Spaces:
Build error

Build error
Commit
·
77c8482
1
Parent(s):
6692ae2
Upload 17 files
Browse files- .gitattributes +4 -0
- app.py +209 -0
- assets/attn_plot.png +3 -0
- assets/examples.png +3 -0
- assets/model_transformer.png +0 -0
- checkpoints/RATCHET.tf/keras_metadata.pb +3 -0
- checkpoints/RATCHET.tf/saved_model.pb +3 -0
- checkpoints/RATCHET.tf/variables/variables.data-00000-of-00001 +3 -0
- checkpoints/RATCHET.tf/variables/variables.index +0 -0
- checkpoints/cxr_validator_model.tf/fingerprint.pb +3 -0
- checkpoints/cxr_validator_model.tf/keras_metadata.pb +3 -0
- checkpoints/cxr_validator_model.tf/saved_model.pb +3 -0
- checkpoints/cxr_validator_model.tf/variables/variables.data-00000-of-00001 +3 -0
- checkpoints/cxr_validator_model.tf/variables/variables.index +0 -0
- mimic/mimic-merges.txt +0 -0
- mimic/mimic-vocab.json +0 -0
- requirements.txt +6 -0
- transformer.py +263 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
assets/attn_plot.png filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/examples.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
checkpoints/cxr_validator_model.tf/variables/variables.data-00000-of-00001 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
checkpoints/RATCHET.tf/variables/variables.data-00000-of-00001 filter=lfs diff=lfs merge=lfs -text
|
app.py
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import tqdm
|
| 2 |
+
import datetime
|
| 3 |
+
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
import numpy as np
|
| 6 |
+
import streamlit as st
|
| 7 |
+
import tensorflow as tf
|
| 8 |
+
|
| 9 |
+
from skimage import io
|
| 10 |
+
from transformer import Transformer
|
| 11 |
+
from tokenizers import ByteLevelBPETokenizer
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
@st.cache_resource
|
| 15 |
+
def load_validator():
|
| 16 |
+
validator_model = tf.keras.models.load_model('checkpoints/cxr_validator_model.tf')
|
| 17 |
+
print('Validator Model Loaded!')
|
| 18 |
+
return validator_model
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
@st.cache_resource
|
| 22 |
+
def load_model():
|
| 23 |
+
|
| 24 |
+
# Load Tokenizer
|
| 25 |
+
tokenizer = ByteLevelBPETokenizer(
|
| 26 |
+
'mimic/mimic-vocab.json',
|
| 27 |
+
'mimic/mimic-merges.txt',
|
| 28 |
+
)
|
| 29 |
+
|
| 30 |
+
# Load Model
|
| 31 |
+
hparams = default_hparams()
|
| 32 |
+
transformer = Transformer(
|
| 33 |
+
num_layers=hparams['num_layers'],
|
| 34 |
+
d_model=hparams['d_model'],
|
| 35 |
+
num_heads=hparams['num_heads'],
|
| 36 |
+
dff=hparams['dff'],
|
| 37 |
+
target_vocab_size=tokenizer.get_vocab_size(),
|
| 38 |
+
dropout_rate=hparams['dropout_rate'])
|
| 39 |
+
transformer.load_weights('checkpoints/RATCHET.tf')
|
| 40 |
+
print(f'Model Loaded! Checkpoint file: checkpoints/RATCHET.tf')
|
| 41 |
+
|
| 42 |
+
return transformer, tokenizer
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def top_k_logits(logits, k):
|
| 46 |
+
if k == 0:
|
| 47 |
+
# no truncation
|
| 48 |
+
return logits
|
| 49 |
+
|
| 50 |
+
def _top_k():
|
| 51 |
+
values, _ = tf.nn.top_k(logits, k=k)
|
| 52 |
+
min_values = values[:, -1, tf.newaxis]
|
| 53 |
+
return tf.where(
|
| 54 |
+
logits < min_values,
|
| 55 |
+
tf.ones_like(logits, dtype=logits.dtype) * -1e10,
|
| 56 |
+
logits,
|
| 57 |
+
)
|
| 58 |
+
return tf.cond(
|
| 59 |
+
tf.equal(k, 0),
|
| 60 |
+
lambda: logits,
|
| 61 |
+
lambda: _top_k(),
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def top_p_logits(logits, p):
|
| 66 |
+
"""Nucleus sampling"""
|
| 67 |
+
batch, _ = logits.shape.as_list()
|
| 68 |
+
sorted_logits = tf.sort(logits, direction='DESCENDING', axis=-1)
|
| 69 |
+
cumulative_probs = tf.cumsum(tf.nn.softmax(sorted_logits, axis=-1), axis=-1)
|
| 70 |
+
indices = tf.stack([
|
| 71 |
+
tf.range(0, batