAgent Team
|
| 14 |
+
License: Private
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
import logging
|
| 18 |
+
from typing import Dict, Any, Optional
|
| 19 |
+
import json
|
| 20 |
+
import aiohttp
|
| 21 |
+
from constant import Constants
|
| 22 |
+
from models.model_manager import ModelManager
|
| 23 |
+
from langchain_core.messages import HumanMessage, SystemMessage
|
| 24 |
+
from transformers import AutoConfig
|
| 25 |
+
|
| 26 |
+
# Initialize model manager for dynamic LLM loading and management
|
| 27 |
+
model_manager = ModelManager()
|
| 28 |
+
|
| 29 |
+
logger = logging.getLogger("ExtractModelInfo")
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
async def extract_model_info_node(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 33 |
+
"""
|
| 34 |
+
Extract model information from user query and fetch model details.
|
| 35 |
+
|
| 36 |
+
This node:
|
| 37 |
+
1. Extracts model name from query using LLM
|
| 38 |
+
2. Fetches model info from HuggingFace API
|
| 39 |
+
3. Updates state with model information or error status
|
| 40 |
+
|
| 41 |
+
Args:
|
| 42 |
+
state: Current workflow state containing query
|
| 43 |
+
|
| 44 |
+
Returns:
|
| 45 |
+
Updated state with model information or extraction status
|
| 46 |
+
"""
|
| 47 |
+
logger.info("🔍 Starting model information extraction")
|
| 48 |
+
|
| 49 |
+
try:
|
| 50 |
+
# Initialize LLM
|
| 51 |
+
llm = await model_manager.load_llm_model(Constants.DEFAULT_LLM_NAME)
|
| 52 |
+
|
| 53 |
+
# Extract model name from query using LLM
|
| 54 |
+
query = state.get("query", "")
|
| 55 |
+
logger.info(f"📝 Processing query: {query}")
|
| 56 |
+
|
| 57 |
+
model_name = await extract_model_name_with_llm(query, llm)
|
| 58 |
+
|
| 59 |
+
if model_name == "UNKNOWN" or not model_name:
|
| 60 |
+
logger.info("❓ Model name not found, will need generation")
|
| 61 |
+
state["model_extraction_status"] = "unknown"
|
| 62 |
+
state["needs_generation"] = True
|
| 63 |
+
return state
|
| 64 |
+
|
| 65 |
+
logger.info(f"📋 Extracted model name: {model_name}")
|
| 66 |
+
|
| 67 |
+
# Fetch model information
|
| 68 |
+
model_info = await fetch_huggingface_model_info_for_memory(model_name, llm)
|
| 69 |
+
|
| 70 |
+
if "error" in model_info:
|
| 71 |
+
logger.error(f"❌ Error fetching model info: {model_info['error']}")
|
| 72 |
+
state["model_extraction_status"] = "error"
|
| 73 |
+
state["error"] = model_info["error"]
|
| 74 |
+
return state
|
| 75 |
+
|
| 76 |
+
# Success - update state with model information
|
| 77 |
+
state["model_name"] = model_name
|
| 78 |
+
state["model_info"] = model_info
|
| 79 |
+
state["model_extraction_status"] = "success"
|
| 80 |
+
state["needs_generation"] = False
|
| 81 |
+
|
| 82 |
+
logger.info(f"✅ Successfully extracted model info for {model_name}")
|
| 83 |
+
return state
|
| 84 |
+
|
| 85 |
+
except Exception as e:
|
| 86 |
+
logger.error(f"❌ Error during model info extraction: {str(e)}")
|
| 87 |
+
state["model_extraction_status"] = "error"
|
| 88 |
+
state["error"] = f"Model info extraction failed: {str(e)}"
|
| 89 |
+
return state
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
async def extract_model_name_with_llm(query: str, llm) -> str:
|
| 93 |
+
"""
|
| 94 |
+
Use LLM to extract HuggingFace model name from user query.
|
| 95 |
+
|
| 96 |
+
Args:
|
| 97 |
+
query: User's natural language query
|
| 98 |
+
llm: LangChain LLM instance
|
| 99 |
+
|
| 100 |
+
Returns:
|
| 101 |
+
Extracted model name in format 'owner/model-name' or None
|
| 102 |
+
"""
|
| 103 |
+
system_prompt = """
|
| 104 |
+
You are an expert at extracting HuggingFace model names from user queries.
|
| 105 |
+
|
| 106 |
+
Extract the exact HuggingFace model identifier in the format 'owner/model-name'.
|
| 107 |
+
NEVER fabricate or guess model names. Only extract what is explicitly mentioned in the query.
|
| 108 |
+
|
| 109 |
+
Rule for the UNKNOWN response:
|
| 110 |
+
- If the model name is written but not the owner, respond with 'UNKNOWN'.
|
| 111 |
+
- If the owner is written but not the model name, respond with 'UNKNOWN'.
|
| 112 |
+
|
| 113 |
+
Only respond with the model identifier, nothing else.
|
| 114 |
+
"""
|
| 115 |
+
|
| 116 |
+
messages = [
|
| 117 |
+
SystemMessage(content=system_prompt),
|
| 118 |
+
HumanMessage(content=f"Extract the HuggingFace model name from: {query}")
|
| 119 |
+
]
|
| 120 |
+
|
| 121 |
+
response = await llm.ainvoke(messages)
|
| 122 |
+
model_name = response.content.strip()
|
| 123 |
+
|
| 124 |
+
if model_name == "UNKNOWN":
|
| 125 |
+
return None
|
| 126 |
+
|
| 127 |
+
return model_name
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
async def extract_model_dtype_with_llm(model_name: str, parameters_dict: dict, llm) -> Optional[str]:
|
| 131 |
+
"""
|
| 132 |
+
Use LLM to extract the correct dtype from model name and available parameters.
|
| 133 |
+
|
| 134 |
+
Args:
|
| 135 |
+
model_name: HuggingFace model name in format 'owner/model-name'
|
| 136 |
+
parameters_dict: Available dtypes and their parameter counts from HF API
|
| 137 |
+
llm: LangChain LLM instance
|
| 138 |
+
|
| 139 |
+
Returns:
|
| 140 |
+
Matching dtype key from parameters_dict or None if cannot be determined
|
| 141 |
+
"""
|
| 142 |
+
system_prompt = f"""
|
| 143 |
+
You are an expert at identifying data types from HuggingFace model names.
|
| 144 |
+
|
| 145 |
+
Given a model name and available dtype options, determine which dtype the model uses.
|
| 146 |
+
|
| 147 |
+
Available dtypes: {json.dumps(list(parameters_dict.keys()))}
|
| 148 |
+
|
| 149 |
+
Rules:
|
| 150 |
+
- Analyze the model name for dtype indicators (FP8, BF16, INT4, INT8, FP16, etc.)
|
| 151 |
+
- If no dtype indicator is found in the model name by default is BF16 on the model name side.
|
| 152 |
+
- Return ONLY the dtype key that exists in the available options, nothing else
|
| 153 |
+
|
| 154 |
+
Only respond with the dtype key or 'UNKNOWN', nothing else.
|
| 155 |
+
"""
|
| 156 |
+
|
| 157 |
+
messages = [
|
| 158 |
+
SystemMessage(content=system_prompt),
|
| 159 |
+
HumanMessage(content=f"Extract the dtype from model name: {model_name}")
|
| 160 |
+
]
|
| 161 |
+
|
| 162 |
+
response = await llm.ainvoke(messages)
|
| 163 |
+
dtype = response.content.strip()
|
| 164 |
+
|
| 165 |
+
# Validate that the returned dtype exists in parameters_dict
|
| 166 |
+
if dtype not in parameters_dict:
|
| 167 |
+
logger.warning(f"LLM returned dtype '{dtype}' not in available options: {list(parameters_dict.keys())}")
|
| 168 |
+
return None
|
| 169 |
+
|
| 170 |
+
return dtype
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
async def fetch_huggingface_model_info(model_name: str) -> Dict[str, Any]:
|
| 174 |
+
"""
|
| 175 |
+
Fetch model information from HuggingFace API.
|
| 176 |
+
|
| 177 |
+
Args:
|
| 178 |
+
model_name: HuggingFace model identifier (e.g., 'meta-llama/Meta-Llama-3-70B')
|
| 179 |
+
|
| 180 |
+
Returns:
|
| 181 |
+
Dictionary containing model information
|
| 182 |
+
"""
|
| 183 |
+
api_url = f"https://huggingface.co/api/models/{model_name}"
|
| 184 |
+
|
| 185 |
+
async with aiohttp.ClientSession() as session:
|
| 186 |
+
try:
|
| 187 |
+
async with session.get(api_url) as response:
|
| 188 |
+
if response.status == 200:
|
| 189 |
+
model_info = await response.json()
|
| 190 |
+
logger.info(f"✅ Successfully fetched model info for {model_name}")
|
| 191 |
+
return model_info
|
| 192 |
+
elif response.status == 404:
|
| 193 |
+
logger.error(f"❌ Model not found: {model_name}")
|
| 194 |
+
return {"error": "Model not found", "status": 404}
|
| 195 |
+
else:
|
| 196 |
+
logger.error(f"❌ API error: {response.status}")
|
| 197 |
+
return {"error": f"API error: {response.status}", "status": response.status}
|
| 198 |
+
except Exception as e:
|
| 199 |
+
logger.error(f"❌ Exception while fetching model info: {str(e)}")
|
| 200 |
+
return {"error": str(e)}
|
| 201 |
+
|
| 202 |
+
async def fetch_huggingface_model_info_for_memory(model_name: str, llm) -> Dict[str, Any]:
|
| 203 |
+
"""
|
| 204 |
+
Fetch only the information needed for GPU memory estimation from HuggingFace.
|
| 205 |
+
|
| 206 |
+
Returns a dictionary containing:
|
| 207 |
+
- num_params
|
| 208 |
+
- dtype
|
| 209 |
+
- num_hidden_layers
|
| 210 |
+
- hidden_size
|
| 211 |
+
- intermediate_size
|
| 212 |
+
- num_attention_heads
|
| 213 |
+
- head_dim
|
| 214 |
+
- max_position_embeddings
|
| 215 |
+
"""
|
| 216 |
+
result: Dict[str, Any] = {}
|
| 217 |
+
|
| 218 |
+
# Step 1: Fetch metadata from HuggingFace API
|
| 219 |
+
api_url = f"https://huggingface.co/api/models/{model_name}"
|
| 220 |
+
async with aiohttp.ClientSession() as session:
|
| 221 |
+
try:
|
| 222 |
+
async with session.get(api_url) as response:
|
| 223 |
+
if response.status == 200:
|
| 224 |
+
metadata = await response.json()
|
| 225 |
+
else:
|
| 226 |
+
logger.error(f"❌ API error {response.status} for {model_name}")
|
| 227 |
+
return {}
|
| 228 |
+
except Exception as e:
|
| 229 |
+
logger.error(f"❌ Exception fetching metadata for {model_name}: {str(e)}")
|
| 230 |
+
return {}
|
| 231 |
+
|
| 232 |
+
# Extract num_params and dtype
|
| 233 |
+
safetensors = metadata.get("safetensors", {})
|
| 234 |
+
parameters_dict = safetensors.get("parameters", {})
|
| 235 |
+
|
| 236 |
+
result["location"] = "UAE-1" # Default location
|
| 237 |
+
result["GPU_type"] = "RTX4090" # Default GPU type
|
| 238 |
+
|
| 239 |
+
# Usage in your main code:
|
| 240 |
+
if parameters_dict:
|
| 241 |
+
result["dtype"] = await extract_model_dtype_with_llm(model_name, parameters_dict, llm)
|
| 242 |
+
|
| 243 |
+
if result["dtype"]:
|
| 244 |
+
result["num_params"] = parameters_dict[result["dtype"]]
|
| 245 |
+
logger.info(f"✓ LLM selected dtype: {result['dtype']}")
|
| 246 |
+
else:
|
| 247 |
+
# Fallback to first available if LLM couldn't determine
|
| 248 |
+
result["dtype"] = next(iter(parameters_dict.keys()))
|
| 249 |
+
result["num_params"] = parameters_dict[result["dtype"]]
|
| 250 |
+
logger.warning(f"⚠ Using fallback dtype: {result['dtype']}")
|
| 251 |
+
else:
|
| 252 |
+
result["dtype"] = "auto"
|
| 253 |
+
result["num_params"] = metadata.get("num_params") or safetensors.get("total")
|
| 254 |
+
|
| 255 |
+
# Step 2: Fetch model config via transformers
|
| 256 |
+
# Step 2: Fetch model config via transformers
|
| 257 |
+
try:
|
| 258 |
+
# Check if token is available
|
| 259 |
+
token = Constants.HF_TOKEN if hasattr(Constants, 'HF_TOKEN') and Constants.HF_TOKEN else None
|
| 260 |
+
|
| 261 |
+
if not token:
|
| 262 |
+
logger.warning(f"⚠️ No HF_TOKEN provided for {model_name}")
|
| 263 |
+
|
| 264 |
+
config = AutoConfig.from_pretrained(
|
| 265 |
+
model_name,
|
| 266 |
+
token=token,
|
| 267 |
+
trust_remote_code=True # Add this if model uses custom code
|
| 268 |
+
)
|
| 269 |
+
|
| 270 |
+
result.update({
|
| 271 |
+
"num_hidden_layers": getattr(config, "num_hidden_layers", None),
|
| 272 |
+
"hidden_size": getattr(config, "hidden_size", None),
|
| 273 |
+
"intermediate_size": getattr(config, "intermediate_size", None),
|
| 274 |
+
"num_attention_heads": getattr(config, "num_attention_heads", None),
|
| 275 |
+
"num_key_value_heads": getattr(config, "num_key_value_heads", None), # Added
|
| 276 |
+
"max_position_embeddings": getattr(config, "max_position_embeddings", None),
|
| 277 |
+
})
|
| 278 |
+
|
| 279 |
+
# Fallback: if num_key_value_heads is not available, use num_attention_heads
|
| 280 |
+
if result["num_key_value_heads"] is None and result["num_attention_heads"] is not None:
|
| 281 |
+
result["num_key_value_heads"] = result["num_attention_heads"]
|
| 282 |
+
logger.info(f"ℹ️ Using num_attention_heads as num_key_value_heads for {model_name}")
|
| 283 |
+
|
| 284 |
+
# Optional: compute head_dim
|
| 285 |
+
if result["hidden_size"] and result["num_attention_heads"]:
|
| 286 |
+
result["head_dim"] = result["hidden_size"] // result["num_attention_heads"]
|
| 287 |
+
|
| 288 |
+
except Exception as e:
|
| 289 |
+
logger.warning(f"⚠️ Could not fetch model config for {model_name}: {str(e)}")
|
| 290 |
+
|
| 291 |
+
return result
|
ComputeAgent/nodes/ReAct_DeployModel/generate_additional_info.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Generate Model Name Node
|
| 3 |
+
|
| 4 |
+
This node handles the generation of model names when the initial extraction fails.
|
| 5 |
+
It uses LLM to suggest appropriate model names based on user requirements.
|
| 6 |
+
|
| 7 |
+
Key Features:
|
| 8 |
+
- LLM-based model name generation
|
| 9 |
+
- Context-aware suggestions
|
| 10 |
+
- Fallback mechanisms
|
| 11 |
+
- State management for workflow
|
| 12 |
+
|
| 13 |
+
Author: ComputeAgent Team
|
| 14 |
+
License: Private
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
import logging
|
| 18 |
+
from typing import Dict, Any
|
| 19 |
+
from constant import Constants
|
| 20 |
+
from models.model_manager import ModelManager
|
| 21 |
+
from langchain_core.messages import HumanMessage, SystemMessage
|
| 22 |
+
|
| 23 |
+
# Initialize model manager for dynamic LLM loading and management
|
| 24 |
+
model_manager = ModelManager()
|
| 25 |
+
|
| 26 |
+
logger = logging.getLogger("GenerateModelName")
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
async def generate_additional_info_node(state: Dict[str, Any]) -> Dict[str, Any]:
|
| 30 |
+
"""
|
| 31 |
+
Generate helpful response with model suggestions when model info is not available.
|
| 32 |
+
|
| 33 |
+
Path 1A: No Info Case
|
| 34 |
+
This node:
|
| 35 |
+
1. Analyzes the user query for requirements
|
| 36 |
+
2. Generates appropriate model name suggestions
|
| 37 |
+
3. Creates a helpful response asking for more details
|
| 38 |
+
|
| 39 |
+
Args:
|
| 40 |
+
state: Current workflow state containing query and extraction status
|
| 41 |
+
|
| 42 |
+
Returns:
|
| 43 |
+
Updated state with helpful response and suggestions
|
| 44 |
+
"""
|
| 45 |
+
logger.info("🎯 Path 1A: Generating helpful response with model suggestions")
|
| 46 |
+
|
| 47 |
+
try:
|
| 48 |
+
# Initialize LLM
|
| 49 |
+
llm = await model_manager.load_llm_model(Constants.DEFAULT_LLM_NAME)
|
| 50 |
+
|
| 51 |
+
# Generate model name suggestions based on query
|
| 52 |
+
query = state.get("query", "")
|
| 53 |
+
logger.info(f"📝 Generating helpful response for query: {query}")
|
| 54 |
+
|
| 55 |
+
system_prompt = """The user provide a model that cannot be found.
|
| 56 |
+
Your task is to generate a helpful response asking the user for more detailsabut the HuggingFace models.
|
| 57 |
+
Instruct the user to provide the exact model name in the format:
|
| 58 |
+
|
| 59 |
+
owner/model-name
|
| 60 |
+
|
| 61 |
+
Do NOT suggest, guess, or provide any instructions or steps for any model.
|
| 62 |
+
I will respond ONLY after receiving the exact model name.
|
| 63 |
+
Be polite and concise in your response."""
|
| 64 |
+
|
| 65 |
+
messages = [
|
| 66 |
+
SystemMessage(content=system_prompt),
|
| 67 |
+
HumanMessage(content=f"{query}")
|
| 68 |
+
]
|
| 69 |
+
|
| 70 |
+
response = await llm.ainvoke(messages)
|
| 71 |
+
|
| 72 |
+
state["generation_status"] = "completed_with_suggestions"
|
| 73 |
+
state["response"] = response.content
|
| 74 |
+
logger.info(f"✅ Generated helpful response")
|
| 75 |
+
|
| 76 |
+
return state
|
| 77 |
+
|
| 78 |
+
except Exception as e:
|
| 79 |
+
logger.error(f"❌ Error during response generation: {str(e)}")
|
| 80 |
+
state["generation_status"] = "error"
|
| 81 |
+
state["error"] = f"Response generation failed: {str(e)}"
|
| 82 |
+
state["response"] = "I encountered an error while trying to help with model suggestions. Please provide the exact HuggingFace model name in the format 'owner/model-name'."
|
| 83 |
+
return state
|
ComputeAgent/nodes/__init__.py
ADDED
|
File without changes
|
ComputeAgent/routers/compute_agent_HITL.py
ADDED
|
@@ -0,0 +1,590 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Complete ComputeAgent API Router with Full Approval Support
|
| 3 |
+
|
| 4 |
+
This router handles BOTH capacity approval and tool approval using LangGraph interrupts.
|
| 5 |
+
|
| 6 |
+
Features:
|
| 7 |
+
- Capacity approval (GPU estimation)
|
| 8 |
+
- Tool approval (tool execution control)
|
| 9 |
+
- Tool argument modification
|
| 10 |
+
- Agent re-reasoning
|
| 11 |
+
- Re-estimation support
|
| 12 |
+
|
| 13 |
+
Endpoints:
|
| 14 |
+
- POST /api/compute/query - Start a query (may pause at interrupt)
|
| 15 |
+
- POST /api/compute/continue/{thread_id} - Resume after capacity approval
|
| 16 |
+
- POST /api/compute/approve-tools - Handle tool approval decisions
|
| 17 |
+
- GET /api/compute/state/{thread_id} - Get current state
|
| 18 |
+
- GET /api/compute/health - Health check
|
| 19 |
+
|
| 20 |
+
Author: ComputeAgent Team
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
import json
|
| 24 |
+
import logging
|
| 25 |
+
from typing import Dict, Any, Optional, List
|
| 26 |
+
from datetime import datetime
|
| 27 |
+
|
| 28 |
+
from fastapi import APIRouter, HTTPException, Request
|
| 29 |
+
from fastapi.responses import JSONResponse
|
| 30 |
+
from pydantic import BaseModel, Field
|
| 31 |
+
from langgraph.types import Command
|
| 32 |
+
|
| 33 |
+
# Import ComputeAgent
|
| 34 |
+
from graph.graph import ComputeAgent
|
| 35 |
+
from constant import Constants
|
| 36 |
+
|
| 37 |
+
# Initialize logger
|
| 38 |
+
logger = logging.getLogger("ComputeAgent Router")
|
| 39 |
+
|
| 40 |
+
# Create the API router
|
| 41 |
+
compute_agent_router = APIRouter(prefix="/api/compute", tags=["compute_agent"])
|
| 42 |
+
|
| 43 |
+
# Initialize the Agent
|
| 44 |
+
agent: Optional[ComputeAgent] = None
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
async def initialize_agent():
|
| 48 |
+
"""Initialize the ComputeAgent instance asynchronously."""
|
| 49 |
+
global agent
|
| 50 |
+
try:
|
| 51 |
+
logger.info("🚀 Initializing ComputeAgent...")
|
| 52 |
+
agent = await ComputeAgent.create()
|
| 53 |
+
logger.info("✅ ComputeAgent initialized successfully")
|
| 54 |
+
|
| 55 |
+
# Disabled to prevent HF Spaces file watcher from triggering restarts
|
| 56 |
+
# try:
|
| 57 |
+
# agent.draw_graph("compute_agent_graph.png")
|
| 58 |
+
# logger.info("📊 Graph visualization generated")
|
| 59 |
+
# except Exception as e:
|
| 60 |
+
# logger.warning(f"Could not generate graph visualization: {e}")
|
| 61 |
+
|
| 62 |
+
HUMAN_APPROVAL_CAPACITY = True if Constants.HUMAN_APPROVAL_CAPACITY == "true" else False
|
| 63 |
+
HUMAN_APPROVAL = True if Constants.HUMAN_APPROVAL == "true" else False
|
| 64 |
+
logger.info(f"👤 Human Approval: {'ENABLED' if HUMAN_APPROVAL else 'DISABLED'}")
|
| 65 |
+
logger.info(f"⚙️ Capacity Approval: {'ENABLED' if HUMAN_APPROVAL_CAPACITY else 'DISABLED'}")
|
| 66 |
+
|
| 67 |
+
return agent
|
| 68 |
+
|
| 69 |
+
except Exception as e:
|
| 70 |
+
logger.error(f"❌ Failed to initialize ComputeAgent: {e}")
|
| 71 |
+
raise
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def get_agent() -> ComputeAgent:
|
| 75 |
+
"""Get the initialized agent instance."""
|
| 76 |
+
if agent is None:
|
| 77 |
+
raise HTTPException(
|
| 78 |
+
status_code=503,
|
| 79 |
+
detail="ComputeAgent not initialized. Please restart the application."
|
| 80 |
+
)
|
| 81 |
+
return agent
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
# ============================================================================
|
| 85 |
+
# REQUEST/RESPONSE MODELS
|
| 86 |
+
# ============================================================================
|
| 87 |
+
|
| 88 |
+
class QueryRequest(BaseModel):
|
| 89 |
+
"""Request model for agent queries"""
|
| 90 |
+
query: str = Field(..., description="User query to process")
|
| 91 |
+
user_id: str = Field(default="default_user", description="User identifier")
|
| 92 |
+
session_id: str = Field(default="default_session", description="Session identifier")
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
class QueryResponse(BaseModel):
|
| 96 |
+
"""Response model for agent queries"""
|
| 97 |
+
success: bool
|
| 98 |
+
thread_id: str
|
| 99 |
+
response: str
|
| 100 |
+
agent_decision: str = ""
|
| 101 |
+
current_step: str = ""
|
| 102 |
+
state: str # "waiting_for_input" or "completed"
|
| 103 |
+
approval_type: Optional[str] = None # "capacity" or "tool"
|
| 104 |
+
interrupt_data: Optional[Dict[str, Any]] = None
|
| 105 |
+
deployment_result: Optional[Dict[str, Any]] = None
|
| 106 |
+
react_results: Optional[Dict[str, Any]] = None
|
| 107 |
+
error: Optional[str] = None
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
class CapacityApprovalRequest(BaseModel):
|
| 111 |
+
"""Request model for capacity approval"""
|
| 112 |
+
capacity_approved: Optional[bool] = Field(None, description="Whether to approve capacity")
|
| 113 |
+
needs_re_estimation: Optional[bool] = Field(False, description="Whether to re-estimate")
|
| 114 |
+
custom_config: Optional[Dict[str, Any]] = Field(default_factory=dict, description="Custom config")
|
| 115 |
+
|
| 116 |
+
class Config:
|
| 117 |
+
json_schema_extra = {
|
| 118 |
+
"examples": [
|
| 119 |
+
{
|
| 120 |
+
"capacity_approved": True,
|
| 121 |
+
"needs_re_estimation": False,
|
| 122 |
+
"custom_config": {}
|
| 123 |
+
},
|
| 124 |
+
{
|
| 125 |
+
"capacity_approved": None,
|
| 126 |
+
"needs_re_estimation": True,
|
| 127 |
+
"custom_config": {
|
| 128 |
+
"max_model_len": 4096,
|
| 129 |
+
"GPU_type": "RTX 5090"
|
| 130 |
+
}
|
| 131 |
+
}
|
| 132 |
+
]
|
| 133 |
+
}
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
class ToolApprovalRequest(BaseModel):
|
| 137 |
+
"""Request model for tool approval"""
|
| 138 |
+
thread_id: str = Field(..., description="Thread ID")
|
| 139 |
+
action: str = Field(..., description="Action: approve_all, reject_all, approve_selected, modify_and_approve, request_re_reasoning")
|
| 140 |
+
tool_indices: Optional[List[int]] = Field(None, description="Tool indices for selective approval")
|
| 141 |
+
modifications: Optional[List[Dict[str, Any]]] = Field(None, description="Tool modifications")
|
| 142 |
+
feedback: Optional[str] = Field(None, description="Feedback for re-reasoning")
|
| 143 |
+
|
| 144 |
+
class Config:
|
| 145 |
+
json_schema_extra = {
|
| 146 |
+
"examples": [
|
| 147 |
+
{
|
| 148 |
+
"thread_id": "user_session_123",
|
| 149 |
+
"action": "approve_all"
|
| 150 |
+
},
|
| 151 |
+
{
|
| 152 |
+
"thread_id": "user_session_123",
|
| 153 |
+
"action": "approve_selected",
|
| 154 |
+
"tool_indices": [0, 2]
|
| 155 |
+
},
|
| 156 |
+
{
|
| 157 |
+
"thread_id": "user_session_123",
|
| 158 |
+
"action": "modify_and_approve",
|
| 159 |
+
"modifications": [
|
| 160 |
+
{
|
| 161 |
+
"tool_index": 0,
|
| 162 |
+
"new_args": {"query": "modified search"},
|
| 163 |
+
"approve": True
|
| 164 |
+
}
|
| 165 |
+
]
|
| 166 |
+
},
|
| 167 |
+
{
|
| 168 |
+
"thread_id": "user_session_123",
|
| 169 |
+
"action": "request_re_reasoning",
|
| 170 |
+
"feedback": "Please search academic papers instead"
|
| 171 |
+
}
|
| 172 |
+
]
|
| 173 |
+
}
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
class HealthResponse(BaseModel):
|
| 177 |
+
"""Response model for health check"""
|
| 178 |
+
status: str
|
| 179 |
+
agent_initialized: bool
|
| 180 |
+
human_approval_enabled: bool
|
| 181 |
+
capacity_approval_enabled: bool
|
| 182 |
+
timestamp: str
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
# ============================================================================
|
| 186 |
+
# HELPER FUNCTIONS
|
| 187 |
+
# ============================================================================
|
| 188 |
+
|
| 189 |
+
def _determine_approval_type(interrupt_data: Dict[str, Any]) -> str:
|
| 190 |
+
"""Determine if this is capacity or tool approval."""
|
| 191 |
+
if "tool_calls" in interrupt_data:
|
| 192 |
+
return "tool"
|
| 193 |
+
elif "model_name" in interrupt_data and "estimated_gpu_memory" in interrupt_data:
|
| 194 |
+
return "capacity"
|
| 195 |
+
return "unknown"
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
def _create_success_response(
|
| 199 |
+
thread_id: str,
|
| 200 |
+
state: Dict[str, Any],
|
| 201 |
+
completed: bool = True
|
| 202 |
+
) -> QueryResponse:
|
| 203 |
+
"""Create a success response from state."""
|
| 204 |
+
return QueryResponse(
|
| 205 |
+
success=not bool(state.get("error")),
|
| 206 |
+
thread_id=thread_id,
|
| 207 |
+
response=state.get("response", "Request completed" if completed else "Waiting for approval"),
|
| 208 |
+
agent_decision=state.get("agent_decision", ""),
|
| 209 |
+
current_step=state.get("current_step", ""),
|
| 210 |
+
state="completed" if completed else "waiting_for_input",
|
| 211 |
+
approval_type=None,
|
| 212 |
+
interrupt_data=None,
|
| 213 |
+
deployment_result=state.get("deployment_result"),
|
| 214 |
+
react_results=state.get("react_results"),
|
| 215 |
+
error=state.get("error")
|
| 216 |
+
)
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
def _create_interrupt_response(
|
| 220 |
+
thread_id: str,
|
| 221 |
+
state: Dict[str, Any],
|
| 222 |
+
interrupt_data: Dict[str, Any],
|
| 223 |
+
approval_type: str
|
| 224 |
+
) -> QueryResponse:
|
| 225 |
+
"""Create an interrupt response."""
|
| 226 |
+
return QueryResponse(
|
| 227 |
+
success=True,
|
| 228 |
+
thread_id=thread_id,
|
| 229 |
+
response="Waiting for approval",
|
| 230 |
+
agent_decision=state.get("agent_decision", ""),
|
| 231 |
+
current_step=state.get("current_step", ""),
|
| 232 |
+
state="waiting_for_input",
|
| 233 |
+
approval_type=approval_type,
|
| 234 |
+
interrupt_data=interrupt_data,
|
| 235 |
+
deployment_result=None,
|
| 236 |
+
react_results=None,
|
| 237 |
+
error=None
|
| 238 |
+
)
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
# ============================================================================
|
| 242 |
+
# MAIN ENDPOINTS
|
| 243 |
+
# ============================================================================
|
| 244 |
+
|
| 245 |
+
@compute_agent_router.get("/health", response_model=HealthResponse)
|
| 246 |
+
async def health_check():
|
| 247 |
+
"""Health check endpoint."""
|
| 248 |
+
return HealthResponse(
|
| 249 |
+
status="healthy" if agent is not None else "unhealthy",
|
| 250 |
+
agent_initialized=agent is not None,
|
| 251 |
+
human_approval_enabled=Constants.HUMAN_APPROVAL,
|
| 252 |
+
capacity_approval_enabled=Constants.HUMAN_APPROVAL_CAPACITY,
|
| 253 |
+
timestamp=datetime.now().isoformat()
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
|
| 257 |
+
@compute_agent_router.post("/query", response_model=QueryResponse)
|
| 258 |
+
async def process_query(request: QueryRequest):
|
| 259 |
+
"""
|
| 260 |
+
Process a user query through the ComputeAgent.
|
| 261 |
+
|
| 262 |
+
Returns:
|
| 263 |
+
- If interrupted: state="waiting_for_input" with approval_type and interrupt_data
|
| 264 |
+
- If completed: state="completed" with final response
|
| 265 |
+
"""
|
| 266 |
+
current_agent = get_agent()
|
| 267 |
+
|
| 268 |
+
try:
|
| 269 |
+
logger.info(f"📥 Processing query for {request.user_id}:{request.session_id}")
|
| 270 |
+
logger.info(f"🔍 Query: {request.query}")
|
| 271 |
+
|
| 272 |
+
thread_id = f"{request.user_id}_{request.session_id}"
|
| 273 |
+
thread_config = {"configurable": {"thread_id": thread_id}}
|
| 274 |
+
|
| 275 |
+
# Check if there's existing conversation state for this thread
|
| 276 |
+
try:
|
| 277 |
+
existing_state = current_agent.graph.get_state(thread_config)
|
| 278 |
+
if existing_state and existing_state.values:
|
| 279 |
+
logger.info(f"📚 Found existing conversation state for {thread_id}")
|
| 280 |
+
# Update existing state with new query, preserve conversation history
|
| 281 |
+
initial_state = existing_state.values.copy()
|
| 282 |
+
initial_state["query"] = request.query
|
| 283 |
+
initial_state["current_step"] = "start"
|
| 284 |
+
logger.info(f"📝 Preserving {len(initial_state.get('messages', []))} previous messages")
|
| 285 |
+
else:
|
| 286 |
+
logger.info(f"🆕 Starting new conversation for {thread_id}")
|
| 287 |
+
# Create fresh state for new conversation
|
| 288 |
+
initial_state = {
|
| 289 |
+
"query": request.query,
|
| 290 |
+
"user_id": request.user_id,
|
| 291 |
+
"session_id": request.session_id,
|
| 292 |
+
"response": "",
|
| 293 |
+
"current_step": "start",
|
| 294 |
+
"agent_decision": "",
|
| 295 |
+
"deployment_approved": False,
|
| 296 |
+
"model_name": "",
|
| 297 |
+
"model_card": {},
|
| 298 |
+
"model_info": {},
|
| 299 |
+
"capacity_estimate": {},
|
| 300 |
+
"deployment_result": {},
|
| 301 |
+
"react_results": {},
|
| 302 |
+
"tool_calls": [],
|
| 303 |
+
"tool_results": [],
|
| 304 |
+
"messages": [],
|
| 305 |
+
# Add approval state fields
|
| 306 |
+
"pending_tool_calls": [],
|
| 307 |
+
"approved_tool_calls": [],
|
| 308 |
+
"rejected_tool_calls": [],
|
| 309 |
+
"modified_tool_calls": [],
|
| 310 |
+
"needs_re_reasoning": False,
|
| 311 |
+
"re_reasoning_feedback": ""
|
| 312 |
+
}
|
| 313 |
+
except Exception as e:
|
| 314 |
+
logger.warning(f"⚠️ Could not load existing state: {e}, starting fresh")
|
| 315 |
+
initial_state = {
|
| 316 |
+
"query": request.query,
|
| 317 |
+
"user_id": request.user_id,
|
| 318 |
+
"session_id": request.session_id,
|
| 319 |
+
"response": "",
|
| 320 |
+
"current_step": "start",
|
| 321 |
+
"agent_decision": "",
|
| 322 |
+
"deployment_approved": False,
|
| 323 |
+
"model_name": "",
|
| 324 |
+
"model_card": {},
|
| 325 |
+
"model_info": {},
|
| 326 |
+
"capacity_estimate": {},
|
| 327 |
+
"deployment_result": {},
|
| 328 |
+
"react_results": {},
|
| 329 |
+
"tool_calls": [],
|
| 330 |
+
"tool_results": [],
|
| 331 |
+
"messages": [],
|
| 332 |
+
"pending_tool_calls": [],
|
| 333 |
+
"approved_tool_calls": [],
|
| 334 |
+
"rejected_tool_calls": [],
|
| 335 |
+
"modified_tool_calls": [],
|
| 336 |
+
"needs_re_reasoning": False,
|
| 337 |
+
"re_reasoning_feedback": ""
|
| 338 |
+
}
|
| 339 |
+
|
| 340 |
+
# Invoke the graph
|
| 341 |
+
await current_agent.graph.ainvoke(initial_state, config=thread_config)
|
| 342 |
+
|
| 343 |
+
# Get the updated state
|
| 344 |
+
graph_state = current_agent.graph.get_state(thread_config)
|
| 345 |
+
current_state = graph_state.values if graph_state.values else {}
|
| 346 |
+
|
| 347 |
+
# Check if interrupted
|
| 348 |
+
if graph_state.tasks and graph_state.tasks[0].interrupts:
|
| 349 |
+
interrupt_value = graph_state.tasks[0].interrupts[0].value
|
| 350 |
+
approval_type = _determine_approval_type(interrupt_value)
|
| 351 |
+
|
| 352 |
+
logger.info(f"⏸️ Graph paused for {approval_type} approval")
|
| 353 |
+
|
| 354 |
+
return _create_interrupt_response(
|
| 355 |
+
thread_id,
|
| 356 |
+
current_state,
|
| 357 |
+
interrupt_value,
|
| 358 |
+
approval_type
|
| 359 |
+
)
|
| 360 |
+
|
| 361 |
+
# Normal completion
|
| 362 |
+
logger.info(f"✅ Query completed")
|
| 363 |
+
return _create_success_response(thread_id, current_state, completed=True)
|
| 364 |
+
|
| 365 |
+
except Exception as e:
|
| 366 |
+
logger.error(f"❌ Error processing query: {e}", exc_info=True)
|
| 367 |
+
raise HTTPException(status_code=500, detail=f"Error processing query: {str(e)}")
|
| 368 |
+
|
| 369 |
+
|
| 370 |
+
@compute_agent_router.post("/continue/{thread_id}")
|
| 371 |
+
async def continue_after_capacity_approval(
|
| 372 |
+
thread_id: str,
|
| 373 |
+
approval: CapacityApprovalRequest
|
| 374 |
+
):
|
| 375 |
+
"""
|
| 376 |
+
Continue execution after capacity approval.
|
| 377 |
+
|
| 378 |
+
Handles:
|
| 379 |
+
- Approve capacity (capacity_approved=True)
|
| 380 |
+
- Reject capacity (capacity_approved=False)
|
| 381 |
+
- Re-estimate (needs_re_estimation=True with custom_config)
|
| 382 |
+
"""
|
| 383 |
+
current_agent = get_agent()
|
| 384 |
+
|
| 385 |
+
try:
|
| 386 |
+
logger.info(f"▶️ Continuing after capacity approval for thread {thread_id}")
|
| 387 |
+
logger.info(f" Approved: {approval.capacity_approved}")
|
| 388 |
+
logger.info(f" Re-estimate: {approval.needs_re_estimation}")
|
| 389 |
+
|
| 390 |
+
thread_config = {"configurable": {"thread_id": thread_id}}
|
| 391 |
+
|
| 392 |
+
# Prepare user input
|
| 393 |
+
user_input = {
|
| 394 |
+
"capacity_approved": approval.capacity_approved,
|
| 395 |
+
"needs_re_estimation": approval.needs_re_estimation,
|
| 396 |
+
"custom_config": approval.custom_config or {}
|
| 397 |
+
}
|
| 398 |
+
|
| 399 |
+
# Resume execution
|
| 400 |
+
await current_agent.graph.ainvoke(
|
| 401 |
+
Command(resume=user_input),
|
| 402 |
+
config=thread_config
|
| 403 |
+
)
|
| 404 |
+
|
| 405 |
+
# Get updated state
|
| 406 |
+
graph_state = current_agent.graph.get_state(thread_config)
|
| 407 |
+
current_state = graph_state.values if graph_state.values else {}
|
| 408 |
+
|
| 409 |
+
# Check if still interrupted (e.g., after re-estimation)
|
| 410 |
+
if graph_state.tasks and graph_state.tasks[0].interrupts:
|
| 411 |
+
interrupt_value = graph_state.tasks[0].interrupts[0].value
|
| 412 |
+
approval_type = _determine_approval_type(interrupt_value)
|
| 413 |
+
|
| 414 |
+
logger.info(f"⏸️ Still interrupted for {approval_type} approval")
|
| 415 |
+
|
| 416 |
+
return _create_interrupt_response(
|
| 417 |
+
thread_id,
|
| 418 |
+
current_state,
|
| 419 |
+
interrupt_value,
|
| 420 |
+
approval_type
|
| 421 |
+
)
|
| 422 |
+
|
| 423 |
+
# Execution completed
|
| 424 |
+
logger.info(f"✅ Execution completed")
|
| 425 |
+
return _create_success_response(thread_id, current_state, completed=True)
|
| 426 |
+
|
| 427 |
+
except Exception as e:
|
| 428 |
+
logger.error(f"❌ Error continuing: {e}", exc_info=True)
|
| 429 |
+
raise HTTPException(status_code=500, detail=f"Error continuing: {str(e)}")
|
| 430 |
+
|
| 431 |
+
|
| 432 |
+
@compute_agent_router.post("/approve-tools")
|
| 433 |
+
async def approve_tools(request: ToolApprovalRequest):
|
| 434 |
+
"""
|
| 435 |
+
Handle tool approval decisions.
|
| 436 |
+
|
| 437 |
+
Supports:
|
| 438 |
+
- approve_all: Approve all tools
|
| 439 |
+
- reject_all: Reject all tools
|
| 440 |
+
- approve_selected: Approve specific tools by index
|
| 441 |
+
- modify_and_approve: Modify tool arguments and approve
|
| 442 |
+
- request_re_reasoning: Request agent to reconsider
|
| 443 |
+
"""
|
| 444 |
+
current_agent = get_agent()
|
| 445 |
+
|
| 446 |
+
try:
|
| 447 |
+
logger.info(f"▶️ Processing tool approval for thread {request.thread_id}")
|
| 448 |
+
logger.info(f" Action: {request.action}")
|
| 449 |
+
|
| 450 |
+
thread_config = {"configurable": {"thread_id": request.thread_id}}
|
| 451 |
+
|
| 452 |
+
# Prepare user input based on action
|
| 453 |
+
user_input = {
|
| 454 |
+
"action": request.action
|
| 455 |
+
}
|
| 456 |
+
|
| 457 |
+
if request.action in ["approve_selected", "reject_selected"]:
|
| 458 |
+
user_input["tool_indices"] = request.tool_indices or []
|
| 459 |
+
logger.info(f" Indices: {user_input['tool_indices']}")
|
| 460 |
+
|
| 461 |
+
elif request.action == "modify_and_approve":
|
| 462 |
+
user_input["modifications"] = request.modifications or []
|
| 463 |
+
logger.info(f" Modifications: {len(user_input['modifications'])}")
|
| 464 |
+
|
| 465 |
+
elif request.action == "request_re_reasoning":
|
| 466 |
+
user_input["feedback"] = request.feedback or ""
|
| 467 |
+
logger.info(f" Feedback: {user_input['feedback'][:100]}...")
|
| 468 |
+
|
| 469 |
+
# Resume execution with tool decision
|
| 470 |
+
await current_agent.graph.ainvoke(
|
| 471 |
+
Command(resume=user_input),
|
| 472 |
+
config=thread_config
|
| 473 |
+
)
|
| 474 |
+
|
| 475 |
+
# Get updated state
|
| 476 |
+
graph_state = current_agent.graph.get_state(thread_config)
|
| 477 |
+
current_state = graph_state.values if graph_state.values else {}
|
| 478 |
+
|
| 479 |
+
# Check if still interrupted (e.g., after re-reasoning -> new tools proposed)
|
| 480 |
+
if graph_state.tasks and graph_state.tasks[0].interrupts:
|
| 481 |
+
interrupt_value = graph_state.tasks[0].interrupts[0].value
|
| 482 |
+
approval_type = _determine_approval_type(interrupt_value)
|
| 483 |
+
|
| 484 |
+
logger.info(f"⏸️ New approval needed: {approval_type}")
|
| 485 |
+
|
| 486 |
+
return _create_interrupt_response(
|
| 487 |
+
request.thread_id,
|
| 488 |
+
current_state,
|
| 489 |
+
interrupt_value,
|
| 490 |
+
approval_type
|
| 491 |
+
)
|
| 492 |
+
|
| 493 |
+
# Execution completed
|
| 494 |
+
logger.info(f"✅ Tool approval processed, execution completed")
|
| 495 |
+
return _create_success_response(request.thread_id, current_state, completed=True)
|
| 496 |
+
|
| 497 |
+
except Exception as e:
|
| 498 |
+
logger.error(f"❌ Error processing tool approval: {e}", exc_info=True)
|
| 499 |
+
raise HTTPException(status_code=500, detail=f"Error processing tool approval: {str(e)}")
|
| 500 |
+
|
| 501 |
+
|
| 502 |
+
@compute_agent_router.get("/state/{thread_id}")
|
| 503 |
+
async def get_state(thread_id: str):
|
| 504 |
+
"""
|
| 505 |
+
Get the current state of a conversation.
|
| 506 |
+
|
| 507 |
+
Useful for:
|
| 508 |
+
- Checking if waiting for approval
|
| 509 |
+
- Getting current step
|
| 510 |
+
- Debugging
|
| 511 |
+
"""
|
| 512 |
+
current_agent = get_agent()
|
| 513 |
+
|
| 514 |
+
try:
|
| 515 |
+
thread_config = {"configurable": {"thread_id": thread_id}}
|
| 516 |
+
graph_state = current_agent.graph.get_state(thread_config)
|
| 517 |
+
|
| 518 |
+
if not graph_state.values:
|
| 519 |
+
raise HTTPException(status_code=404, detail=f"No state found for thread {thread_id}")
|
| 520 |
+
|
| 521 |
+
# Check for interrupts
|
| 522 |
+
waiting_for_input = False
|
| 523 |
+
interrupt_data = None
|
| 524 |
+
approval_type = None
|
| 525 |
+
|
| 526 |
+
if graph_state.tasks and graph_state.tasks[0].interrupts:
|
| 527 |
+
waiting_for_input = True
|
| 528 |
+
interrupt_data = graph_state.tasks[0].interrupts[0].value
|
| 529 |
+
approval_type = _determine_approval_type(interrupt_data)
|
| 530 |
+
|
| 531 |
+
return {
|
| 532 |
+
"thread_id": thread_id,
|
| 533 |
+
"values": graph_state.values,
|
| 534 |
+
"next": graph_state.next,
|
| 535 |
+
"waiting_for_input": waiting_for_input,
|
| 536 |
+
"approval_type": approval_type,
|
| 537 |
+
"interrupt_data": interrupt_data,
|
| 538 |
+
"current_step": graph_state.values.get("current_step", ""),
|
| 539 |
+
"agent_decision": graph_state.values.get("agent_decision", "")
|
| 540 |
+
}
|
| 541 |
+
|
| 542 |
+
except HTTPException:
|
| 543 |
+
raise
|
| 544 |
+
except Exception as e:
|
| 545 |
+
logger.error(f"❌ Error getting state: {e}")
|
| 546 |
+
raise HTTPException(status_code=500, detail=f"Error getting state: {str(e)}")
|
| 547 |
+
|
| 548 |
+
|
| 549 |
+
@compute_agent_router.get("/examples")
|
| 550 |
+
async def get_examples():
|
| 551 |
+
"""Get example queries for testing."""
|
| 552 |
+
return {
|
| 553 |
+
"deployment_queries": [
|
| 554 |
+
"Deploy meta-llama/Llama-3.1-70B",
|
| 555 |
+
"Deploy mistralai/Mistral-7B-v0.1"
|
| 556 |
+
],
|
| 557 |
+
"tool_queries": [
|
| 558 |
+
"Search for latest AI developments",
|
| 559 |
+
"Calculate the fibonacci sequence up to n=10",
|
| 560 |
+
"What's the weather in Paris?"
|
| 561 |
+
],
|
| 562 |
+
"combined": [
|
| 563 |
+
"Deploy Llama-3.1-70B and search for its benchmarks"
|
| 564 |
+
]
|
| 565 |
+
}
|
| 566 |
+
|
| 567 |
+
|
| 568 |
+
@compute_agent_router.get("/info")
|
| 569 |
+
async def get_info():
|
| 570 |
+
"""Get router information."""
|
| 571 |
+
return {
|
| 572 |
+
"name": "ComputeAgent API Router",
|
| 573 |
+
"version": "3.0.0",
|
| 574 |
+
"description": "AI-powered agent with dual approval support",
|
| 575 |
+
"features": [
|
| 576 |
+
"Capacity approval",
|
| 577 |
+
"Tool approval",
|
| 578 |
+
"Tool modification",
|
| 579 |
+
"Re-reasoning",
|
| 580 |
+
"Re-estimation"
|
| 581 |
+
],
|
| 582 |
+
"endpoints": {
|
| 583 |
+
"query": "POST /api/compute/query - Start a query",
|
| 584 |
+
"continue": "POST /api/compute/continue/{thread_id} - Resume after capacity approval",
|
| 585 |
+
"approve_tools": "POST /api/compute/approve-tools - Handle tool approval",
|
| 586 |
+
"state": "GET /api/compute/state/{thread_id} - Get current state",
|
| 587 |
+
"health": "GET /api/compute/health - Health check",
|
| 588 |
+
"examples": "GET /api/compute/examples - Example queries"
|
| 589 |
+
}
|
| 590 |
+
}
|
ComputeAgent/vllm_engine_args.py
ADDED
|
@@ -0,0 +1,325 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
vLLM Engine Arguments Documentation
|
| 3 |
+
|
| 4 |
+
This module contains the complete documentation for vLLM engine arguments
|
| 5 |
+
from https://docs.vllm.ai/en/v0.11.0/serving/engine_args.html
|
| 6 |
+
|
| 7 |
+
This is used by the deployment system to generate optimal vLLM commands
|
| 8 |
+
without requiring online access.
|
| 9 |
+
|
| 10 |
+
Author: ComputeAgent Team
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
VLLM_ENGINE_ARGS_DOC = """
|
| 14 |
+
# vLLM Engine Arguments (v0.11.0)
|
| 15 |
+
|
| 16 |
+
## Model Configuration
|
| 17 |
+
|
| 18 |
+
--model
|
| 19 |
+
Name or path of the huggingface model to use.
|
| 20 |
+
Default: "facebook/opt-125m"
|
| 21 |
+
|
| 22 |
+
--task
|
| 23 |
+
Possible choices: auto, generate, embedding, embed, classify, score, reward
|
| 24 |
+
The task to use the model for. Each vLLM instance only supports one task.
|
| 25 |
+
Default: "auto"
|
| 26 |
+
|
| 27 |
+
--tokenizer
|
| 28 |
+
Name or path of the huggingface tokenizer to use. If unspecified, model name or path will be used.
|
| 29 |
+
|
| 30 |
+
--skip-tokenizer-init
|
| 31 |
+
Skip initialization of tokenizer and detokenizer.
|
| 32 |
+
|
| 33 |
+
--revision
|
| 34 |
+
The specific model version to use. It can be a branch name, a tag name, or a commit id.
|
| 35 |
+
|
| 36 |
+
--code-revision
|
| 37 |
+
The specific revision to use for the model code on Hugging Face Hub.
|
| 38 |
+
|
| 39 |
+
--tokenizer-revision
|
| 40 |
+
Revision of the huggingface tokenizer to use.
|
| 41 |
+
|
| 42 |
+
--tokenizer-mode
|
| 43 |
+
Possible choices: auto, slow, mistral
|
| 44 |
+
The tokenizer mode. "auto" will use the fast tokenizer if available.
|
| 45 |
+
Default: "auto"
|
| 46 |
+
|
| 47 |
+
--trust-remote-code
|
| 48 |
+
Trust remote code from huggingface.
|
| 49 |
+
|
| 50 |
+
--download-dir
|
| 51 |
+
Directory to download and load the weights, default to the default cache dir of huggingface.
|
| 52 |
+
|
| 53 |
+
--load-format
|
| 54 |
+
Possible choices: auto, pt, safetensors, npcache, dummy, tensorizer, sharded_state, gguf, bitsandbytes, mistral, runai_streamer
|
| 55 |
+
The format of the model weights to load.
|
| 56 |
+
Default: "auto"
|
| 57 |
+
|
| 58 |
+
--config-format
|
| 59 |
+
Possible choices: auto, hf, mistral
|
| 60 |
+
The format of the model config to load.
|
| 61 |
+
Default: "ConfigFormat.AUTO"
|
| 62 |
+
|
| 63 |
+
--dtype
|
| 64 |
+
Possible choices: auto, half, float16, bfloat16, float, float32
|
| 65 |
+
Data type for model weights and activations.
|
| 66 |
+
- "auto" will use FP16 precision for FP32 and FP16 models, and BF16 precision for BF16 models.
|
| 67 |
+
- "half" for FP16. Recommended for AWQ quantization.
|
| 68 |
+
- "bfloat16" for a balance between precision and range.
|
| 69 |
+
Default: "auto"
|
| 70 |
+
|
| 71 |
+
--kv-cache-dtype
|
| 72 |
+
Possible choices: auto, fp8, fp8_e5m2, fp8_e4m3
|
| 73 |
+
Data type for kv cache storage. If "auto", will use model data type.
|
| 74 |
+
Default: "auto"
|
| 75 |
+
|
| 76 |
+
--max-model-len
|
| 77 |
+
Model context length. If unspecified, will be automatically derived from the model config.
|
| 78 |
+
|
| 79 |
+
## Performance & Memory
|
| 80 |
+
|
| 81 |
+
--gpu-memory-utilization
|
| 82 |
+
The fraction of GPU memory to be used for the model executor (0.0-1.0).
|
| 83 |
+
This is a per-instance limit. For example, 0.5 would use 50% GPU memory.
|
| 84 |
+
Default: 0.9
|
| 85 |
+
|
| 86 |
+
--max-num-batched-tokens
|
| 87 |
+
Maximum number of batched tokens per iteration.
|
| 88 |
+
|
| 89 |
+
--max-num-seqs
|
| 90 |
+
Maximum number of sequences per iteration.
|
| 91 |
+
|
| 92 |
+
--swap-space
|
| 93 |
+
CPU swap space size (GiB) per GPU.
|
| 94 |
+
Default: 4
|
| 95 |
+
|
| 96 |
+
--cpu-offload-gb
|
| 97 |
+
The space in GiB to offload to CPU, per GPU. Default is 0 (no offloading).
|
| 98 |
+
This can virtually increase GPU memory. For example, if you have 24GB GPU and set this to 10,
|
| 99 |
+
it's like having a 34GB GPU.
|
| 100 |
+
Default: 0
|
| 101 |
+
|
| 102 |
+
--num-gpu-blocks-override
|
| 103 |
+
If specified, ignore GPU profiling result and use this number of GPU blocks.
|
| 104 |
+
|
| 105 |
+
## Distributed Execution
|
| 106 |
+
|
| 107 |
+
--tensor-parallel-size, -tp
|
| 108 |
+
Number of tensor parallel replicas. Use for multi-GPU inference.
|
| 109 |
+
Default: 1
|
| 110 |
+
|
| 111 |
+
--pipeline-parallel-size, -pp
|
| 112 |
+
Number of pipeline stages.
|
| 113 |
+
Default: 1
|
| 114 |
+
|
| 115 |
+
--distributed-executor-backend
|
| 116 |
+
Possible choices: ray, mp, uni, external_launcher
|
| 117 |
+
Backend to use for distributed model workers. "mp" for single host, "ray" for multi-host.
|
| 118 |
+
|
| 119 |
+
--max-parallel-loading-workers
|
| 120 |
+
Load model sequentially in multiple batches, to avoid RAM OOM when using tensor parallel.
|
| 121 |
+
|
| 122 |
+
## Caching & Optimization
|
| 123 |
+
|
| 124 |
+
--enable-prefix-caching, --no-enable-prefix-caching
|
| 125 |
+
Enables automatic prefix caching. Highly recommended for better performance.
|
| 126 |
+
|
| 127 |
+
--disable-sliding-window
|
| 128 |
+
Disables sliding window, capping to sliding window size.
|
| 129 |
+
|
| 130 |
+
--block-size
|
| 131 |
+
Possible choices: 8, 16, 32, 64, 128
|
| 132 |
+
Token block size for contiguous chunks of tokens.
|
| 133 |
+
Default depends on device (CUDA: up to 32, HPU: 128).
|
| 134 |
+
|
| 135 |
+
--enable-chunked-prefill
|
| 136 |
+
Enable chunked prefill for long context processing. Recommended for max-model-len > 8192.
|
| 137 |
+
|
| 138 |
+
--max-seq-len-to-capture
|
| 139 |
+
Maximum sequence length covered by CUDA graphs. Falls back to eager mode for longer sequences.
|
| 140 |
+
Default: 8192
|
| 141 |
+
|
| 142 |
+
## Quantization
|
| 143 |
+
|
| 144 |
+
--quantization, -q
|
| 145 |
+
Possible choices: aqlm, awq, deepspeedfp, tpu_int8, fp8, fbgemm_fp8, modelopt, marlin, gguf,
|
| 146 |
+
gptq_marlin_24, gptq_marlin, awq_marlin, gptq, compressed-tensors, bitsandbytes, qqq, hqq,
|
| 147 |
+
experts_int8, neuron_quant, ipex, quark, moe_wna16, None
|
| 148 |
+
Method used to quantize the weights.
|
| 149 |
+
|
| 150 |
+
## Speculative Decoding
|
| 151 |
+
|
| 152 |
+
--speculative-model
|
| 153 |
+
The name of the draft model to be used in speculative decoding.
|
| 154 |
+
|
| 155 |
+
--num-speculative-tokens
|
| 156 |
+
The number of speculative tokens to sample from the draft model.
|
| 157 |
+
|
| 158 |
+
--speculative-max-model-len
|
| 159 |
+
The maximum sequence length supported by the draft model.
|
| 160 |
+
|
| 161 |
+
--speculative-disable-by-batch-size
|
| 162 |
+
Disable speculative decoding if the number of enqueue requests is larger than this value.
|
| 163 |
+
|
| 164 |
+
--ngram-prompt-lookup-max
|
| 165 |
+
Max size of window for ngram prompt lookup in speculative decoding.
|
| 166 |
+
|
| 167 |
+
--ngram-prompt-lookup-min
|
| 168 |
+
Min size of window for ngram prompt lookup in speculative decoding.
|
| 169 |
+
|
| 170 |
+
## LoRA Support
|
| 171 |
+
|
| 172 |
+
--enable-lora
|
| 173 |
+
If True, enable handling of LoRA adapters.
|
| 174 |
+
|
| 175 |
+
--max-loras
|
| 176 |
+
Max number of LoRAs in a single batch.
|
| 177 |
+
Default: 1
|
| 178 |
+
|
| 179 |
+
--max-lora-rank
|
| 180 |
+
Max LoRA rank.
|
| 181 |
+
Default: 16
|
| 182 |
+
|
| 183 |
+
--lora-dtype
|
| 184 |
+
Possible choices: auto, float16, bfloat16
|
| 185 |
+
Data type for LoRA. If auto, will default to base model dtype.
|
| 186 |
+
Default: "auto"
|
| 187 |
+
|
| 188 |
+
--fully-sharded-loras
|
| 189 |
+
Use fully sharded LoRA layers. Likely faster at high sequence length or tensor parallel size.
|
| 190 |
+
|
| 191 |
+
## Scheduling & Execution
|
| 192 |
+
|
| 193 |
+
--scheduling-policy
|
| 194 |
+
Possible choices: fcfs, priority
|
| 195 |
+
The scheduling policy to use. "fcfs" (first come first served) or "priority".
|
| 196 |
+
Default: "fcfs"
|
| 197 |
+
|
| 198 |
+
--num-scheduler-steps
|
| 199 |
+
Maximum number of forward steps per scheduler call.
|
| 200 |
+
Default: 1
|
| 201 |
+
|
| 202 |
+
--scheduler-delay-factor
|
| 203 |
+
Apply a delay before scheduling next prompt (delay factor * previous prompt latency).
|
| 204 |
+
Default: 0.0
|
| 205 |
+
|
| 206 |
+
--device
|
| 207 |
+
Possible choices: auto, cuda, neuron, cpu, openvino, tpu, xpu, hpu
|
| 208 |
+
Device type for vLLM execution.
|
| 209 |
+
Default: "auto"
|
| 210 |
+
|
| 211 |
+
## Logging & Monitoring
|
| 212 |
+
|
| 213 |
+
--disable-log-stats
|
| 214 |
+
Disable logging statistics.
|
| 215 |
+
|
| 216 |
+
--max-logprobs
|
| 217 |
+
Max number of log probs to return when logprobs is specified in SamplingParams.
|
| 218 |
+
Default: 20
|
| 219 |
+
|
| 220 |
+
--disable-async-output-proc
|
| 221 |
+
Disable async output processing. May result in lower performance.
|
| 222 |
+
|
| 223 |
+
--otlp-traces-endpoint
|
| 224 |
+
Target URL to which OpenTelemetry traces will be sent.
|
| 225 |
+
|
| 226 |
+
--collect-detailed-traces
|
| 227 |
+
Valid choices: model, worker, all
|
| 228 |
+
Collect detailed traces for specified modules (requires --otlp-traces-endpoint).
|
| 229 |
+
|
| 230 |
+
## Advanced Options
|
| 231 |
+
|
| 232 |
+
--rope-scaling
|
| 233 |
+
RoPE scaling configuration in JSON format. Example: {"rope_type":"dynamic","factor":2.0}
|
| 234 |
+
|
| 235 |
+
--rope-theta
|
| 236 |
+
RoPE theta. Use with rope_scaling to improve scaled model performance.
|
| 237 |
+
|
| 238 |
+
--enforce-eager
|
| 239 |
+
Always use eager-mode PyTorch. If False, uses hybrid eager/CUDA graph mode.
|
| 240 |
+
|
| 241 |
+
--seed
|
| 242 |
+
Random seed for operations.
|
| 243 |
+
Default: 0
|
| 244 |
+
|
| 245 |
+
--compilation-config, -O
|
| 246 |
+
torch.compile configuration for the model (0, 1, 2, 3 or JSON string).
|
| 247 |
+
Level 3 is recommended for production.
|
| 248 |
+
|
| 249 |
+
--worker-cls
|
| 250 |
+
The worker class to use for distributed execution.
|
| 251 |
+
Default: "auto"
|
| 252 |
+
|
| 253 |
+
--enable-sleep-mode
|
| 254 |
+
Enable sleep mode for the engine (CUDA platform only).
|
| 255 |
+
|
| 256 |
+
--calculate-kv-scales
|
| 257 |
+
Enable dynamic calculation of k_scale and v_scale when kv-cache-dtype is fp8.
|
| 258 |
+
|
| 259 |
+
## Serving Options
|
| 260 |
+
|
| 261 |
+
--host
|
| 262 |
+
Host address for the server.
|
| 263 |
+
Default: "0.0.0.0"
|
| 264 |
+
|
| 265 |
+
--port
|
| 266 |
+
Port number for the server.
|
| 267 |
+
Default: 8000
|
| 268 |
+
|
| 269 |
+
--served-model-name
|
| 270 |
+
The model name(s) used in the API. Can be multiple comma-separated names.
|
| 271 |
+
|
| 272 |
+
## Multimodal
|
| 273 |
+
|
| 274 |
+
--limit-mm-per-prompt
|
| 275 |
+
Limit how many multimodal inputs per prompt (e.g., image=16,video=2).
|
| 276 |
+
|
| 277 |
+
--mm-processor-kwargs
|
| 278 |
+
Overrides for multimodal input processing (JSON format).
|
| 279 |
+
|
| 280 |
+
--disable-mm-preprocessor-cache
|
| 281 |
+
Disable caching of multi-modal preprocessor/mapper (not recommended).
|
| 282 |
+
"""
|
| 283 |
+
|
| 284 |
+
|
| 285 |
+
def get_vllm_docs() -> str:
|
| 286 |
+
"""
|
| 287 |
+
Get the vLLM engine arguments documentation.
|
| 288 |
+
|
| 289 |
+
Returns:
|
| 290 |
+
str: Complete vLLM engine arguments documentation
|
| 291 |
+
"""
|
| 292 |
+
return VLLM_ENGINE_ARGS_DOC
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
def get_common_parameters_summary() -> str:
|
| 296 |
+
"""
|
| 297 |
+
Get a summary of the most commonly used vLLM parameters.
|
| 298 |
+
|
| 299 |
+
Returns:
|
| 300 |
+
str: Summary of key vLLM parameters
|
| 301 |
+
"""
|
| 302 |
+
return """
|
| 303 |
+
## Most Common vLLM Parameters:
|
| 304 |
+
|
| 305 |
+
**Performance:**
|
| 306 |
+
- --gpu-memory-utilization: Fraction of GPU memory to use (0.0-1.0, default: 0.9)
|
| 307 |
+
- --max-model-len: Maximum context length
|
| 308 |
+
- --max-num-seqs: Maximum sequences per iteration
|
| 309 |
+
- --max-num-batched-tokens: Maximum batched tokens per iteration
|
| 310 |
+
- --enable-prefix-caching: Enable prefix caching (recommended)
|
| 311 |
+
- --enable-chunked-prefill: For long contexts (>8192 tokens)
|
| 312 |
+
|
| 313 |
+
**Model Configuration:**
|
| 314 |
+
- --dtype: Data type (auto, half, float16, bfloat16, float32)
|
| 315 |
+
- --kv-cache-dtype: KV cache type (auto, fp8, fp16, bf16)
|
| 316 |
+
- --quantization: Quantization method (fp8, awq, gptq, etc.)
|
| 317 |
+
|
| 318 |
+
**Distributed:**
|
| 319 |
+
- --tensor-parallel-size: Number of GPUs for tensor parallelism
|
| 320 |
+
- --pipeline-parallel-size: Number of pipeline stages
|
| 321 |
+
|
| 322 |
+
**Server:**
|
| 323 |
+
- --host: Server host address (default: 0.0.0.0)
|
| 324 |
+
- --port: Server port (default: 8000)
|
| 325 |
+
"""
|
Compute_MCP/api_data_structure.py
ADDED
|
@@ -0,0 +1,398 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
|
| 3 |
+
import logging
|
| 4 |
+
from typing import List, Optional, Dict, Any, Union
|
| 5 |
+
from pydantic import BaseModel, Field
|
| 6 |
+
from typing import Any
|
| 7 |
+
from enum import Enum
|
| 8 |
+
from constant import Constants
|
| 9 |
+
import requests
|
| 10 |
+
|
| 11 |
+
# Enum for instance status
|
| 12 |
+
class InstanceStatus(Enum):
|
| 13 |
+
CREATED = 0
|
| 14 |
+
DEPLOYED = 1
|
| 15 |
+
STARTING = 2
|
| 16 |
+
RUNNING = 3
|
| 17 |
+
ERRORED = 4
|
| 18 |
+
TERMINATING = 5
|
| 19 |
+
TERMINATED = 6
|
| 20 |
+
STOPPING = 7
|
| 21 |
+
STOPPED = 8
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class Timestamp(BaseModel):
|
| 25 |
+
seconds: int
|
| 26 |
+
nanos: int
|
| 27 |
+
|
| 28 |
+
# GPU model
|
| 29 |
+
class GPUInfo(BaseModel):
|
| 30 |
+
model: str
|
| 31 |
+
|
| 32 |
+
# Port info
|
| 33 |
+
class PortInfo(BaseModel):
|
| 34 |
+
protocol: str
|
| 35 |
+
container_port: int
|
| 36 |
+
node_port: int
|
| 37 |
+
|
| 38 |
+
class InstanceSpending(BaseModel):
|
| 39 |
+
instance_id: str
|
| 40 |
+
hourly_price: float
|
| 41 |
+
total_spend: float
|
| 42 |
+
|
| 43 |
+
# InstanceInfo for GET method
|
| 44 |
+
class InstanceInfo(BaseModel): # New fields added
|
| 45 |
+
id: Optional[str] = None
|
| 46 |
+
deployment_id: Optional[str] = None
|
| 47 |
+
name: Optional[str] = None
|
| 48 |
+
user_id: Optional[str] = None
|
| 49 |
+
container_image: Optional[str] = None
|
| 50 |
+
status: Optional[InstanceStatus] = None
|
| 51 |
+
status_string: Optional[str] = None
|
| 52 |
+
additional_info: Optional[str] = None
|
| 53 |
+
type: Optional[int] = None
|
| 54 |
+
created_at: Optional[Timestamp] = None
|
| 55 |
+
updated_at: Optional[Timestamp] = None
|
| 56 |
+
ready_at: Optional[Timestamp] = None
|
| 57 |
+
stopped_at: Optional[Timestamp] = None
|
| 58 |
+
cpu: Optional[int] = None
|
| 59 |
+
memory: Optional[int] = None
|
| 60 |
+
gpu: Optional[List[GPUInfo]] = None
|
| 61 |
+
disk: Optional[int] = None
|
| 62 |
+
bandwidth: Optional[int] = None
|
| 63 |
+
ssh_key_id: Optional[str] = None
|
| 64 |
+
location: Optional[str] = None
|
| 65 |
+
ports: Optional[Dict[str, PortInfo]] = None
|
| 66 |
+
hive_environment_variables: Optional[Dict[str, Any]] = None
|
| 67 |
+
environment_variables: Optional[Dict[str, Any]] = None
|
| 68 |
+
runtime: Optional[int] = None
|
| 69 |
+
spending: Optional[InstanceSpending] = None
|
| 70 |
+
def __init__(self, **data):
|
| 71 |
+
super().__init__(**data)
|
| 72 |
+
if self.status_string is None and isinstance(self.status, InstanceStatus):
|
| 73 |
+
self.status_string = self.status.name
|
| 74 |
+
|
| 75 |
+
# Spending info model
|
| 76 |
+
class InstanceSpending(BaseModel):
|
| 77 |
+
instance_id: str
|
| 78 |
+
hourly_price: float
|
| 79 |
+
total_spend: float
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
# Configuration mappings based on the UI tables
|
| 83 |
+
GPU_CONFIGS = {
|
| 84 |
+
"1x RTX 4090": {
|
| 85 |
+
"gpu": ["RTX 4090"],
|
| 86 |
+
"cpu": 8,
|
| 87 |
+
"memory": 48,
|
| 88 |
+
"disk": 250,
|
| 89 |
+
"bandwidth": 1000
|
| 90 |
+
},
|
| 91 |
+
"2x RTX 4090": {
|
| 92 |
+
"gpu": ["RTX 4090", "RTX 4090"],
|
| 93 |
+
"cpu": 16,
|
| 94 |
+
"memory": 96,
|
| 95 |
+
"disk": 500,
|
| 96 |
+
"bandwidth": 1000
|
| 97 |
+
},
|
| 98 |
+
"4x RTX 4090": {
|
| 99 |
+
"gpu": ["RTX 4090", "RTX 4090", "RTX 4090", "RTX 4090"],
|
| 100 |
+
"cpu": 32,
|
| 101 |
+
"memory": 192,
|
| 102 |
+
"disk": 1000,
|
| 103 |
+
"bandwidth": 1000
|
| 104 |
+
},
|
| 105 |
+
"8x RTX 4090": {
|
| 106 |
+
"gpu": ["RTX 4090", "RTX 4090", "RTX 4090", "RTX 4090",
|
| 107 |
+
"RTX 4090", "RTX 4090", "RTX 4090", "RTX 4090"],
|
| 108 |
+
"cpu": 64,
|
| 109 |
+
"memory": 384,
|
| 110 |
+
"disk": 2000,
|
| 111 |
+
"bandwidth": 1000
|
| 112 |
+
},
|
| 113 |
+
"1x RTX 5090": {
|
| 114 |
+
"gpu": ["RTX 5090"],
|
| 115 |
+
"cpu": 8,
|
| 116 |
+
"memory": 48,
|
| 117 |
+
"disk": 250,
|
| 118 |
+
"bandwidth": 1000
|
| 119 |
+
},
|
| 120 |
+
"2x RTX 5090": {
|
| 121 |
+
"gpu": ["RTX 5090", "RTX 5090"],
|
| 122 |
+
"cpu": 16,
|
| 123 |
+
"memory": 96,
|
| 124 |
+
"disk": 500,
|
| 125 |
+
"bandwidth": 1000
|
| 126 |
+
},
|
| 127 |
+
"4x RTX 5090": {
|
| 128 |
+
"gpu": ["RTX 5090", "RTX 5090", "RTX 5090", "RTX 5090"],
|
| 129 |
+
"cpu": 32,
|
| 130 |
+
"memory": 192,
|
| 131 |
+
"disk": 1000,
|
| 132 |
+
"bandwidth": 1000
|
| 133 |
+
},
|
| 134 |
+
"8x RTX 5090": {
|
| 135 |
+
"gpu": ["RTX 5090", "RTX 5090", "RTX 5090", "RTX 5090",
|
| 136 |
+
"RTX 5090", "RTX 5090", "RTX 5090", "RTX 5090"],
|
| 137 |
+
"cpu": 64,
|
| 138 |
+
"memory": 384,
|
| 139 |
+
"disk": 2000,
|
| 140 |
+
"bandwidth": 1000
|
| 141 |
+
}
|
| 142 |
+
}
|
| 143 |
+
|
| 144 |
+
VCPU_CONFIGS = {
|
| 145 |
+
"2vCPU": {
|
| 146 |
+
"gpu": [],
|
| 147 |
+
"cpu": 2,
|
| 148 |
+
"memory": 4,
|
| 149 |
+
"disk": 50,
|
| 150 |
+
"bandwidth": 250
|
| 151 |
+
},
|
| 152 |
+
"4vCPU": {
|
| 153 |
+
"gpu": [],
|
| 154 |
+
"cpu": 4,
|
| 155 |
+
"memory": 8,
|
| 156 |
+
"disk": 100,
|
| 157 |
+
"bandwidth": 250
|
| 158 |
+
},
|
| 159 |
+
"8vCPU": {
|
| 160 |
+
"gpu": [],
|
| 161 |
+
"cpu": 8,
|
| 162 |
+
"memory": 16,
|
| 163 |
+
"disk": 200,
|
| 164 |
+
"bandwidth": 500
|
| 165 |
+
},
|
| 166 |
+
"16vCPU": {
|
| 167 |
+
"gpu": [],
|
| 168 |
+
"cpu": 16,
|
| 169 |
+
"memory": 32,
|
| 170 |
+
"disk": 400,
|
| 171 |
+
"bandwidth": 1000
|
| 172 |
+
},
|
| 173 |
+
"32vCPU": {
|
| 174 |
+
"gpu": [],
|
| 175 |
+
"cpu": 32,
|
| 176 |
+
"memory": 64,
|
| 177 |
+
"disk": 800,
|
| 178 |
+
"bandwidth": 1000
|
| 179 |
+
}
|
| 180 |
+
}
|
| 181 |
+
|
| 182 |
+
# Location-GPU validation map (using API format - lowercase)
|
| 183 |
+
LOCATION_GPU_MAP = {
|
| 184 |
+
"france": ["RTX 4090"],
|
| 185 |
+
"uae": ["RTX 4090"],
|
| 186 |
+
"texas": ["RTX 5090"],
|
| 187 |
+
"uae-2": ["RTX 5090"]
|
| 188 |
+
}
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
class HiveComputeAPI:
|
| 192 |
+
"""
|
| 193 |
+
A wrapper class that provides methods to interact with the Hive Compute API.
|
| 194 |
+
"""
|
| 195 |
+
|
| 196 |
+
def __init__(self, base_url: str = Constants.HIVE_COMPUTE_BASE_API_URL, token: str = Constants.HIVE_COMPUTE_DEFAULT_API_TOKEN):
|
| 197 |
+
"""
|
| 198 |
+
Initializes the HiveComputeAPI handler.
|
| 199 |
+
|
| 200 |
+
Args:
|
| 201 |
+
base_url (str): The base URL of the Hive Compute API.
|
| 202 |
+
token (str): The authentication token for the Hive Compute API.
|
| 203 |
+
Note: The ModelRouter will automatically refresh the map of served models upon initialization.
|
| 204 |
+
"""
|
| 205 |
+
self.base_url = base_url.strip("/")
|
| 206 |
+
self.token = token
|
| 207 |
+
self.logger = logging.getLogger(__name__)
|
| 208 |
+
|
| 209 |
+
def __fetch_instance_structure(self, instance_json) -> InstanceInfo:
|
| 210 |
+
"""
|
| 211 |
+
Fetches the structure of an instance from the API.
|
| 212 |
+
|
| 213 |
+
Returns:
|
| 214 |
+
InstanceInfo: An InstanceInfo object representing the structure of an instance.
|
| 215 |
+
"""
|
| 216 |
+
# Ensure instance_json is a dict
|
| 217 |
+
if not isinstance(instance_json, dict):
|
| 218 |
+
return {}
|
| 219 |
+
# Convert only problematic fields
|
| 220 |
+
if "status" in instance_json and not isinstance(instance_json["status"], InstanceStatus):
|
| 221 |
+
try:
|
| 222 |
+
instance_json["status"] = InstanceStatus(instance_json["status"])
|
| 223 |
+
except Exception:
|
| 224 |
+
instance_json["status"] = InstanceStatus.CREATED
|
| 225 |
+
for field in ["created_at", "updated_at", "ready_at", "stopped_at"]:
|
| 226 |
+
value = instance_json.get(field)
|
| 227 |
+
if isinstance(value, dict):
|
| 228 |
+
instance_json[field] = Timestamp(**value)
|
| 229 |
+
else:
|
| 230 |
+
instance_json[field] = None
|
| 231 |
+
if "gpu" in instance_json:
|
| 232 |
+
instance_json["gpu"] = [GPUInfo(**gpu) for gpu in instance_json.get("gpu", []) if isinstance(gpu, dict)]
|
| 233 |
+
if "ports" in instance_json:
|
| 234 |
+
instance_json["ports"] = {k: PortInfo(**v) for k, v in instance_json.get("ports", {}).items() if isinstance(v, dict)}
|
| 235 |
+
return InstanceInfo(**instance_json)
|
| 236 |
+
|
| 237 |
+
def get_all_instances(self) -> List[InstanceInfo]:
|
| 238 |
+
"""
|
| 239 |
+
Fetches all compute instances for the authenticated user.
|
| 240 |
+
|
| 241 |
+
Returns:
|
| 242 |
+
List[InstanceInfo]: A list of InstanceInfo objects representing the user's compute instances.
|
| 243 |
+
"""
|
| 244 |
+
try:
|
| 245 |
+
response = requests.get(f"{self.base_url}/instances", headers={
|
| 246 |
+
"Authorization": f"Bearer {self.token}"
|
| 247 |
+
})
|
| 248 |
+
response.raise_for_status()
|
| 249 |
+
response_json = response.json()
|
| 250 |
+
spending_map = response_json.get("spending", {})
|
| 251 |
+
instances = []
|
| 252 |
+
for inst in response_json.get("instances", []):
|
| 253 |
+
inst_struct = self.__fetch_instance_structure(inst)
|
| 254 |
+
spend = spending_map.get(inst.get("id"))
|
| 255 |
+
if spend:
|
| 256 |
+
inst_struct.spending = InstanceSpending(**spend)
|
| 257 |
+
instances.append(InstanceInfo.model_validate(inst_struct))
|
| 258 |
+
return instances
|
| 259 |
+
except requests.RequestException as e:
|
| 260 |
+
self.logger.error(f"Failed to fetch instances: {e}")
|
| 261 |
+
return []
|
| 262 |
+
|
| 263 |
+
def create_instance(
|
| 264 |
+
self,
|
| 265 |
+
name: str = "default",
|
| 266 |
+
location: str = "uae", # Changed default to API format
|
| 267 |
+
config: str = "1x RTX 4090",
|
| 268 |
+
container_image: str = "Dockerfile.vulkan",
|
| 269 |
+
tcp_ports: Optional[List[int]] = None,
|
| 270 |
+
https_ports: Optional[List[int]] = None,
|
| 271 |
+
udp_ports: Optional[List[int]] = None,
|
| 272 |
+
launch_jupyter_notebook: bool = False,
|
| 273 |
+
instance_type: int = 0,
|
| 274 |
+
custom_config: Optional[Dict[str, Any]] = None
|
| 275 |
+
) -> Optional[Dict[str, Any]]:
|
| 276 |
+
"""
|
| 277 |
+
Creates a new compute instance using predefined configurations or custom settings.
|
| 278 |
+
|
| 279 |
+
Args:
|
| 280 |
+
name (str): Name of the instance. Defaults to "default".
|
| 281 |
+
location (str): Location where the instance will be deployed. Defaults to "uae".
|
| 282 |
+
Valid locations: france, uae, texas, uae-2
|
| 283 |
+
config (str): Predefined configuration. Options:
|
| 284 |
+
GPU configs: "1x RTX 4090", "2x RTX 4090", "4x RTX 4090", "8x RTX 4090",
|
| 285 |
+
"1x RTX 5090", "2x RTX 5090", "4x RTX 5090", "8x RTX 5090"
|
| 286 |
+
vCPU configs: "2vCPU", "4vCPU", "8vCPU", "16vCPU", "32vCPU"
|
| 287 |
+
Defaults to "1x RTX 4090".
|
| 288 |
+
container_image (str): Docker container image to use. Defaults to "Dockerfile.vulkan".
|
| 289 |
+
tcp_ports (List[int], optional): List of TCP ports to expose.
|
| 290 |
+
https_ports (List[int], optional): List of HTTPS ports to expose.
|
| 291 |
+
udp_ports (List[int], optional): List of UDP ports to expose.
|
| 292 |
+
launch_jupyter_notebook (bool): Whether to launch Jupyter notebook. Defaults to False.
|
| 293 |
+
instance_type (int): Type of instance. Defaults to 0.
|
| 294 |
+
custom_config (Dict[str, Any], optional): Custom configuration to override defaults.
|
| 295 |
+
Keys: cpu, memory, disk, bandwidth, gpu
|
| 296 |
+
|
| 297 |
+
Returns:
|
| 298 |
+
Optional[Dict[str, Any]]: A dictionary with 'id' and 'status' keys if successful, None otherwise.
|
| 299 |
+
|
| 300 |
+
Raises:
|
| 301 |
+
ValueError: If configuration is invalid or GPU type not available in location.
|
| 302 |
+
"""
|
| 303 |
+
# Combine all configs
|
| 304 |
+
ALL_CONFIGS = {**GPU_CONFIGS, **VCPU_CONFIGS}
|
| 305 |
+
|
| 306 |
+
# Validate configuration
|
| 307 |
+
if config not in ALL_CONFIGS:
|
| 308 |
+
available_configs = list(ALL_CONFIGS.keys())
|
| 309 |
+
raise ValueError(
|
| 310 |
+
f"Invalid config: {config}. Available configs: {available_configs}"
|
| 311 |
+
)
|
| 312 |
+
|
| 313 |
+
# Get base configuration
|
| 314 |
+
instance_config = ALL_CONFIGS[config].copy()
|
| 315 |
+
|
| 316 |
+
# Apply custom config if provided
|
| 317 |
+
if custom_config:
|
| 318 |
+
instance_config.update(custom_config)
|
| 319 |
+
|
| 320 |
+
# Validate location
|
| 321 |
+
if location not in LOCATION_GPU_MAP:
|
| 322 |
+
raise ValueError(
|
| 323 |
+
f"Invalid location: {location}. Valid locations: {list(LOCATION_GPU_MAP.keys())}"
|
| 324 |
+
)
|
| 325 |
+
|
| 326 |
+
# Validate GPU type for location (only if GPU instance)
|
| 327 |
+
if instance_config["gpu"]: # If not empty (i.e., GPU instance)
|
| 328 |
+
gpu_type = instance_config["gpu"][0] # Get the GPU model
|
| 329 |
+
if gpu_type not in LOCATION_GPU_MAP[location]:
|
| 330 |
+
raise ValueError(
|
| 331 |
+
f"GPU type '{gpu_type}' not available in location '{location}'. "
|
| 332 |
+
f"Available GPUs: {LOCATION_GPU_MAP[location]}"
|
| 333 |
+
)
|
| 334 |
+
|
| 335 |
+
# Build the payload - exact format matching the API request
|
| 336 |
+
payload = {
|
| 337 |
+
"bandwidth": instance_config["bandwidth"],
|
| 338 |
+
"container_image": container_image,
|
| 339 |
+
"cpu": instance_config["cpu"],
|
| 340 |
+
"disk": instance_config["disk"],
|
| 341 |
+
"gpu": instance_config["gpu"],
|
| 342 |
+
"https_ports": https_ports if https_ports is not None else [8888],
|
| 343 |
+
"launch_jupyter_notebook": launch_jupyter_notebook,
|
| 344 |
+
"location": location,
|
| 345 |
+
"memory": instance_config["memory"],
|
| 346 |
+
"name": name,
|
| 347 |
+
"tcp_ports": tcp_ports if tcp_ports is not None else [],
|
| 348 |
+
"type": instance_type,
|
| 349 |
+
"udp_ports": udp_ports if udp_ports is not None else []
|
| 350 |
+
}
|
| 351 |
+
|
| 352 |
+
# Log the payload for debugging
|
| 353 |
+
self.logger.info(f"Creating instance with payload: {payload}")
|
| 354 |
+
|
| 355 |
+
try:
|
| 356 |
+
response = requests.post(
|
| 357 |
+
f"{self.base_url}/instances/instance",
|
| 358 |
+
headers={
|
| 359 |
+
"Authorization": f"Bearer {self.token}",
|
| 360 |
+
"Content-Type": "application/json"
|
| 361 |
+
},
|
| 362 |
+
json=payload
|
| 363 |
+
)
|
| 364 |
+
|
| 365 |
+
# Log response details for debugging
|
| 366 |
+
self.logger.info(f"Response status code: {response.status_code}")
|
| 367 |
+
if response.status_code != 200:
|
| 368 |
+
self.logger.error(f"Response body: {response.text}")
|
| 369 |
+
|
| 370 |
+
response.raise_for_status()
|
| 371 |
+
|
| 372 |
+
response_data = response.json()
|
| 373 |
+
instance_data = response_data.get("instance", {})
|
| 374 |
+
return {
|
| 375 |
+
"id": instance_data.get("id"),
|
| 376 |
+
"status": instance_data.get("status")
|
| 377 |
+
}
|
| 378 |
+
|
| 379 |
+
except requests.RequestException as e:
|
| 380 |
+
self.logger.error(f"Failed to create instance: {e}")
|
| 381 |
+
if hasattr(e, 'response') and e.response is not None:
|
| 382 |
+
self.logger.error(f"Response content: {e.response.text}")
|
| 383 |
+
return None
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
def get_available_locations(self, gpu_type: Optional[str] = None) -> List[str]:
|
| 387 |
+
"""
|
| 388 |
+
Get available locations, optionally filtered by GPU type.
|
| 389 |
+
|
| 390 |
+
Args:
|
| 391 |
+
gpu_type (str, optional): GPU model to filter locations by.
|
| 392 |
+
|
| 393 |
+
Returns:
|
| 394 |
+
List[str]: List of available locations.
|
| 395 |
+
"""
|
| 396 |
+
if gpu_type:
|
| 397 |
+
return [loc for loc, gpus in LOCATION_GPU_MAP.items() if gpu_type in gpus]
|
| 398 |
+
return list(LOCATION_GPU_MAP.keys())
|
Compute_MCP/main.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This allows importing modules from the top-level project directory
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
sys.path.append("/home/hivenet")
|
| 7 |
+
"""
|
| 8 |
+
FastMCP HiveCompute Server
|
| 9 |
+
|
| 10 |
+
A FastMCP service that performs basic CRUD operations on the 'Compute with Hivenet' platform.
|
| 11 |
+
"""
|
| 12 |
+
from tools import mcp
|
| 13 |
+
|
| 14 |
+
if __name__ == "__main__":
|
| 15 |
+
print("🚀 Compute with Hivenet MCP Server starting ...")
|
| 16 |
+
mcp.run(transport='stdio')
|
Compute_MCP/tools.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from api_data_structure import HiveComputeAPI
|
| 2 |
+
from utils import logger, create_success_response, handle_exception
|
| 3 |
+
from typing import Dict, Any
|
| 4 |
+
from fastmcp import FastMCP
|
| 5 |
+
from constant import Constants
|
| 6 |
+
|
| 7 |
+
mcp = FastMCP(
|
| 8 |
+
name="Compute with Hivenet MCP"
|
| 9 |
+
)
|
| 10 |
+
|
| 11 |
+
@mcp.tool()
|
| 12 |
+
async def create_compute_instance(name: str = "default", location: str = "uae", config: str = "1x RTX 4090") -> Dict[str, Any]:
|
| 13 |
+
"""
|
| 14 |
+
Create a new compute instance with the specified configuration.
|
| 15 |
+
|
| 16 |
+
Args:
|
| 17 |
+
name: Name of the instance. Defaults to "default".
|
| 18 |
+
location: Location where the instance will be deployed. Defaults to "uae".
|
| 19 |
+
Valid locations: france, uae, texas, uae-2
|
| 20 |
+
config: Predefined configuration. Defaults to "1x RTX 4090".
|
| 21 |
+
GPU configs: "1x RTX 4090", "2x RTX 4090", "4x RTX 4090", "8x RTX 4090",
|
| 22 |
+
"1x RTX 5090", "2x RTX 5090", "4x RTX 5090", "8x RTX 5090"
|
| 23 |
+
vCPU configs: "2vCPU", "4vCPU", "8vCPU", "16vCPU", "32vCPU"
|
| 24 |
+
|
| 25 |
+
Returns:
|
| 26 |
+
Dict containing the created instance information.
|
| 27 |
+
"""
|
| 28 |
+
token = Constants.HIVE_COMPUTE_DEFAULT_API_TOKEN
|
| 29 |
+
api_handler = HiveComputeAPI(token=token)
|
| 30 |
+
try:
|
| 31 |
+
logger.info(f"Creating compute instance: name={name}, location={location}, config={config}")
|
| 32 |
+
result = api_handler.create_instance(name=name, location=location, config=config)
|
| 33 |
+
|
| 34 |
+
if result is None:
|
| 35 |
+
logger.error(f"Failed to create instance - API returned None")
|
| 36 |
+
return {
|
| 37 |
+
"status": "error",
|
| 38 |
+
"error": "Failed to create instance. Check API logs for details."
|
| 39 |
+
}
|
| 40 |
+
|
| 41 |
+
logger.info(f"Successfully created instance: {result.id if hasattr(result, 'id') else 'unknown'}")
|
| 42 |
+
return create_success_response(result)
|
| 43 |
+
except Exception as e:
|
| 44 |
+
logger.error(f"Exception creating instance: {str(e)}")
|
| 45 |
+
return handle_exception(e, "create_compute_instance")
|
| 46 |
+
|
| 47 |
+
@mcp.tool()
|
| 48 |
+
async def list_all_compute_instances(category: str = None) -> Dict[str, Any]:
|
| 49 |
+
"""
|
| 50 |
+
List all instances belonging to the user, organized into 4 categories: RUNNING, STOPPED, ERRORED, and TERMINATED.
|
| 51 |
+
Shows basic information about each instance, including ID, name, status, location, spending, and resource allocation.
|
| 52 |
+
Spending information includes hourly price and total in EUR spent so far.
|
| 53 |
+
|
| 54 |
+
Args:
|
| 55 |
+
category: Optional filter to return only instances from a specific category.
|
| 56 |
+
Valid values: "RUNNING", "STOPPED", "ERRORED", "TERMINATED".
|
| 57 |
+
If not provided, returns all categories.
|
| 58 |
+
|
| 59 |
+
Returns:
|
| 60 |
+
Dict containing instances. If category is specified, returns only instances from that category.
|
| 61 |
+
If category is not specified, returns all instances organized by status categories.
|
| 62 |
+
"""
|
| 63 |
+
token = Constants.HIVE_COMPUTE_DEFAULT_API_TOKEN
|
| 64 |
+
api_handler = HiveComputeAPI(token=token)
|
| 65 |
+
try:
|
| 66 |
+
logger.info(f"Listing all compute instances for token: {token}, category filter: {category}")
|
| 67 |
+
all_instances = api_handler.get_all_instances()
|
| 68 |
+
|
| 69 |
+
# Categorize instances into 4 groups
|
| 70 |
+
categorized = {
|
| 71 |
+
"RUNNING": [],
|
| 72 |
+
"STOPPED": [],
|
| 73 |
+
"ERRORED": [],
|
| 74 |
+
"TERMINATED": []
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
for inst in all_instances:
|
| 78 |
+
status = inst.status_string
|
| 79 |
+
# Map statuses to categories
|
| 80 |
+
if status in ["RUNNING"]:
|
| 81 |
+
categorized["RUNNING"].append(inst)
|
| 82 |
+
elif status in ["STOPPED"]:
|
| 83 |
+
categorized["STOPPED"].append(inst)
|
| 84 |
+
elif status == "ERRORED":
|
| 85 |
+
categorized["ERRORED"].append(inst)
|
| 86 |
+
elif status in ["TERMINATED"]:
|
| 87 |
+
categorized["TERMINATED"].append(inst)
|
| 88 |
+
|
| 89 |
+
# If category filter is specified, return only that category
|
| 90 |
+
if category and category.upper() in categorized:
|
| 91 |
+
return create_success_response(categorized[category.upper()])
|
| 92 |
+
|
| 93 |
+
# Otherwise return all categories
|
| 94 |
+
return create_success_response(categorized)
|
| 95 |
+
except Exception as e:
|
| 96 |
+
return handle_exception(e, "list_all_compute_instances")
|
Compute_MCP/utils.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from typing import Dict, Any
|
| 3 |
+
|
| 4 |
+
# Configure logging
|
| 5 |
+
logging.basicConfig(
|
| 6 |
+
level=logging.INFO,
|
| 7 |
+
format='[%(asctime)s][%(levelname)s] - %(message)s'
|
| 8 |
+
)
|
| 9 |
+
|
| 10 |
+
logger = logging.getLogger(__name__)
|
| 11 |
+
|
| 12 |
+
def create_success_response(result: Any) -> Dict[str, Any]:
|
| 13 |
+
"""Helper to create a standardized success response."""
|
| 14 |
+
return {
|
| 15 |
+
"status": "success",
|
| 16 |
+
"result": result
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
def handle_exception(e: Exception, operation: str) -> Dict[str, Any]:
|
| 20 |
+
"""Helper to standardize error responses."""
|
| 21 |
+
logger.exception(f"Error during {operation}: {e}")
|
| 22 |
+
return {
|
| 23 |
+
"status": "error",
|
| 24 |
+
"message": str(e),
|
| 25 |
+
"operation": operation
|
| 26 |
+
}
|
Dockerfile
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Use slim Python base
|
| 2 |
+
FROM python:3.12-bookworm
|
| 3 |
+
|
| 4 |
+
# Copy uv binaries from official distroless image
|
| 5 |
+
COPY --from=ghcr.io/astral-sh/uv:latest /uv /uvx /bin/
|
| 6 |
+
|
| 7 |
+
WORKDIR /app
|
| 8 |
+
|
| 9 |
+
# Copy project dependency files
|
| 10 |
+
#COPY pyproject.toml ./
|
| 11 |
+
#COPY uv.lock ./
|
| 12 |
+
|
| 13 |
+
# Install dependencies only (no project code)
|
| 14 |
+
COPY requirements.txt /home/temp/
|
| 15 |
+
RUN pip install --no-cache-dir -r /home/temp/requirements.txt
|
| 16 |
+
COPY . /home/hivenet/
|
| 17 |
+
WORKDIR /home/hivenet/
|
| 18 |
+
# Copy logo files to root directory for Gradio interface
|
| 19 |
+
RUN cp ComputeAgent/hivenet.jpg . 2>/dev/null || true
|
| 20 |
+
RUN cp ComputeAgent/ComputeAgent.png . 2>/dev/null || true
|
| 21 |
+
RUN cp run.sh /usr/bin/
|
| 22 |
+
RUN chmod +x /usr/bin/run.sh
|
| 23 |
+
|
| 24 |
+
# Run all the applications
|
| 25 |
+
# Port 7860: Gradio Web Interface
|
| 26 |
+
# Port 8000: ComputeAgent API
|
| 27 |
+
# MCP uses stdio (no port needed)
|
| 28 |
+
EXPOSE 7860 8000
|
| 29 |
+
CMD ["/usr/bin/run.sh"]
|
Gradio_interface.py
ADDED
|
@@ -0,0 +1,1374 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Enhanced Gradio Interface for ComputeAgent with Tool Approval Support
|
| 3 |
+
|
| 4 |
+
This interface supports BOTH capacity approval and tool approval with full
|
| 5 |
+
modification capabilities.
|
| 6 |
+
|
| 7 |
+
Features:
|
| 8 |
+
- Capacity approval (existing)
|
| 9 |
+
- Tool approval (NEW)
|
| 10 |
+
- Tool argument modification (NEW)
|
| 11 |
+
- Re-reasoning requests (NEW)
|
| 12 |
+
- Batch tool operations (NEW)
|
| 13 |
+
|
| 14 |
+
Author: ComputeAgent Team
|
| 15 |
+
"""
|
| 16 |
+
# This allows importing modules from the top-level project directory
|
| 17 |
+
import os
|
| 18 |
+
import sys
|
| 19 |
+
sys.path.append("/home/hivenet")
|
| 20 |
+
|
| 21 |
+
import asyncio
|
| 22 |
+
import gradio as gr
|
| 23 |
+
import httpx
|
| 24 |
+
import logging
|
| 25 |
+
from typing import Optional, Dict, Any, List, Tuple
|
| 26 |
+
from datetime import datetime
|
| 27 |
+
import json
|
| 28 |
+
import base64
|
| 29 |
+
from pathlib import Path
|
| 30 |
+
|
| 31 |
+
logging.basicConfig(level=logging.INFO)
|
| 32 |
+
logger = logging.getLogger("ComputeAgent-UI")
|
| 33 |
+
|
| 34 |
+
# FastAPI configuration
|
| 35 |
+
API_BASE_URL = "http://localhost:8000"
|
| 36 |
+
API_TIMEOUT = 300.0
|
| 37 |
+
|
| 38 |
+
# GPU/Location configuration
|
| 39 |
+
LOCATION_GPU_MAP = {
|
| 40 |
+
"France": ["RTX 4090"],
|
| 41 |
+
"UAE-1": ["RTX 4090"],
|
| 42 |
+
"Texas": ["RTX 5090"],
|
| 43 |
+
"UAE-2": ["RTX 5090"]
|
| 44 |
+
}
|
| 45 |
+
|
| 46 |
+
# Load and encode logo
|
| 47 |
+
def get_logo_base64(filename):
|
| 48 |
+
"""Load a logo and convert to base64 for embedding in HTML."""
|
| 49 |
+
try:
|
| 50 |
+
logo_path = Path(__file__).parent / filename
|
| 51 |
+
with open(logo_path, "rb") as f:
|
| 52 |
+
logo_bytes = f.read()
|
| 53 |
+
return base64.b64encode(logo_bytes).decode()
|
| 54 |
+
except Exception as e:
|
| 55 |
+
logger.warning(f"Could not load logo {filename}: {e}")
|
| 56 |
+
return None
|
| 57 |
+
|
| 58 |
+
HIVENET_LOGO_BASE64 = get_logo_base64("hivenet.jpg")
|
| 59 |
+
COMPUTEAGENT_LOGO_BASE64 = get_logo_base64("ComputeAgent.png")
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
class ComputeAgentClient:
|
| 63 |
+
"""Client for interacting with ComputeAgent FastAPI backend."""
|
| 64 |
+
|
| 65 |
+
def __init__(self, base_url: str = API_BASE_URL):
|
| 66 |
+
self.base_url = base_url
|
| 67 |
+
self.client = httpx.AsyncClient(timeout=API_TIMEOUT)
|
| 68 |
+
|
| 69 |
+
async def send_query(
|
| 70 |
+
self,
|
| 71 |
+
query: str,
|
| 72 |
+
user_id: str = "demo_user",
|
| 73 |
+
session_id: str = "demo_session"
|
| 74 |
+
) -> Dict[str, Any]:
|
| 75 |
+
"""Send query to FastAPI backend."""
|
| 76 |
+
try:
|
| 77 |
+
response = await self.client.post(
|
| 78 |
+
f"{self.base_url}/api/compute/query",
|
| 79 |
+
json={
|
| 80 |
+
"query": query,
|
| 81 |
+
"user_id": user_id,
|
| 82 |
+
"session_id": session_id
|
| 83 |
+
}
|
| 84 |
+
)
|
| 85 |
+
response.raise_for_status()
|
| 86 |
+
return response.json()
|
| 87 |
+
except Exception as e:
|
| 88 |
+
logger.error(f"❌ Error sending query: {e}")
|
| 89 |
+
return {"success": False, "error": str(e)}
|
| 90 |
+
|
| 91 |
+
async def continue_execution(
|
| 92 |
+
self,
|
| 93 |
+
thread_id: str,
|
| 94 |
+
user_input: Dict[str, Any]
|
| 95 |
+
) -> Dict[str, Any]:
|
| 96 |
+
"""Continue execution after interrupt."""
|
| 97 |
+
try:
|
| 98 |
+
response = await self.client.post(
|
| 99 |
+
f"{self.base_url}/api/compute/continue/{thread_id}",
|
| 100 |
+
json=user_input
|
| 101 |
+
)
|
| 102 |
+
response.raise_for_status()
|
| 103 |
+
return response.json()
|
| 104 |
+
except Exception as e:
|
| 105 |
+
logger.error(f"❌ Error continuing: {e}")
|
| 106 |
+
return {"success": False, "error": str(e)}
|
| 107 |
+
|
| 108 |
+
async def approve_tools(
|
| 109 |
+
self,
|
| 110 |
+
thread_id: str,
|
| 111 |
+
decision: Dict[str, Any]
|
| 112 |
+
) -> Dict[str, Any]:
|
| 113 |
+
"""Approve/reject/modify tools."""
|
| 114 |
+
try:
|
| 115 |
+
response = await self.client.post(
|
| 116 |
+
f"{self.base_url}/api/compute/approve-tools",
|
| 117 |
+
json={
|
| 118 |
+
"thread_id": thread_id,
|
| 119 |
+
**decision
|
| 120 |
+
}
|
| 121 |
+
)
|
| 122 |
+
response.raise_for_status()
|
| 123 |
+
return response.json()
|
| 124 |
+
except Exception as e:
|
| 125 |
+
logger.error(f"❌ Error with tool approval: {e}")
|
| 126 |
+
return {"success": False, "error": str(e)}
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
class ComputeAgentInterface:
|
| 130 |
+
"""Enhanced Gradio interface with tool approval."""
|
| 131 |
+
|
| 132 |
+
def __init__(self):
|
| 133 |
+
self.client = ComputeAgentClient()
|
| 134 |
+
self.current_thread_id = None
|
| 135 |
+
self.current_interrupt_data = None
|
| 136 |
+
self.approval_type = None # "capacity" or "tool"
|
| 137 |
+
self.selected_tools = set() # For tool selection
|
| 138 |
+
self.tool_modifications = {} # For tool argument mods
|
| 139 |
+
self.stats = {"total": 0, "successful": 0}
|
| 140 |
+
logger.info("🚀 ComputeAgent UI initialized with tool approval support")
|
| 141 |
+
|
| 142 |
+
def update_gpu_options(self, location: str):
|
| 143 |
+
"""Update GPU dropdown based on location."""
|
| 144 |
+
gpus = LOCATION_GPU_MAP.get(location, [])
|
| 145 |
+
return gr.update(choices=gpus, value=gpus[0] if gpus else None)
|
| 146 |
+
|
| 147 |
+
def get_stats_display(self) -> str:
|
| 148 |
+
"""Format stats display."""
|
| 149 |
+
success_rate = (self.stats["successful"] / max(1, self.stats["total"])) * 100
|
| 150 |
+
return f"""**📊 Session Statistics**
|
| 151 |
+
Total Requests: {self.stats["total"]}
|
| 152 |
+
Success Rate: {success_rate:.1f}%"""
|
| 153 |
+
|
| 154 |
+
async def process_query(
|
| 155 |
+
self,
|
| 156 |
+
message: str,
|
| 157 |
+
history: List,
|
| 158 |
+
user_id: str,
|
| 159 |
+
session_id: str
|
| 160 |
+
):
|
| 161 |
+
"""Process query through FastAPI."""
|
| 162 |
+
|
| 163 |
+
if not message.strip():
|
| 164 |
+
yield (
|
| 165 |
+
history, "",
|
| 166 |
+
gr.update(visible=False), # capacity_approval_panel
|
| 167 |
+
gr.update(visible=False), # capacity_param_panel
|
| 168 |
+
gr.update(visible=False), # tool_approval_panel
|
| 169 |
+
gr.update(visible=False), # tool_list_panel
|
| 170 |
+
self.get_stats_display()
|
| 171 |
+
)
|
| 172 |
+
return
|
| 173 |
+
|
| 174 |
+
user_id = user_id.strip() or "demo_user"
|
| 175 |
+
session_id = session_id.strip() or f"session_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
|
| 176 |
+
|
| 177 |
+
# Add user message
|
| 178 |
+
history.append([message, "🤖 **Processing...**"])
|
| 179 |
+
yield (
|
| 180 |
+
history, "",
|
| 181 |
+
gr.update(visible=False),
|
| 182 |
+
gr.update(visible=False),
|
| 183 |
+
gr.update(visible=False),
|
| 184 |
+
gr.update(visible=False),
|
| 185 |
+
self.get_stats_display()
|
| 186 |
+
)
|
| 187 |
+
|
| 188 |
+
try:
|
| 189 |
+
# Send to API
|
| 190 |
+
result = await self.client.send_query(message, user_id, session_id)
|
| 191 |
+
|
| 192 |
+
if not result.get("success"):
|
| 193 |
+
error_msg = f"❌ **Error:** {result.get('error', 'Unknown error')}"
|
| 194 |
+
history[-1][1] = error_msg
|
| 195 |
+
yield (
|
| 196 |
+
history, "",
|
| 197 |
+
gr.update(visible=False),
|
| 198 |
+
gr.update(visible=False),
|
| 199 |
+
gr.update(visible=False),
|
| 200 |
+
gr.update(visible=False),
|
| 201 |
+
self.get_stats_display()
|
| 202 |
+
)
|
| 203 |
+
return
|
| 204 |
+
|
| 205 |
+
# Check if waiting for approval (interrupt)
|
| 206 |
+
if result.get("state") == "waiting_for_input":
|
| 207 |
+
self.current_thread_id = result.get("thread_id")
|
| 208 |
+
self.current_interrupt_data = result.get("interrupt_data", {})
|
| 209 |
+
|
| 210 |
+
# Determine approval type
|
| 211 |
+
if "tool_calls" in self.current_interrupt_data:
|
| 212 |
+
# Tool approval
|
| 213 |
+
self.approval_type = "tool"
|
| 214 |
+
formatted_response = self._format_tool_approval(self.current_interrupt_data)
|
| 215 |
+
history[-1][1] = formatted_response
|
| 216 |
+
|
| 217 |
+
yield (
|
| 218 |
+
history, "",
|
| 219 |
+
gr.update(visible=False), # capacity panels hidden
|
| 220 |
+
gr.update(visible=False),
|
| 221 |
+
gr.update(visible=True), # tool approval visible
|
| 222 |
+
gr.update(visible=True), # tool list visible
|
| 223 |
+
self.get_stats_display()
|
| 224 |
+
)
|
| 225 |
+
else:
|
| 226 |
+
# Capacity approval
|
| 227 |
+
self.approval_type = "capacity"
|
| 228 |
+
formatted_response = self.current_interrupt_data.get(
|
| 229 |
+
"formatted_response",
|
| 230 |
+
self._format_basic_capacity(self.current_interrupt_data)
|
| 231 |
+
)
|
| 232 |
+
history[-1][1] = formatted_response
|
| 233 |
+
|
| 234 |
+
yield (
|
| 235 |
+
history, "",
|
| 236 |
+
gr.update(visible=True), # capacity approval visible
|
| 237 |
+
gr.update(visible=False),
|
| 238 |
+
gr.update(visible=False), # tool panels hidden
|
| 239 |
+
gr.update(visible=False),
|
| 240 |
+
self.get_stats_display()
|
| 241 |
+
)
|
| 242 |
+
return
|
| 243 |
+
|
| 244 |
+
# Normal completion
|
| 245 |
+
response_text = result.get("response", "Request completed")
|
| 246 |
+
history[-1][1] = response_text
|
| 247 |
+
|
| 248 |
+
self.stats["total"] += 1
|
| 249 |
+
self.stats["successful"] += 1
|
| 250 |
+
|
| 251 |
+
yield (
|
| 252 |
+
history, "",
|
| 253 |
+
gr.update(visible=False),
|
| 254 |
+
gr.update(visible=False),
|
| 255 |
+
gr.update(visible=False),
|
| 256 |
+
gr.update(visible=False),
|
| 257 |
+
self.get_stats_display()
|
| 258 |
+
)
|
| 259 |
+
|
| 260 |
+
except Exception as e:
|
| 261 |
+
logger.error(f"❌ Error: {e}", exc_info=True)
|
| 262 |
+
history[-1][1] = f"❌ **Error:** {str(e)}"
|
| 263 |
+
yield (
|
| 264 |
+
history, "",
|
| 265 |
+
gr.update(visible=False),
|
| 266 |
+
gr.update(visible=False),
|
| 267 |
+
gr.update(visible=False),
|
| 268 |
+
gr.update(visible=False),
|
| 269 |
+
self.get_stats_display()
|
| 270 |
+
)
|
| 271 |
+
|
| 272 |
+
def _format_tool_approval(self, interrupt_data: Dict[str, Any]) -> str:
|
| 273 |
+
"""Format tool approval request for display."""
|
| 274 |
+
tool_calls = interrupt_data.get("tool_calls", [])
|
| 275 |
+
query = interrupt_data.get("query", "")
|
| 276 |
+
|
| 277 |
+
if not tool_calls:
|
| 278 |
+
return "⚠️ No tools proposed"
|
| 279 |
+
|
| 280 |
+
tools_list = []
|
| 281 |
+
for i, tool in enumerate(tool_calls):
|
| 282 |
+
tool_name = tool.get("name", "unknown")
|
| 283 |
+
tool_args = json.dumps(tool.get("args", {}), indent=2)
|
| 284 |
+
tool_desc = tool.get("description", "No description")
|
| 285 |
+
|
| 286 |
+
tools_list.append(f"""
|
| 287 |
+
**Tool {i+1}: {tool_name}**
|
| 288 |
+
- Description: {tool_desc}
|
| 289 |
+
- Arguments:
|
| 290 |
+
```json
|
| 291 |
+
{tool_args}
|
| 292 |
+
```
|
| 293 |
+
""")
|
| 294 |
+
|
| 295 |
+
tools_text = "\n".join(tools_list)
|
| 296 |
+
|
| 297 |
+
return f"""# 🔧 **Tool Approval Required**
|
| 298 |
+
|
| 299 |
+
**Query:** {query}
|
| 300 |
+
|
| 301 |
+
**Proposed Tools ({len(tool_calls)}):**
|
| 302 |
+
|
| 303 |
+
{tools_text}
|
| 304 |
+
|
| 305 |
+
⚠️ **Please review and approve, modify, or request re-reasoning.**
|
| 306 |
+
"""
|
| 307 |
+
|
| 308 |
+
def _format_basic_capacity(self, interrupt_data: Dict[str, Any]) -> str:
|
| 309 |
+
"""Basic capacity formatting if formatted_response not available."""
|
| 310 |
+
model_name = interrupt_data.get("model_name", "Unknown")
|
| 311 |
+
memory = interrupt_data.get("estimated_gpu_memory", 0)
|
| 312 |
+
gpu_reqs = interrupt_data.get("gpu_requirements", {})
|
| 313 |
+
|
| 314 |
+
gpu_lines = [f" • **{gpu}:** {count} GPU{'s' if count > 1 else ''}"
|
| 315 |
+
for gpu, count in gpu_reqs.items()]
|
| 316 |
+
gpu_text = "\n".join(gpu_lines) if gpu_lines else " • No requirements"
|
| 317 |
+
|
| 318 |
+
return f"""# 📊 **Capacity Estimation**
|
| 319 |
+
|
| 320 |
+
**Model:** `{model_name}`
|
| 321 |
+
**Estimated GPU Memory:** **{memory:.2f} GB**
|
| 322 |
+
|
| 323 |
+
**GPU Requirements:**
|
| 324 |
+
{gpu_text}
|
| 325 |
+
|
| 326 |
+
⚠️ **Please review and approve or modify the configuration.**
|
| 327 |
+
"""
|
| 328 |
+
|
| 329 |
+
def build_tool_checkboxes(self):
|
| 330 |
+
"""Build checkbox UI for tool selection."""
|
| 331 |
+
if not self.current_interrupt_data or "tool_calls" not in self.current_interrupt_data:
|
| 332 |
+
return []
|
| 333 |
+
|
| 334 |
+
tool_calls = self.current_interrupt_data.get("tool_calls", [])
|
| 335 |
+
|
| 336 |
+
# Return list of tool names with indices
|
| 337 |
+
return [
|
| 338 |
+
f"[{i}] {tool.get('name', 'unknown')}: {json.dumps(tool.get('args', {}))}"
|
| 339 |
+
for i, tool in enumerate(tool_calls)
|
| 340 |
+
]
|
| 341 |
+
|
| 342 |
+
# ========================================================================
|
| 343 |
+
# CAPACITY APPROVAL HANDLERS
|
| 344 |
+
# ========================================================================
|
| 345 |
+
|
| 346 |
+
async def approve_capacity(self, history: List, user_id: str, session_id: str):
|
| 347 |
+
"""Handle capacity approval."""
|
| 348 |
+
if not self.current_thread_id or self.approval_type != "capacity":
|
| 349 |
+
history.append([None, "⚠️ No pending capacity approval"])
|
| 350 |
+
yield (
|
| 351 |
+
history,
|
| 352 |
+
gr.update(visible=False),
|
| 353 |
+
gr.update(visible=False),
|
| 354 |
+
gr.update(visible=False),
|
| 355 |
+
gr.update(visible=False),
|
| 356 |
+
self.get_stats_display()
|
| 357 |
+
)
|
| 358 |
+
return
|
| 359 |
+
|
| 360 |
+
history.append(["✅ **Approved Capacity**", "🚀 **Continuing deployment...**"])
|
| 361 |
+
yield (
|
| 362 |
+
history,
|
| 363 |
+
gr.update(visible=False),
|
| 364 |
+
gr.update(visible=False),
|
| 365 |
+
gr.update(visible=False),
|
| 366 |
+
gr.update(visible=False),
|
| 367 |
+
self.get_stats_display()
|
| 368 |
+
)
|
| 369 |
+
|
| 370 |
+
try:
|
| 371 |
+
approval_input = {
|
| 372 |
+
"capacity_approved": True,
|
| 373 |
+
"custom_config": {},
|
| 374 |
+
"needs_re_estimation": False
|
| 375 |
+
}
|
| 376 |
+
|
| 377 |
+
result = await self.client.continue_execution(
|
| 378 |
+
self.current_thread_id,
|
| 379 |
+
approval_input
|
| 380 |
+
)
|
| 381 |
+
|
| 382 |
+
# Check if there's another interrupt (e.g., tool approval after capacity approval)
|
| 383 |
+
if result.get("state") == "waiting_for_input":
|
| 384 |
+
self.current_interrupt_data = result.get("interrupt_data", {})
|
| 385 |
+
|
| 386 |
+
# Determine approval type
|
| 387 |
+
if "tool_calls" in self.current_interrupt_data:
|
| 388 |
+
# Tool approval needed
|
| 389 |
+
self.approval_type = "tool"
|
| 390 |
+
formatted_response = self._format_tool_approval(self.current_interrupt_data)
|
| 391 |
+
history[-1][1] = formatted_response
|
| 392 |
+
|
| 393 |
+
yield (
|
| 394 |
+
history,
|
| 395 |
+
gr.update(visible=False), # capacity panels hidden
|
| 396 |
+
gr.update(visible=False),
|
| 397 |
+
gr.update(visible=True), # tool approval visible
|
| 398 |
+
gr.update(visible=True), # tool list visible
|
| 399 |
+
self.get_stats_display()
|
| 400 |
+
)
|
| 401 |
+
else:
|
| 402 |
+
# Another capacity approval (re-estimation)
|
| 403 |
+
self.approval_type = "capacity"
|
| 404 |
+
formatted_response = self.current_interrupt_data.get(
|
| 405 |
+
"formatted_response",
|
| 406 |
+
self._format_basic_capacity(self.current_interrupt_data)
|
| 407 |
+
)
|
| 408 |
+
history[-1][1] = formatted_response
|
| 409 |
+
|
| 410 |
+
yield (
|
| 411 |
+
history,
|
| 412 |
+
gr.update(visible=True), # capacity approval visible
|
| 413 |
+
gr.update(visible=False),
|
| 414 |
+
gr.update(visible=False), # tool panels hidden
|
| 415 |
+
gr.update(visible=False),
|
| 416 |
+
self.get_stats_display()
|
| 417 |
+
)
|
| 418 |
+
return
|
| 419 |
+
|
| 420 |
+
# Normal completion
|
| 421 |
+
if result.get("success"):
|
| 422 |
+
response = result.get("response", "Deployment completed")
|
| 423 |
+
history[-1][1] = f"✅ **{response}**"
|
| 424 |
+
self.stats["total"] += 1
|
| 425 |
+
self.stats["successful"] += 1
|
| 426 |
+
else:
|
| 427 |
+
history[-1][1] = f"❌ **Error:** {result.get('error', 'Unknown error')}"
|
| 428 |
+
|
| 429 |
+
self._clear_approval_state()
|
| 430 |
+
|
| 431 |
+
yield (
|
| 432 |
+
history,
|
| 433 |
+
gr.update(visible=False),
|
| 434 |
+
gr.update(visible=False),
|
| 435 |
+
gr.update(visible=False),
|
| 436 |
+
gr.update(visible=False),
|
| 437 |
+
self.get_stats_display()
|
| 438 |
+
)
|
| 439 |
+
|
| 440 |
+
except Exception as e:
|
| 441 |
+
logger.error(f"❌ Approval error: {e}")
|
| 442 |
+
history[-1][1] = f"❌ **Error:** {str(e)}"
|
| 443 |
+
yield (
|
| 444 |
+
history,
|
| 445 |
+
gr.update(visible=False),
|
| 446 |
+
gr.update(visible=False),
|
| 447 |
+
gr.update(visible=False),
|
| 448 |
+
gr.update(visible=False),
|
| 449 |
+
self.get_stats_display()
|
| 450 |
+
)
|
| 451 |
+
|
| 452 |
+
async def reject_capacity(self, history: List, user_id: str, session_id: str):
|
| 453 |
+
"""Handle capacity rejection."""
|
| 454 |
+
if not self.current_thread_id or self.approval_type != "capacity":
|
| 455 |
+
return self._no_approval_response(history)
|
| 456 |
+
|
| 457 |
+
history.append(["❌ **Rejected Capacity**", "Deployment cancelled"])
|
| 458 |
+
|
| 459 |
+
rejection_input = {
|
| 460 |
+
"capacity_approved": False,
|
| 461 |
+
"custom_config": {},
|
| 462 |
+
"needs_re_estimation": False
|
| 463 |
+
}
|
| 464 |
+
|
| 465 |
+
await self.client.continue_execution(self.current_thread_id, rejection_input)
|
| 466 |
+
self._clear_approval_state()
|
| 467 |
+
|
| 468 |
+
return (
|
| 469 |
+
history,
|
| 470 |
+
gr.update(visible=False),
|
| 471 |
+
gr.update(visible=False),
|
| 472 |
+
gr.update(visible=False),
|
| 473 |
+
gr.update(visible=False),
|
| 474 |
+
self.get_stats_display()
|
| 475 |
+
)
|
| 476 |
+
|
| 477 |
+
async def apply_capacity_modifications(
|
| 478 |
+
self,
|
| 479 |
+
history: List,
|
| 480 |
+
user_id: str,
|
| 481 |
+
session_id: str,
|
| 482 |
+
max_model_len: int,
|
| 483 |
+
max_num_seqs: int,
|
| 484 |
+
max_batched_tokens: int,
|
| 485 |
+
kv_cache_dtype: str,
|
| 486 |
+
gpu_util: float,
|
| 487 |
+
location: str,
|
| 488 |
+
gpu_type: str
|
| 489 |
+
):
|
| 490 |
+
"""Apply capacity modifications and re-estimate."""
|
| 491 |
+
if not self.current_thread_id or self.approval_type != "capacity":
|
| 492 |
+
history.append([None, "⚠️ No pending capacity approval"])
|
| 493 |
+
yield self._all_hidden_response(history)
|
| 494 |
+
return
|
| 495 |
+
|
| 496 |
+
history.append(["🔧 **Re-estimating with new parameters...**", "⏳ **Please wait...**"])
|
| 497 |
+
yield self._all_hidden_response(history)
|
| 498 |
+
|
| 499 |
+
try:
|
| 500 |
+
custom_config = {
|
| 501 |
+
"GPU_type": gpu_type,
|
| 502 |
+
"location": location,
|
| 503 |
+
"max_model_len": int(max_model_len),
|
| 504 |
+
"max_num_seqs": int(max_num_seqs),
|
| 505 |
+
"max_num_batched_tokens": int(max_batched_tokens),
|
| 506 |
+
"kv_cache_dtype": kv_cache_dtype,
|
| 507 |
+
"gpu_memory_utilization": float(gpu_util)
|
| 508 |
+
}
|
| 509 |
+
|
| 510 |
+
re_estimate_input = {
|
| 511 |
+
"capacity_approved": None,
|
| 512 |
+
"custom_config": custom_config,
|
| 513 |
+
"needs_re_estimation": True
|
| 514 |
+
}
|
| 515 |
+
|
| 516 |
+
result = await self.client.continue_execution(
|
| 517 |
+
self.current_thread_id,
|
| 518 |
+
re_estimate_input
|
| 519 |
+
)
|
| 520 |
+
|
| 521 |
+
# Check if still waiting for input (could be capacity or tool approval)
|
| 522 |
+
if result.get("state") == "waiting_for_input":
|
| 523 |
+
self.current_interrupt_data = result.get("interrupt_data", {})
|
| 524 |
+
|
| 525 |
+
# Determine approval type
|
| 526 |
+
if "tool_calls" in self.current_interrupt_data:
|
| 527 |
+
# Tool approval needed after re-estimation
|
| 528 |
+
self.approval_type = "tool"
|
| 529 |
+
formatted_response = self._format_tool_approval(self.current_interrupt_data)
|
| 530 |
+
history[-1][1] = formatted_response
|
| 531 |
+
|
| 532 |
+
yield (
|
| 533 |
+
history,
|
| 534 |
+
gr.update(visible=False), # capacity panels hidden
|
| 535 |
+
gr.update(visible=False),
|
| 536 |
+
gr.update(visible=True), # tool approval visible
|
| 537 |
+
gr.update(visible=True), # tool list visible
|
| 538 |
+
self.get_stats_display()
|
| 539 |
+
)
|
| 540 |
+
else:
|
| 541 |
+
# Another capacity approval (re-estimation result)
|
| 542 |
+
self.approval_type = "capacity"
|
| 543 |
+
formatted_response = self.current_interrupt_data.get(
|
| 544 |
+
"formatted_response",
|
| 545 |
+
self._format_basic_capacity(self.current_interrupt_data)
|
| 546 |
+
)
|
| 547 |
+
history[-1][1] = formatted_response
|
| 548 |
+
|
| 549 |
+
yield (
|
| 550 |
+
history,
|
| 551 |
+
gr.update(visible=True), # Show capacity approval
|
| 552 |
+
gr.update(visible=False),
|
| 553 |
+
gr.update(visible=False),
|
| 554 |
+
gr.update(visible=False),
|
| 555 |
+
self.get_stats_display()
|
| 556 |
+
)
|
| 557 |
+
else:
|
| 558 |
+
# Completed without further interrupts
|
| 559 |
+
response = result.get("response", "Re-estimation completed")
|
| 560 |
+
history[-1][1] = f"✅ **{response}**"
|
| 561 |
+
self._clear_approval_state()
|
| 562 |
+
yield self._all_hidden_response(history)
|
| 563 |
+
|
| 564 |
+
except Exception as e:
|
| 565 |
+
logger.error(f"❌ Re-estimation error: {e}")
|
| 566 |
+
history[-1][1] = f"❌ **Error:** {str(e)}"
|
| 567 |
+
yield self._all_hidden_response(history)
|
| 568 |
+
|
| 569 |
+
# ========================================================================
|
| 570 |
+
# TOOL APPROVAL HANDLERS
|
| 571 |
+
# ========================================================================
|
| 572 |
+
|
| 573 |
+
async def approve_all_tools(self, history: List, user_id: str, session_id: str):
|
| 574 |
+
"""Approve all tools."""
|
| 575 |
+
if not self.current_thread_id or self.approval_type != "tool":
|
| 576 |
+
history.append([None, "⚠️ No pending tool approval"])
|
| 577 |
+
yield self._all_hidden_response(history)
|
| 578 |
+
return
|
| 579 |
+
|
| 580 |
+
history.append(["✅ **Approved All Tools**", "⚡ **Executing tools...**"])
|
| 581 |
+
yield self._all_hidden_response(history)
|
| 582 |
+
|
| 583 |
+
try:
|
| 584 |
+
result = await self.client.approve_tools(
|
| 585 |
+
self.current_thread_id,
|
| 586 |
+
{"action": "approve_all"}
|
| 587 |
+
)
|
| 588 |
+
|
| 589 |
+
# Check if there's another interrupt (agent proposing more tools)
|
| 590 |
+
if result.get("state") == "waiting_for_input":
|
| 591 |
+
self.current_interrupt_data = result.get("interrupt_data", {})
|
| 592 |
+
|
| 593 |
+
# Determine approval type
|
| 594 |
+
if "tool_calls" in self.current_interrupt_data:
|
| 595 |
+
# More tools proposed
|
| 596 |
+
self.approval_type = "tool"
|
| 597 |
+
formatted_response = self._format_tool_approval(self.current_interrupt_data)
|
| 598 |
+
history[-1][1] = formatted_response
|
| 599 |
+
|
| 600 |
+
yield (
|
| 601 |
+
history,
|
| 602 |
+
gr.update(visible=False),
|
| 603 |
+
gr.update(visible=False),
|
| 604 |
+
gr.update(visible=True), # tool approval visible
|
| 605 |
+
gr.update(visible=True), # tool list visible
|
| 606 |
+
self.get_stats_display()
|
| 607 |
+
)
|
| 608 |
+
else:
|
| 609 |
+
# Unexpected capacity approval
|
| 610 |
+
self.approval_type = "capacity"
|
| 611 |
+
formatted_response = self.current_interrupt_data.get(
|
| 612 |
+
"formatted_response",
|
| 613 |
+
self._format_basic_capacity(self.current_interrupt_data)
|
| 614 |
+
)
|
| 615 |
+
history[-1][1] = formatted_response
|
| 616 |
+
|
| 617 |
+
yield (
|
| 618 |
+
history,
|
| 619 |
+
gr.update(visible=True), # capacity approval visible
|
| 620 |
+
gr.update(visible=False),
|
| 621 |
+
gr.update(visible=False),
|
| 622 |
+
gr.update(visible=False),
|
| 623 |
+
self.get_stats_display()
|
| 624 |
+
)
|
| 625 |
+
return
|
| 626 |
+
|
| 627 |
+
# Normal completion
|
| 628 |
+
if result.get("success"):
|
| 629 |
+
response = result.get("response", "Tools executed successfully")
|
| 630 |
+
history[-1][1] = f"✅ **{response}**"
|
| 631 |
+
self.stats["total"] += 1
|
| 632 |
+
self.stats["successful"] += 1
|
| 633 |
+
else:
|
| 634 |
+
history[-1][1] = f"❌ **Error:** {result.get('error', 'Unknown error')}"
|
| 635 |
+
|
| 636 |
+
self._clear_approval_state()
|
| 637 |
+
yield self._all_hidden_response(history)
|
| 638 |
+
|
| 639 |
+
except Exception as e:
|
| 640 |
+
logger.error(f"❌ Tool approval error: {e}")
|
| 641 |
+
history[-1][1] = f"❌ **Error:** {str(e)}"
|
| 642 |
+
yield self._all_hidden_response(history)
|
| 643 |
+
|
| 644 |
+
async def reject_all_tools(self, history: List, user_id: str, session_id: str):
|
| 645 |
+
"""Reject all tools."""
|
| 646 |
+
if not self.current_thread_id or self.approval_type != "tool":
|
| 647 |
+
return self._no_approval_response(history)
|
| 648 |
+
|
| 649 |
+
history.append(["❌ **Rejected All Tools**", "Generating response without tools..."])
|
| 650 |
+
|
| 651 |
+
try:
|
| 652 |
+
result = await self.client.approve_tools(
|
| 653 |
+
self.current_thread_id,
|
| 654 |
+
{"action": "reject_all"}
|
| 655 |
+
)
|
| 656 |
+
|
| 657 |
+
if result.get("success"):
|
| 658 |
+
response = result.get("response", "Completed without tools")
|
| 659 |
+
history[-1][1] = f"✅ **{response}**"
|
| 660 |
+
else:
|
| 661 |
+
history[-1][1] = f"❌ **Error:** {result.get('error', 'Unknown error')}"
|
| 662 |
+
|
| 663 |
+
self._clear_approval_state()
|
| 664 |
+
|
| 665 |
+
except Exception as e:
|
| 666 |
+
logger.error(f"❌ Tool rejection error: {e}")
|
| 667 |
+
history[-1][1] = f"❌ **Error:** {str(e)}"
|
| 668 |
+
|
| 669 |
+
return self._all_hidden_response(history)
|
| 670 |
+
|
| 671 |
+
async def approve_selected_tools(
|
| 672 |
+
self,
|
| 673 |
+
history: List,
|
| 674 |
+
user_id: str,
|
| 675 |
+
session_id: str,
|
| 676 |
+
selected_indices: str
|
| 677 |
+
):
|
| 678 |
+
"""Approve selected tools by indices."""
|
| 679 |
+
if not self.current_thread_id or self.approval_type != "tool":
|
| 680 |
+
history.append([None, "⚠️ No pending tool approval"])
|
| 681 |
+
yield self._all_hidden_response(history)
|
| 682 |
+
return
|
| 683 |
+
|
| 684 |
+
# Parse indices (convert from 1-based to 0-based)
|
| 685 |
+
try:
|
| 686 |
+
# User enters 1-based indices (1,2,3), convert to 0-based (0,1,2)
|
| 687 |
+
indices = [int(i.strip()) - 1 for i in selected_indices.split(",") if i.strip()]
|
| 688 |
+
# Validate indices are non-negative
|
| 689 |
+
if any(idx < 0 for idx in indices):
|
| 690 |
+
history.append([None, "❌ Tool indices must be positive numbers (starting from 1). Example: 1,2,3"])
|
| 691 |
+
yield self._all_hidden_response(history)
|
| 692 |
+
return
|
| 693 |
+
except:
|
| 694 |
+
history.append([None, "❌ Invalid indices format. Use: 1,2,3 (starting from 1)"])
|
| 695 |
+
yield self._all_hidden_response(history)
|
| 696 |
+
return
|
| 697 |
+
|
| 698 |
+
history.append([
|
| 699 |
+
f"✅ **Approved Tools: {indices}**",
|
| 700 |
+
"⚡ **Executing selected tools...**"
|
| 701 |
+
])
|
| 702 |
+
yield self._all_hidden_response(history)
|
| 703 |
+
|
| 704 |
+
try:
|
| 705 |
+
result = await self.client.approve_tools(
|
| 706 |
+
self.current_thread_id,
|
| 707 |
+
{
|
| 708 |
+
"action": "approve_selected",
|
| 709 |
+
"tool_indices": indices
|
| 710 |
+
}
|
| 711 |
+
)
|
| 712 |
+
|
| 713 |
+
# Check if there's another interrupt
|
| 714 |
+
if result.get("state") == "waiting_for_input":
|
| 715 |
+
self.current_interrupt_data = result.get("interrupt_data", {})
|
| 716 |
+
|
| 717 |
+
if "tool_calls" in self.current_interrupt_data:
|
| 718 |
+
self.approval_type = "tool"
|
| 719 |
+
formatted_response = self._format_tool_approval(self.current_interrupt_data)
|
| 720 |
+
history[-1][1] = formatted_response
|
| 721 |
+
|
| 722 |
+
yield (
|
| 723 |
+
history,
|
| 724 |
+
gr.update(visible=False),
|
| 725 |
+
gr.update(visible=False),
|
| 726 |
+
gr.update(visible=True),
|
| 727 |
+
gr.update(visible=True),
|
| 728 |
+
self.get_stats_display()
|
| 729 |
+
)
|
| 730 |
+
else:
|
| 731 |
+
self.approval_type = "capacity"
|
| 732 |
+
formatted_response = self.current_interrupt_data.get(
|
| 733 |
+
"formatted_response",
|
| 734 |
+
self._format_basic_capacity(self.current_interrupt_data)
|
| 735 |
+
)
|
| 736 |
+
history[-1][1] = formatted_response
|
| 737 |
+
|
| 738 |
+
yield (
|
| 739 |
+
history,
|
| 740 |
+
gr.update(visible=True),
|
| 741 |
+
gr.update(visible=False),
|
| 742 |
+
gr.update(visible=False),
|
| 743 |
+
gr.update(visible=False),
|
| 744 |
+
self.get_stats_display()
|
| 745 |
+
)
|
| 746 |
+
return
|
| 747 |
+
|
| 748 |
+
# Normal completion
|
| 749 |
+
if result.get("success"):
|
| 750 |
+
response = result.get("response", "Selected tools executed")
|
| 751 |
+
history[-1][1] = f"✅ **{response}**"
|
| 752 |
+
self.stats["total"] += 1
|
| 753 |
+
self.stats["successful"] += 1
|
| 754 |
+
else:
|
| 755 |
+
history[-1][1] = f"❌ **Error:** {result.get('error', 'Unknown error')}"
|
| 756 |
+
|
| 757 |
+
self._clear_approval_state()
|
| 758 |
+
yield self._all_hidden_response(history)
|
| 759 |
+
|
| 760 |
+
except Exception as e:
|
| 761 |
+
logger.error(f"❌ Tool approval error: {e}")
|
| 762 |
+
history[-1][1] = f"❌ **Error:** {str(e)}"
|
| 763 |
+
yield self._all_hidden_response(history)
|
| 764 |
+
|
| 765 |
+
async def request_re_reasoning(
|
| 766 |
+
self,
|
| 767 |
+
history: List,
|
| 768 |
+
user_id: str,
|
| 769 |
+
session_id: str,
|
| 770 |
+
feedback: str
|
| 771 |
+
):
|
| 772 |
+
"""Request agent re-reasoning with feedback."""
|
| 773 |
+
if not self.current_thread_id or self.approval_type != "tool":
|
| 774 |
+
history.append([None, "⚠️ No pending tool approval"])
|
| 775 |
+
yield self._all_hidden_response(history)
|
| 776 |
+
return
|
| 777 |
+
|
| 778 |
+
if not feedback.strip():
|
| 779 |
+
history.append([None, "❌ Please provide feedback for re-reasoning"])
|
| 780 |
+
yield self._all_hidden_response(history)
|
| 781 |
+
return
|
| 782 |
+
|
| 783 |
+
history.append([
|
| 784 |
+
f"🔄 **Re-reasoning Request:** {feedback}",
|
| 785 |
+
"🤔 **Agent reconsidering approach...**"
|
| 786 |
+
])
|
| 787 |
+
yield self._all_hidden_response(history)
|
| 788 |
+
|
| 789 |
+
try:
|
| 790 |
+
result = await self.client.approve_tools(
|
| 791 |
+
self.current_thread_id,
|
| 792 |
+
{
|
| 793 |
+
"action": "request_re_reasoning",
|
| 794 |
+
"feedback": feedback
|
| 795 |
+
}
|
| 796 |
+
)
|
| 797 |
+
|
| 798 |
+
# Should get new tool proposals
|
| 799 |
+
if result.get("state") == "waiting_for_input":
|
| 800 |
+
self.current_interrupt_data = result.get("interrupt_data", {})
|
| 801 |
+
formatted_response = self._format_tool_approval(self.current_interrupt_data)
|
| 802 |
+
history[-1][1] = formatted_response
|
| 803 |
+
|
| 804 |
+
yield (
|
| 805 |
+
history,
|
| 806 |
+
gr.update(visible=False),
|
| 807 |
+
gr.update(visible=False),
|
| 808 |
+
gr.update(visible=True), # tool approval visible
|
| 809 |
+
gr.update(visible=True), # tool list visible
|
| 810 |
+
self.get_stats_display()
|
| 811 |
+
)
|
| 812 |
+
else:
|
| 813 |
+
response = result.get("response", "Re-reasoning completed")
|
| 814 |
+
history[-1][1] = f"✅ **{response}**"
|
| 815 |
+
self._clear_approval_state()
|
| 816 |
+
yield self._all_hidden_response(history)
|
| 817 |
+
|
| 818 |
+
except Exception as e:
|
| 819 |
+
logger.error(f"❌ Re-reasoning error: {e}")
|
| 820 |
+
history[-1][1] = f"❌ **Error:** {str(e)}"
|
| 821 |
+
yield self._all_hidden_response(history)
|
| 822 |
+
|
| 823 |
+
async def modify_tool_args(
|
| 824 |
+
self,
|
| 825 |
+
history: List,
|
| 826 |
+
user_id: str,
|
| 827 |
+
session_id: str,
|
| 828 |
+
tool_index: int,
|
| 829 |
+
new_args_json: str
|
| 830 |
+
):
|
| 831 |
+
"""Modify tool arguments and approve."""
|
| 832 |
+
if not self.current_thread_id or self.approval_type != "tool":
|
| 833 |
+
history.append([None, "⚠️ No pending tool approval"])
|
| 834 |
+
yield self._all_hidden_response(history)
|
| 835 |
+
return
|
| 836 |
+
|
| 837 |
+
# Parse new arguments
|
| 838 |
+
try:
|
| 839 |
+
new_args = json.loads(new_args_json)
|
| 840 |
+
except:
|
| 841 |
+
history.append([None, "❌ Invalid JSON format for arguments"])
|
| 842 |
+
yield self._all_hidden_response(history)
|
| 843 |
+
return
|
| 844 |
+
|
| 845 |
+
history.append([
|
| 846 |
+
f"🔧 **Modified Tool {tool_index}**",
|
| 847 |
+
"⚡ **Executing with new arguments...**"
|
| 848 |
+
])
|
| 849 |
+
yield self._all_hidden_response(history)
|
| 850 |
+
|
| 851 |
+
# Convert from 1-based to 0-based index for backend
|
| 852 |
+
backend_index = tool_index - 1
|
| 853 |
+
if backend_index < 0:
|
| 854 |
+
history.append([None, "❌ Tool index must be positive (starting from 1)"])
|
| 855 |
+
yield self._all_hidden_response(history)
|
| 856 |
+
return
|
| 857 |
+
|
| 858 |
+
try:
|
| 859 |
+
result = await self.client.approve_tools(
|
| 860 |
+
self.current_thread_id,
|
| 861 |
+
{
|
| 862 |
+
"action": "modify_and_approve",
|
| 863 |
+
"modifications": [
|
| 864 |
+
{
|
| 865 |
+
"tool_index": backend_index,
|
| 866 |
+
"new_args": new_args,
|
| 867 |
+
"approve": True
|
| 868 |
+
}
|
| 869 |
+
]
|
| 870 |
+
}
|
| 871 |
+
)
|
| 872 |
+
|
| 873 |
+
# Check if there's another interrupt
|
| 874 |
+
if result.get("state") == "waiting_for_input":
|
| 875 |
+
self.current_interrupt_data = result.get("interrupt_data", {})
|
| 876 |
+
|
| 877 |
+
if "tool_calls" in self.current_interrupt_data:
|
| 878 |
+
self.approval_type = "tool"
|
| 879 |
+
formatted_response = self._format_tool_approval(self.current_interrupt_data)
|
| 880 |
+
history[-1][1] = formatted_response
|
| 881 |
+
|
| 882 |
+
yield (
|
| 883 |
+
history,
|
| 884 |
+
gr.update(visible=False),
|
| 885 |
+
gr.update(visible=False),
|
| 886 |
+
gr.update(visible=True),
|
| 887 |
+
gr.update(visible=True),
|
| 888 |
+
self.get_stats_display()
|
| 889 |
+
)
|
| 890 |
+
else:
|
| 891 |
+
self.approval_type = "capacity"
|
| 892 |
+
formatted_response = self.current_interrupt_data.get(
|
| 893 |
+
"formatted_response",
|
| 894 |
+
self._format_basic_capacity(self.current_interrupt_data)
|
| 895 |
+
)
|
| 896 |
+
history[-1][1] = formatted_response
|
| 897 |
+
|
| 898 |
+
yield (
|
| 899 |
+
history,
|
| 900 |
+
gr.update(visible=True),
|
| 901 |
+
gr.update(visible=False),
|
| 902 |
+
gr.update(visible=False),
|
| 903 |
+
gr.update(visible=False),
|
| 904 |
+
self.get_stats_display()
|
| 905 |
+
)
|
| 906 |
+
return
|
| 907 |
+
|
| 908 |
+
# Normal completion
|
| 909 |
+
if result.get("success"):
|
| 910 |
+
response = result.get("response", "Tool executed with modifications")
|
| 911 |
+
history[-1][1] = f"✅ **{response}**"
|
| 912 |
+
self.stats["total"] += 1
|
| 913 |
+
self.stats["successful"] += 1
|
| 914 |
+
else:
|
| 915 |
+
history[-1][1] = f"❌ **Error:** {result.get('error', 'Unknown error')}"
|
| 916 |
+
|
| 917 |
+
self._clear_approval_state()
|
| 918 |
+
yield self._all_hidden_response(history)
|
| 919 |
+
|
| 920 |
+
except Exception as e:
|
| 921 |
+
logger.error(f"❌ Modification error: {e}")
|
| 922 |
+
history[-1][1] = f"❌ **Error:** {str(e)}"
|
| 923 |
+
yield self._all_hidden_response(history)
|
| 924 |
+
|
| 925 |
+
# ========================================================================
|
| 926 |
+
# HELPER METHODS
|
| 927 |
+
# ========================================================================
|
| 928 |
+
|
| 929 |
+
def _clear_approval_state(self):
|
| 930 |
+
"""Clear all approval state."""
|
| 931 |
+
self.current_thread_id = None
|
| 932 |
+
self.current_interrupt_data = None
|
| 933 |
+
self.approval_type = None
|
| 934 |
+
self.selected_tools = set()
|
| 935 |
+
self.tool_modifications = {}
|
| 936 |
+
|
| 937 |
+
def _all_hidden_response(self, history):
|
| 938 |
+
"""Return response with all panels hidden."""
|
| 939 |
+
return (
|
| 940 |
+
history,
|
| 941 |
+
gr.update(visible=False),
|
| 942 |
+
gr.update(visible=False),
|
| 943 |
+
gr.update(visible=False),
|
| 944 |
+
gr.update(visible=False),
|
| 945 |
+
self.get_stats_display()
|
| 946 |
+
)
|
| 947 |
+
|
| 948 |
+
def _no_approval_response(self, history):
|
| 949 |
+
"""Return response for no pending approval."""
|
| 950 |
+
history.append([None, "⚠️ No pending approval"])
|
| 951 |
+
return self._all_hidden_response(history)
|
| 952 |
+
|
| 953 |
+
def show_capacity_modify_dialog(self):
|
| 954 |
+
"""Show capacity parameter modification dialog."""
|
| 955 |
+
if not self.current_interrupt_data:
|
| 956 |
+
return (
|
| 957 |
+
gr.update(visible=True),
|
| 958 |
+
gr.update(visible=False),
|
| 959 |
+
gr.update(visible=False),
|
| 960 |
+
gr.update(visible=False),
|
| 961 |
+
2048, 256, 2048, "auto", 0.9, "France", "RTX 4090"
|
| 962 |
+
)
|
| 963 |
+
|
| 964 |
+
model_info = self.current_interrupt_data.get("model_info", {})
|
| 965 |
+
|
| 966 |
+
return (
|
| 967 |
+
gr.update(visible=False), # Hide capacity approval
|
| 968 |
+
gr.update(visible=True), # Show capacity param
|
| 969 |
+
gr.update(visible=False), # Hide tool approval
|
| 970 |
+
gr.update(visible=False), # Hide tool list
|
| 971 |
+
model_info.get("max_model_len", 2048),
|
| 972 |
+
model_info.get("max_num_seqs", 256),
|
| 973 |
+
model_info.get("max_num_batched_tokens", 2048),
|
| 974 |
+
model_info.get("kv_cache_dtype", "auto"),
|
| 975 |
+
model_info.get("gpu_memory_utilization", 0.9),
|
| 976 |
+
model_info.get("location", "France"),
|
| 977 |
+
model_info.get("GPU_type", "RTX 4090")
|
| 978 |
+
)
|
| 979 |
+
|
| 980 |
+
def cancel_capacity_modify(self):
|
| 981 |
+
"""Cancel capacity modification."""
|
| 982 |
+
return (
|
| 983 |
+
gr.update(visible=True), # Show capacity approval
|
| 984 |
+
gr.update(visible=False), # Hide capacity param
|
| 985 |
+
gr.update(visible=False),
|
| 986 |
+
gr.update(visible=False)
|
| 987 |
+
)
|
| 988 |
+
|
| 989 |
+
def clear_chat(self, user_id: str, session_id: str):
|
| 990 |
+
"""Clear chat history."""
|
| 991 |
+
self._clear_approval_state()
|
| 992 |
+
return (
|
| 993 |
+
[], # Empty history
|
| 994 |
+
"", # Clear input
|
| 995 |
+
gr.update(visible=False),
|
| 996 |
+
gr.update(visible=False),
|
| 997 |
+
gr.update(visible=False),
|
| 998 |
+
gr.update(visible=False),
|
| 999 |
+
self.get_stats_display()
|
| 1000 |
+
)
|
| 1001 |
+
|
| 1002 |
+
def new_session(self, user_id: str):
|
| 1003 |
+
"""Generate new session ID."""
|
| 1004 |
+
new_session_id = f"session_{datetime.now().strftime('%Y%m%d_%H%M%S')}"
|
| 1005 |
+
self._clear_approval_state()
|
| 1006 |
+
return new_session_id
|
| 1007 |
+
|
| 1008 |
+
|
| 1009 |
+
# Initialize interface
|
| 1010 |
+
agent_interface = ComputeAgentInterface()
|
| 1011 |
+
|
| 1012 |
+
|
| 1013 |
+
# Create Gradio theme matching HiveNet brand colors
|
| 1014 |
+
def create_theme():
|
| 1015 |
+
return gr.themes.Soft(
|
| 1016 |
+
primary_hue="orange",
|
| 1017 |
+
secondary_hue="stone",
|
| 1018 |
+
neutral_hue="slate",
|
| 1019 |
+
font=gr.themes.GoogleFont("Inter")
|
| 1020 |
+
).set(
|
| 1021 |
+
body_background_fill="#1a1a1a",
|
| 1022 |
+
body_background_fill_dark="#0d0d0d",
|
| 1023 |
+
button_primary_background_fill="#d97706",
|
| 1024 |
+
button_primary_background_fill_hover="#ea580c",
|
| 1025 |
+
button_primary_text_color="#ffffff",
|
| 1026 |
+
block_background_fill="#262626",
|
| 1027 |
+
block_border_color="#404040",
|
| 1028 |
+
input_background_fill="#1f1f1f",
|
| 1029 |
+
slider_color="#d97706",
|
| 1030 |
+
)
|
| 1031 |
+
|
| 1032 |
+
|
| 1033 |
+
# Create interface
|
| 1034 |
+
with gr.Blocks(
|
| 1035 |
+
title="ComputeAgent - Enhanced with Tool Approval",
|
| 1036 |
+
theme=create_theme(),
|
| 1037 |
+
css="""
|
| 1038 |
+
.gradio-container {
|
| 1039 |
+
max-width: 100% !important;
|
| 1040 |
+
}
|
| 1041 |
+
.header-box {
|
| 1042 |
+
background: linear-gradient(135deg, #d97706 0%, #ea580c 50%, #dc2626 100%);
|
| 1043 |
+
color: white;
|
| 1044 |
+
padding: 20px;
|
| 1045 |
+
border-radius: 10px;
|
| 1046 |
+
margin-bottom: 20px;
|
| 1047 |
+
position: relative;
|
| 1048 |
+
overflow: hidden;
|
| 1049 |
+
}
|
| 1050 |
+
.header-box::before {
|
| 1051 |
+
content: '';
|
| 1052 |
+
position: absolute;
|
| 1053 |
+
top: 0;
|
| 1054 |
+
left: 0;
|
| 1055 |
+
right: 0;
|
| 1056 |
+
bottom: 0;
|
| 1057 |
+
background-image: url("data:image/svg+xml,%3Csvg xmlns='http://www.w3.org/2000/svg' viewBox='0 0 600 600'%3E%3Cfilter id='noise'%3E%3CfeTurbulence type='fractalNoise' baseFrequency='0.9' numOctaves='3' /%3E%3C/filter%3E%3Crect width='100%25' height='100%25' filter='url(%23noise)' opacity='0.05' /%3E%3C/svg%3E");
|
| 1058 |
+
pointer-events: none;
|
| 1059 |
+
}
|
| 1060 |
+
.tool-box {
|
| 1061 |
+
background: rgba(41, 37, 36, 0.5);
|
| 1062 |
+
border: 2px solid #57534e;
|
| 1063 |
+
border-radius: 8px;
|
| 1064 |
+
padding: 15px;
|
| 1065 |
+
margin: 10px 0;
|
| 1066 |
+
}
|
| 1067 |
+
/* Make chatbot fill available height dynamically */
|
| 1068 |
+
.chatbot {
|
| 1069 |
+
height: calc(100vh - 750px) !important;
|
| 1070 |
+
max-height: calc(100vh - 750px) !important;
|
| 1071 |
+
}
|
| 1072 |
+
"""
|
| 1073 |
+
) as demo:
|
| 1074 |
+
|
| 1075 |
+
# Header
|
| 1076 |
+
hivenet_logo_html = f'<img src="data:image/jpeg;base64,{HIVENET_LOGO_BASE64}" alt="HiveNet Logo" style="height: 80px; width: auto; object-fit: contain;">' if HIVENET_LOGO_BASE64 else ''
|
| 1077 |
+
computeagent_logo_html = f'<img src="data:image/png;base64,{COMPUTEAGENT_LOGO_BASE64}" alt="ComputeAgent Logo" style="height: 60px; width: auto; object-fit: contain; margin-right: 15px;">' if COMPUTEAGENT_LOGO_BASE64 else ''
|
| 1078 |
+
|
| 1079 |
+
gr.HTML(f"""
|
| 1080 |
+
<div class="header-box" style="display: flex; justify-content: space-between; align-items: center;">
|
| 1081 |
+
<div style="display: flex; align-items: center;">
|
| 1082 |
+
{computeagent_logo_html}
|
| 1083 |
+
<div>
|
| 1084 |
+
<h1 style="margin: 0; font-size: 2.5em;">ComputeAgent</h1>
|
| 1085 |
+
<p style="margin: 10px 0 0 0; opacity: 0.9;">
|
| 1086 |
+
Hivenet AI-Powered Deployment using MCP of Compute by Hivenet
|
| 1087 |
+
</p>
|
| 1088 |
+
</div>
|
| 1089 |
+
</div>
|
| 1090 |
+
<div>
|
| 1091 |
+
{hivenet_logo_html}
|
| 1092 |
+
</div>
|
| 1093 |
+
</div>
|
| 1094 |
+
""")
|
| 1095 |
+
|
| 1096 |
+
with gr.Row():
|
| 1097 |
+
with gr.Column(scale=11):
|
| 1098 |
+
# Chat interface
|
| 1099 |
+
chatbot = gr.Chatbot(
|
| 1100 |
+
label="Agent Conversation",
|
| 1101 |
+
height=900,
|
| 1102 |
+
show_copy_button=True,
|
| 1103 |
+
elem_classes=["chatbot"]
|
| 1104 |
+
)
|
| 1105 |
+
|
| 1106 |
+
with gr.Row():
|
| 1107 |
+
msg = gr.Textbox(
|
| 1108 |
+
placeholder="Deploy meta-llama/Llama-3.1-70B or ask: What are the latest AI developments?",
|
| 1109 |
+
scale=5,
|
| 1110 |
+
show_label=False
|
| 1111 |
+
)
|
| 1112 |
+
send_btn = gr.Button("🚀 Send", variant="primary", scale=1)
|
| 1113 |
+
|
| 1114 |
+
# ================================================================
|
| 1115 |
+
# CAPACITY APPROVAL PANEL
|
| 1116 |
+
# ================================================================
|
| 1117 |
+
with gr.Row(visible=False) as capacity_approval_panel:
|
| 1118 |
+
capacity_approve_btn = gr.Button("✅ Approve", variant="primary", scale=1)
|
| 1119 |
+
capacity_modify_btn = gr.Button("🔧 Modify", variant="secondary", scale=1)
|
| 1120 |
+
capacity_reject_btn = gr.Button("❌ Reject", variant="stop", scale=1)
|
| 1121 |
+
|
| 1122 |
+
# Capacity parameter modification panel
|
| 1123 |
+
with gr.Column(visible=False) as capacity_param_panel:
|
| 1124 |
+
gr.Markdown("## 🔧 Capacity Parameter Optimization")
|
| 1125 |
+
|
| 1126 |
+
with gr.Row():
|
| 1127 |
+
with gr.Column():
|
| 1128 |
+
max_model_len = gr.Number(
|
| 1129 |
+
label="Context Length",
|
| 1130 |
+
value=2048,
|
| 1131 |
+
minimum=1
|
| 1132 |
+
)
|
| 1133 |
+
max_num_seqs = gr.Number(
|
| 1134 |
+
label="Max Sequences",
|
| 1135 |
+
value=256,
|
| 1136 |
+
minimum=1
|
| 1137 |
+
)
|
| 1138 |
+
|
| 1139 |
+
with gr.Column():
|
| 1140 |
+
max_batched_tokens = gr.Number(
|
| 1141 |
+
label="Batch Size",
|
| 1142 |
+
value=2048,
|
| 1143 |
+
minimum=1
|
| 1144 |
+
)
|
| 1145 |
+
kv_cache_dtype = gr.Dropdown(
|
| 1146 |
+
choices=["auto", "float32", "float16", "bfloat16", "fp8"],
|
| 1147 |
+
value="auto",
|
| 1148 |
+
label="KV Cache Type"
|
| 1149 |
+
)
|
| 1150 |
+
|
| 1151 |
+
with gr.Column():
|
| 1152 |
+
gpu_util = gr.Slider(
|
| 1153 |
+
minimum=0.1,
|
| 1154 |
+
maximum=1.0,
|
| 1155 |
+
value=0.9,
|
| 1156 |
+
step=0.05,
|
| 1157 |
+
label="GPU Utilization"
|
| 1158 |
+
)
|
| 1159 |
+
location = gr.Dropdown(
|
| 1160 |
+
choices=list(LOCATION_GPU_MAP.keys()),
|
| 1161 |
+
value="France",
|
| 1162 |
+
label="Location"
|
| 1163 |
+
)
|
| 1164 |
+
gpu_type = gr.Dropdown(
|
| 1165 |
+
choices=LOCATION_GPU_MAP["France"],
|
| 1166 |
+
value="RTX 4090",
|
| 1167 |
+
label="GPU Type"
|
| 1168 |
+
)
|
| 1169 |
+
|
| 1170 |
+
with gr.Row():
|
| 1171 |
+
capacity_apply_btn = gr.Button("🔄 Re-estimate", variant="primary", scale=2)
|
| 1172 |
+
capacity_cancel_btn = gr.Button("↩️ Back", variant="secondary", scale=1)
|
| 1173 |
+
|
| 1174 |
+
# ================================================================
|
| 1175 |
+
# TOOL APPROVAL PANEL
|
| 1176 |
+
# ================================================================
|
| 1177 |
+
with gr.Row(visible=False) as tool_approval_panel:
|
| 1178 |
+
tool_approve_all_btn = gr.Button("✅ Approve All", variant="primary", scale=1)
|
| 1179 |
+
tool_reject_all_btn = gr.Button("❌ Reject All", variant="stop", scale=1)
|
| 1180 |
+
|
| 1181 |
+
with gr.Column(visible=False) as tool_list_panel:
|
| 1182 |
+
gr.Markdown("### 🔧 Tool Actions")
|
| 1183 |
+
|
| 1184 |
+
with gr.Tab("Selective Approval"):
|
| 1185 |
+
tool_indices_input = gr.Textbox(
|
| 1186 |
+
label="Tool Indices to Approve (comma-separated)",
|
| 1187 |
+
placeholder="1,2,3",
|
| 1188 |
+
info="Enter indices of tools to approve (e.g., '1,3' to approve Tool 1 and Tool 3)"
|
| 1189 |
+
)
|
| 1190 |
+
tool_approve_selected_btn = gr.Button("✅ Approve Selected", variant="primary")
|
| 1191 |
+
|
| 1192 |
+
with gr.Tab("Modify Arguments"):
|
| 1193 |
+
tool_index_input = gr.Number(
|
| 1194 |
+
label="Tool Index",
|
| 1195 |
+
value=1,
|
| 1196 |
+
minimum=1,
|
| 1197 |
+
precision=0,
|
| 1198 |
+
info="Enter tool number (e.g., 1 for Tool 1)"
|
| 1199 |
+
)
|
| 1200 |
+
tool_args_input = gr.TextArea(
|
| 1201 |
+
label="New Arguments (JSON)",
|
| 1202 |
+
placeholder='{"query": "modified search query"}',
|
| 1203 |
+
lines=5
|
| 1204 |
+
)
|
| 1205 |
+
tool_modify_btn = gr.Button("🔧 Modify & Approve", variant="secondary")
|
| 1206 |
+
|
| 1207 |
+
with gr.Tab("Re-Reasoning"):
|
| 1208 |
+
feedback_input = gr.TextArea(
|
| 1209 |
+
label="Feedback for Agent",
|
| 1210 |
+
placeholder="Please search for academic papers instead of news articles...",
|
| 1211 |
+
lines=4
|
| 1212 |
+
)
|
| 1213 |
+
re_reasoning_btn = gr.Button("🔄 Request Re-Reasoning", variant="secondary")
|
| 1214 |
+
|
| 1215 |
+
# Sidebar
|
| 1216 |
+
with gr.Column(scale=1):
|
| 1217 |
+
gr.Markdown("## Control Panel")
|
| 1218 |
+
|
| 1219 |
+
with gr.Group():
|
| 1220 |
+
gr.Markdown("### User Session")
|
| 1221 |
+
user_id = gr.Textbox(
|
| 1222 |
+
label="User ID",
|
| 1223 |
+
value="demo_user"
|
| 1224 |
+
)
|
| 1225 |
+
session_id = gr.Textbox(
|
| 1226 |
+
label="Session ID",
|
| 1227 |
+
value=f"session_{datetime.now().strftime('%m%d_%H%M')}"
|
| 1228 |
+
)
|
| 1229 |
+
|
| 1230 |
+
with gr.Group():
|
| 1231 |
+
stats_display = gr.Markdown("### Statistics\nNo requests yet")
|
| 1232 |
+
|
| 1233 |
+
with gr.Group():
|
| 1234 |
+
gr.Markdown("### Management")
|
| 1235 |
+
clear_btn = gr.Button("Clear History", variant="secondary")
|
| 1236 |
+
new_session_btn = gr.Button("New Session", variant="secondary")
|
| 1237 |
+
|
| 1238 |
+
gr.Markdown("""
|
| 1239 |
+
## Examples
|
| 1240 |
+
|
| 1241 |
+
**Model Deployment:**
|
| 1242 |
+
- Deploy meta-llama/Llama-3.1-8B
|
| 1243 |
+
- Deploy openai/gpt-oss-20b
|
| 1244 |
+
|
| 1245 |
+
**Tool Usage:**
|
| 1246 |
+
- Search for latest AI developments
|
| 1247 |
+
- Calculate 25 * 34 + 128
|
| 1248 |
+
- What's the weather in Paris?
|
| 1249 |
+
""")
|
| 1250 |
+
|
| 1251 |
+
# Update GPU options when location changes
|
| 1252 |
+
location.change(
|
| 1253 |
+
fn=agent_interface.update_gpu_options,
|
| 1254 |
+
inputs=[location],
|
| 1255 |
+
outputs=[gpu_type]
|
| 1256 |
+
)
|
| 1257 |
+
|
| 1258 |
+
# ========================================================================
|
| 1259 |
+
# EVENT HANDLERS
|
| 1260 |
+
# ========================================================================
|
| 1261 |
+
|
| 1262 |
+
# Query submission
|
| 1263 |
+
msg.submit(
|
| 1264 |
+
agent_interface.process_query,
|
| 1265 |
+
inputs=[msg, chatbot, user_id, session_id],
|
| 1266 |
+
outputs=[chatbot, msg, capacity_approval_panel, capacity_param_panel,
|
| 1267 |
+
tool_approval_panel, tool_list_panel, stats_display]
|
| 1268 |
+
)
|
| 1269 |
+
|
| 1270 |
+
send_btn.click(
|
| 1271 |
+
agent_interface.process_query,
|
| 1272 |
+
inputs=[msg, chatbot, user_id, session_id],
|
| 1273 |
+
outputs=[chatbot, msg, capacity_approval_panel, capacity_param_panel,
|
| 1274 |
+
tool_approval_panel, tool_list_panel, stats_display]
|
| 1275 |
+
)
|
| 1276 |
+
|
| 1277 |
+
# Capacity approval handlers
|
| 1278 |
+
capacity_approve_btn.click(
|
| 1279 |
+
agent_interface.approve_capacity,
|
| 1280 |
+
inputs=[chatbot, user_id, session_id],
|
| 1281 |
+
outputs=[chatbot, capacity_approval_panel, capacity_param_panel,
|
| 1282 |
+
tool_approval_panel, tool_list_panel, stats_display]
|
| 1283 |
+
)
|
| 1284 |
+
|
| 1285 |
+
capacity_reject_btn.click(
|
| 1286 |
+
agent_interface.reject_capacity,
|
| 1287 |
+
inputs=[chatbot, user_id, session_id],
|
| 1288 |
+
outputs=[chatbot, capacity_approval_panel, capacity_param_panel,
|
| 1289 |
+
tool_approval_panel, tool_list_panel, stats_display]
|
| 1290 |
+
)
|
| 1291 |
+
|
| 1292 |
+
capacity_modify_btn.click(
|
| 1293 |
+
agent_interface.show_capacity_modify_dialog,
|
| 1294 |
+
outputs=[capacity_approval_panel, capacity_param_panel, tool_approval_panel,
|
| 1295 |
+
tool_list_panel, max_model_len, max_num_seqs, max_batched_tokens,
|
| 1296 |
+
kv_cache_dtype, gpu_util, location, gpu_type]
|
| 1297 |
+
)
|
| 1298 |
+
|
| 1299 |
+
capacity_cancel_btn.click(
|
| 1300 |
+
agent_interface.cancel_capacity_modify,
|
| 1301 |
+
outputs=[capacity_approval_panel, capacity_param_panel,
|
| 1302 |
+
tool_approval_panel, tool_list_panel]
|
| 1303 |
+
)
|
| 1304 |
+
|
| 1305 |
+
capacity_apply_btn.click(
|
| 1306 |
+
agent_interface.apply_capacity_modifications,
|
| 1307 |
+
inputs=[chatbot, user_id, session_id, max_model_len, max_num_seqs,
|
| 1308 |
+
max_batched_tokens, kv_cache_dtype, gpu_util, location, gpu_type],
|
| 1309 |
+
outputs=[chatbot, capacity_approval_panel, capacity_param_panel,
|
| 1310 |
+
tool_approval_panel, tool_list_panel, stats_display]
|
| 1311 |
+
)
|
| 1312 |
+
|
| 1313 |
+
# Tool approval handlers
|
| 1314 |
+
tool_approve_all_btn.click(
|
| 1315 |
+
agent_interface.approve_all_tools,
|
| 1316 |
+
inputs=[chatbot, user_id, session_id],
|
| 1317 |
+
outputs=[chatbot, capacity_approval_panel, capacity_param_panel,
|
| 1318 |
+
tool_approval_panel, tool_list_panel, stats_display]
|
| 1319 |
+
)
|
| 1320 |
+
|
| 1321 |
+
tool_reject_all_btn.click(
|
| 1322 |
+
agent_interface.reject_all_tools,
|
| 1323 |
+
inputs=[chatbot, user_id, session_id],
|
| 1324 |
+
outputs=[chatbot, capacity_approval_panel, capacity_param_panel,
|
| 1325 |
+
tool_approval_panel, tool_list_panel, stats_display]
|
| 1326 |
+
)
|
| 1327 |
+
|
| 1328 |
+
tool_approve_selected_btn.click(
|
| 1329 |
+
agent_interface.approve_selected_tools,
|
| 1330 |
+
inputs=[chatbot, user_id, session_id, tool_indices_input],
|
| 1331 |
+
outputs=[chatbot, capacity_approval_panel, capacity_param_panel,
|
| 1332 |
+
tool_approval_panel, tool_list_panel, stats_display]
|
| 1333 |
+
)
|
| 1334 |
+
|
| 1335 |
+
tool_modify_btn.click(
|
| 1336 |
+
agent_interface.modify_tool_args,
|
| 1337 |
+
inputs=[chatbot, user_id, session_id, tool_index_input, tool_args_input],
|
| 1338 |
+
outputs=[chatbot, capacity_approval_panel, capacity_param_panel,
|
| 1339 |
+
tool_approval_panel, tool_list_panel, stats_display]
|
| 1340 |
+
)
|
| 1341 |
+
|
| 1342 |
+
re_reasoning_btn.click(
|
| 1343 |
+
agent_interface.request_re_reasoning,
|
| 1344 |
+
inputs=[chatbot, user_id, session_id, feedback_input],
|
| 1345 |
+
outputs=[chatbot, capacity_approval_panel, capacity_param_panel,
|
| 1346 |
+
tool_approval_panel, tool_list_panel, stats_display]
|
| 1347 |
+
)
|
| 1348 |
+
|
| 1349 |
+
# Management handlers
|
| 1350 |
+
clear_btn.click(
|
| 1351 |
+
agent_interface.clear_chat,
|
| 1352 |
+
inputs=[user_id, session_id],
|
| 1353 |
+
outputs=[chatbot, msg, capacity_approval_panel, capacity_param_panel,
|
| 1354 |
+
tool_approval_panel, tool_list_panel, stats_display]
|
| 1355 |
+
)
|
| 1356 |
+
|
| 1357 |
+
new_session_btn.click(
|
| 1358 |
+
agent_interface.new_session,
|
| 1359 |
+
inputs=[user_id],
|
| 1360 |
+
outputs=[session_id]
|
| 1361 |
+
)
|
| 1362 |
+
|
| 1363 |
+
|
| 1364 |
+
if __name__ == "__main__":
|
| 1365 |
+
logger.info("🚀 Starting Enhanced ComputeAgent Gradio Interface")
|
| 1366 |
+
logger.info(f"📡 Connecting to FastAPI at: {API_BASE_URL}")
|
| 1367 |
+
logger.info("✨ Features: Capacity Approval + Tool Approval")
|
| 1368 |
+
logger.info("🌐 Interface will be available at: http://localhost:7860")
|
| 1369 |
+
|
| 1370 |
+
demo.launch(
|
| 1371 |
+
server_name="0.0.0.0",
|
| 1372 |
+
server_port=7860,
|
| 1373 |
+
share=False
|
| 1374 |
+
)
|
README.md
CHANGED
|
@@ -1,8 +1,8 @@
|
|
| 1 |
---
|
| 2 |
-
title: Hivenet
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
-
colorTo:
|
| 6 |
sdk: docker
|
| 7 |
pinned: false
|
| 8 |
license: apache-2.0
|
|
@@ -10,3 +10,11 @@ short_description: AI-Powered Deployment using MCP of Compute by Hivenet
|
|
| 10 |
---
|
| 11 |
|
| 12 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: Hivenet
|
| 3 |
+
emoji: 🔥
|
| 4 |
+
colorFrom: blue
|
| 5 |
+
colorTo: indigo
|
| 6 |
sdk: docker
|
| 7 |
pinned: false
|
| 8 |
license: apache-2.0
|
|
|
|
| 10 |
---
|
| 11 |
|
| 12 |
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
| 13 |
+
|
| 14 |
+
## 👥 Team
|
| 15 |
+
|
| 16 |
+
**Team Name:** Hivenet AI Team
|
| 17 |
+
|
| 18 |
+
**Team Members:**
|
| 19 |
+
- **Igor Carrara** - [@carraraig](https://huggingface.co/carraraig) - AI Scientist
|
| 20 |
+
- **Mamoutou Diarra** - [@mdiarra](https://huggingface.co/mdiarra) - AI Scientist
|
constant.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""Constant Module"""
|
| 2 |
+
import os
|
| 3 |
+
from enum import StrEnum
|
| 4 |
+
|
| 5 |
+
from dotenv import load_dotenv
|
| 6 |
+
|
| 7 |
+
load_dotenv()
|
| 8 |
+
|
| 9 |
+
class Constants(StrEnum):
|
| 10 |
+
"""Constants used in application."""
|
| 11 |
+
|
| 12 |
+
# ============================================================================
|
| 13 |
+
# COMPUTE CONFIGURATION
|
| 14 |
+
# ============================================================================
|
| 15 |
+
|
| 16 |
+
HIVE_COMPUTE_BASE_API_URL = os.environ.get("HIVE_COMPUTE_BASE_API_URL", "https://api.hivecompute.ai")
|
| 17 |
+
HIVE_COMPUTE_DEFAULT_API_TOKEN = os.environ.get("HIVE_COMPUTE_DEFAULT_API_TOKEN", "")
|
| 18 |
+
|
| 19 |
+
# ============================================================================
|
| 20 |
+
# MODEL CONFIGURATION
|
| 21 |
+
# ============================================================================
|
| 22 |
+
|
| 23 |
+
# Model Router configuration for AI model management
|
| 24 |
+
MODEL_ROUTER_TOKEN = os.getenv("MODEL_ROUTER_TOKEN", "your-model-router-token")
|
| 25 |
+
MODEL_ROUTER_HOST = os.getenv("MODEL_ROUTER_HOST", "localhost")
|
| 26 |
+
MODEL_ROUTER_PORT = os.getenv("MODEL_ROUTER_PORT", "8080")
|
| 27 |
+
|
| 28 |
+
# Default model configurations
|
| 29 |
+
DEFAULT_LLM_NAME = os.getenv("DEFAULT_LLM_NAME", "openai/gpt-oss-20b")
|
| 30 |
+
DEFAULT_LLM_FC = os.getenv("DEFAULT_LLM_FC", "Qwen/Qwen3-14B-FP8")
|
| 31 |
+
HF_TOKEN = os.getenv("HF_TOKEN", "your-huggingface-token")
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
# ============================================================================
|
| 35 |
+
# ENVIRONMENT AND PROCESSING CONFIGURATION
|
| 36 |
+
# ============================================================================
|
| 37 |
+
|
| 38 |
+
# Environment setting (production vs development)
|
| 39 |
+
ENV = os.environ.get("PRODUCTION", "False").lower()
|
| 40 |
+
PRODUCTION = "" if ENV == "false" else "true"
|
| 41 |
+
|
| 42 |
+
# Human approval setting for tool execution
|
| 43 |
+
HUMAN_APPROVAL = os.environ.get("HUMAN_APPROVAL", "True").lower()
|
| 44 |
+
HUMAN_APPROVAL_CAPACITY = os.environ.get("HUMAN_APPROVAL_CAPACITY", "True").lower()
|
| 45 |
+
|
| 46 |
+
# ============================================================================
|
| 47 |
+
# AI SYSTEM PROMPTS AND BEHAVIOR CONFIGURATION
|
| 48 |
+
# ============================================================================
|
| 49 |
+
|
| 50 |
+
# General System Prompt - Applied to all AI interactions
|
| 51 |
+
GENERAL_SYSTEM_PROMPT = r"""
|
| 52 |
+
<behavior_instructions>
|
| 53 |
+
ComputeAgent is Hive’s AI assistant for the Hivenet.com ecosystem.
|
| 54 |
+
It supports users—called *Hivers*—by providing accurate, professional, and context-aware answers across factual and creative topics that align with Hive’s ethical and community standards.
|
| 55 |
+
|
| 56 |
+
ComputeAgent always:
|
| 57 |
+
- Remains **professional, accurate, and relevant**.
|
| 58 |
+
- Uses **Hive data and documentation** when available.
|
| 59 |
+
- Prioritizes **user intent**, clarifying ambiguity when needed.
|
| 60 |
+
- Balances **conciseness and completeness**.
|
| 61 |
+
- **Cites sources** when providing information from specific documents or external resources.
|
| 62 |
+
</behavior_instructions>
|
| 63 |
+
|
| 64 |
+
<priority_rules>
|
| 65 |
+
ComputeAgent follows all behavior instructions in this prompt.
|
| 66 |
+
When multiple instructions may conflict:
|
| 67 |
+
1. **Safety and compliance** come first.
|
| 68 |
+
2. **Accuracy and source citation** come second.
|
| 69 |
+
3. **User tone and formatting** come third.
|
| 70 |
+
If factual info comes from a verifiable source, ComputeAgent MUST cite it, even if the user doesn’t ask.
|
| 71 |
+
</priority_rules>
|
| 72 |
+
|
| 73 |
+
<source_citation>
|
| 74 |
+
ComputeAgent must include **inline citations** for all statements derived from the provided knowledge pieces.
|
| 75 |
+
|
| 76 |
+
### Citation Rules
|
| 77 |
+
- Use the **`id` field** from the knowledge pieces as your citation.
|
| 78 |
+
- Format citations as `[citationId]` placed **between sentences or phrases** that use that knowledge.
|
| 79 |
+
- Citations should **never appear on a separate line** or as a sub-bullet in lists.
|
| 80 |
+
- Always cite **every piece of knowledge you use**; skipping a source is considered incorrect.
|
| 81 |
+
- Never invent or alter citation IDs.
|
| 82 |
+
- Do not include URLs, parentheses, or prefixes like “Source:”.
|
| 83 |
+
|
| 84 |
+
### Examples
|
| 85 |
+
✅ Correct:
|
| 86 |
+
- “The capital of Chile is Santiago de Chile[1], and the population is 7 million people[3].”
|
| 87 |
+
- “Caco loves oranges more than apples[1], and his full name is Joaquín Ossandón Stanke[2].”
|
| 88 |
+
- “Caco's nickname, cacoos, comes from his initials[3].”
|
| 89 |
+
|
| 90 |
+
❌ Incorrect:
|
| 91 |
+
- “The capital of Chile is Santiago de Chile.” (missing citation)
|
| 92 |
+
- “Caco loves oranges[1] and apples.” (forgot to cite full statement)
|
| 93 |
+
- “Caco's full name[2](https://...)” (URL included)
|
| 94 |
+
- Citation on a new line or nested bullet:
|
| 95 |
+
- Users manage passwords.
|
| 96 |
+
- [12]
|
| 97 |
+
|
| 98 |
+
### Style Rules
|
| 99 |
+
- Integrate citations naturally inline; they should feel like part of the sentence.
|
| 100 |
+
- Multiple citations in the same sentence can be separated by commas: `[1], [2]`.
|
| 101 |
+
- Only cite knowledge actually used in the answer.
|
| 102 |
+
- Ensure readability: citations should feel like part of the sentence.
|
| 103 |
+
</source_citation>
|
| 104 |
+
|
| 105 |
+
<general_hive_info>
|
| 106 |
+
Created by Hive for the Hivenet community.
|
| 107 |
+
Current date: {{currentDateTime}}.
|
| 108 |
+
|
| 109 |
+
HiveGPT can discuss Hive, Hivenet.com, and Hive’s products or community, but lacks access to non-public business details.
|
| 110 |
+
For pricing, limits, or account issues, refer users to [https://hivenet.com](https://hivenet.com).
|
| 111 |
+
|
| 112 |
+
HiveGPT can also help users craft better prompts, examples, or task formats.
|
| 113 |
+
See Hive’s documentation portal for more guidance.
|
| 114 |
+
</general_hive_info>
|
| 115 |
+
|
| 116 |
+
<refusal_handling>
|
| 117 |
+
HiveGPT must refuse requests that are:
|
| 118 |
+
- Harmful, illegal, or unethical.
|
| 119 |
+
- Discriminatory, violent, or harassing.
|
| 120 |
+
- Related to hacking, exploitation, or malicious code.
|
| 121 |
+
- About private/confidential data without consent.
|
| 122 |
+
- Fictional or persuasive content attributed to real people.
|
| 123 |
+
|
| 124 |
+
It may discuss educational or technical topics safely, focusing on ethical concepts.
|
| 125 |
+
If a request seems unsafe or unclear, HiveGPT politely declines and may redirect to a safe alternative.
|
| 126 |
+
Always respond respectfully, even to frustration or hostility.
|
| 127 |
+
</refusal_handling>
|
| 128 |
+
|
| 129 |
+
<tone>
|
| 130 |
+
HiveGPT maintains a **professional, clear, and approachable** tone—warm for casual chats but never overly informal.
|
| 131 |
+
|
| 132 |
+
Writing guidelines:
|
| 133 |
+
- Use **paragraphs** over lists unless structure improves clarity.
|
| 134 |
+
- Keep **formatting minimal and clean**.
|
| 135 |
+
- Be **concise** for simple questions, **thorough** for complex ones.
|
| 136 |
+
- Use examples or analogies when useful.
|
| 137 |
+
- No emojis unless the user does first.
|
| 138 |
+
- Mirror the user’s tone within professional limits.
|
| 139 |
+
- Avoid emotes, roleplay asterisks, and unnecessary profanity (respond calmly if user uses it).
|
| 140 |
+
</tone>
|
| 141 |
+
|
| 142 |
+
<response_quality_standards>
|
| 143 |
+
HiveGPT produces **expert, long-form answers** that are:
|
| 144 |
+
- **Comprehensive** – logically structured and detailed.
|
| 145 |
+
- **Professional** – authoritative and precise.
|
| 146 |
+
- **Engaging** – conversational yet clear.
|
| 147 |
+
- **Self-contained** – understandable without extra context.
|
| 148 |
+
- **Natural** – integrate context seamlessly (avoid meta phrases like “Based on the provided context”).
|
| 149 |
+
|
| 150 |
+
Every fact-based statement must include citations where relevant, especially if the content can be verified externally.
|
| 151 |
+
|
| 152 |
+
Balance clarity, depth, and readability in every response.
|
| 153 |
+
</response_quality_standards>
|
| 154 |
+
|
| 155 |
+
<user_wellbeing>
|
| 156 |
+
HiveGPT promotes **safe, balanced, and supportive** communication.
|
| 157 |
+
Avoid encouraging self-harm, addiction, or misinformation.
|
| 158 |
+
In sensitive topics (e.g., health, psychology), give factual, responsible info and suggest consulting professionals.
|
| 159 |
+
If emotional distress is detected, respond with compassion and encourage seeking real support.
|
| 160 |
+
Never reinforce harmful or delusional beliefs; guide gently toward reality.
|
| 161 |
+
</user_wellbeing>
|
| 162 |
+
|
| 163 |
+
<formatting_rules>
|
| 164 |
+
Use markdown-style formatting for clarity and consistency.
|
| 165 |
+
|
| 166 |
+
### Document Structure
|
| 167 |
+
- **Title (`##`)**: Main topic.
|
| 168 |
+
Example: `## How to Reset Your Hive Password`
|
| 169 |
+
- **Subtitle (`###`)** (optional): Brief intro.
|
| 170 |
+
- **Horizontal Rule (`---`)**: Separate major sections.
|
| 171 |
+
|
| 172 |
+
### Text Formatting
|
| 173 |
+
- **Bold (`**bold**`)** – Key terms/actions.
|
| 174 |
+
- *Italic (`*italic*`)* – Light emphasis or technical terms.
|
| 175 |
+
- [Links](URL) – Cite resources.
|
| 176 |
+
|
| 177 |
+
### Lists & Steps
|
| 178 |
+
- **Bullets (`-`)** – For unordered points.
|
| 179 |
+
- **Numbers (`1.`)** – For steps or sequences.
|
| 180 |
+
|
| 181 |
+
### Code
|
| 182 |
+
Use fenced blocks for syntax:
|
| 183 |
+
```python
|
| 184 |
+
def hello():
|
| 185 |
+
print("Hello, Hive!")
|
| 186 |
+
|
| 187 |
+
### Advanced Formatting
|
| 188 |
+
- Inline code (\code`) – Short technical refs.
|
| 189 |
+
- Task lists (- [ ]) – To-dos or checklists.
|
| 190 |
+
- Blockquotes (>) – Notes or tips.
|
| 191 |
+
- Headings (#–######) – Nested structure.
|
| 192 |
+
</formatting_rules>
|
| 193 |
+
"""
|
| 194 |
+
|
| 195 |
+
|
logging_setup.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
import asyncio
|
| 3 |
+
import logging
|
| 4 |
+
import os
|
| 5 |
+
import sys
|
| 6 |
+
|
| 7 |
+
import coloredlogs
|
| 8 |
+
from loguru import logger
|
| 9 |
+
|
| 10 |
+
if os.name == "nt":
|
| 11 |
+
asyncio.set_event_loop_policy(asyncio.WindowsSelectorEventLoopPolicy())
|
| 12 |
+
|
| 13 |
+
logger.remove()
|
| 14 |
+
logger.add(sys.stderr, level=logging.ERROR)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class InterceptHandler(logging.Handler):
|
| 18 |
+
"""Intercept standard logging messages toward your Loguru sinks.
|
| 19 |
+
Code was taken from https://github.com/Delgan/loguru#entirely-compatible-with-standard-logging
|
| 20 |
+
"""
|
| 21 |
+
|
| 22 |
+
loggers = {}
|
| 23 |
+
|
| 24 |
+
def emit(self, record):
|
| 25 |
+
# Get corresponding Loguru level if it exists
|
| 26 |
+
"""
|
| 27 |
+
Intercept a standard logging message and log it through Loguru.
|
| 28 |
+
|
| 29 |
+
:param record: standard logging record
|
| 30 |
+
:type record: logging.LogRecord
|
| 31 |
+
"""
|
| 32 |
+
try:
|
| 33 |
+
level = logger.level(record.levelname).name
|
| 34 |
+
except ValueError:
|
| 35 |
+
level = record.levelno
|
| 36 |
+
|
| 37 |
+
# Find caller from where originated the logged message
|
| 38 |
+
frame, depth = sys._getframe(2), 2
|
| 39 |
+
while frame.f_code.co_filename == logging.__file__:
|
| 40 |
+
frame = frame.f_back
|
| 41 |
+
depth += 1
|
| 42 |
+
|
| 43 |
+
if record.name not in self.loggers:
|
| 44 |
+
self.loggers[record.name] = logger.bind(name=record.name)
|
| 45 |
+
self.loggers[record.name].opt(depth=depth, exception=record.exc_info).log(level, record.getMessage())
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
coloredlogs.DEFAULT_LEVEL_STYLES = {
|
| 49 |
+
**coloredlogs.DEFAULT_LEVEL_STYLES,
|
| 50 |
+
"critical": {"background": "red"},
|
| 51 |
+
"debug": coloredlogs.DEFAULT_LEVEL_STYLES["info"],
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
log_level = logging.DEBUG if os.environ.get("PRODUCTION", False) == "DEBUG" else logging.INFO
|
| 55 |
+
if isinstance(log_level, str):
|
| 56 |
+
log_level = logging.INFO
|
| 57 |
+
|
| 58 |
+
format_string = "%(asctime)s | %(name)s | %(levelname)s | %(message)s"
|
| 59 |
+
|
| 60 |
+
coloredlogs.install(stream=sys.stdout, level=log_level, fmt=format_string)
|
| 61 |
+
|
| 62 |
+
logging.basicConfig(level=log_level, format=format_string)
|
| 63 |
+
logging.getLogger().addHandler(InterceptHandler(level=log_level))
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
logging.getLogger("github.Requester").setLevel(logging.WARNING)
|
| 67 |
+
logging.getLogger("multipart").setLevel(logging.WARNING)
|
| 68 |
+
logging.getLogger("openai").setLevel(logging.INFO)
|
| 69 |
+
logging.getLogger("PIL").setLevel(logging.WARNING)
|
| 70 |
+
logging.getLogger("urllib3").setLevel(logging.WARNING)
|
| 71 |
+
logging.getLogger("websockets").setLevel(logging.WARNING)
|
| 72 |
+
logging.getLogger("werkzeug").setLevel(logging.WARNING)
|
| 73 |
+
logging.getLogger('pdfminer').setLevel(logging.ERROR)
|
requirements.txt
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# MCP
|
| 2 |
+
fastapi
|
| 3 |
+
uvicorn[standard]
|
| 4 |
+
fastmcp>=2.12.3
|
| 5 |
+
httpx
|
| 6 |
+
pydantic
|
| 7 |
+
|
| 8 |
+
# Compute Agent
|
| 9 |
+
coloredlogs>=15.0.1
|
| 10 |
+
dotenv>=0.9.9
|
| 11 |
+
gradio==5.49.1
|
| 12 |
+
gradio-client==1.13.3
|
| 13 |
+
langchain>=1.0.7
|
| 14 |
+
langchain-core>=1.0.5
|
| 15 |
+
langchain-mcp-adapters>=0.1.13
|
| 16 |
+
langchain-openai>=1.0.3
|
| 17 |
+
langgraph>=1.0.3
|
| 18 |
+
python-dotenv>=1.2.1
|
| 19 |
+
requests>=2.32.5
|
| 20 |
+
transformers>=4.57.1
|
| 21 |
+
aiohttp
|
run.sh
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# With stdio transport, MCP server is spawned by the MCP client automatically
|
| 3 |
+
# No need to start it separately
|
| 4 |
+
|
| 5 |
+
AGENT_DIR="/home/hivenet/ComputeAgent"
|
| 6 |
+
AGENT_PID="/home/hivenet/agent.pid"
|
| 7 |
+
CURR_DIR=$(pwd)
|
| 8 |
+
GRADIO_DIR=${CURR_DIR}
|
| 9 |
+
|
| 10 |
+
# Start Compute Agent (MCP client will spawn MCP server via stdio)
|
| 11 |
+
cd ${AGENT_DIR}
|
| 12 |
+
python main.py & echo $! > ${AGENT_PID}
|
| 13 |
+
sleep 5
|
| 14 |
+
|
| 15 |
+
# Start Gradio Web Server
|
| 16 |
+
cd ${GRADIO_DIR}
|
| 17 |
+
python Gradio_interface.py
|
| 18 |
+
|
| 19 |
+
# Cleanup on exit
|
| 20 |
+
pkill -F ${AGENT_PID}
|
| 21 |
+
rm ${AGENT_PID}
|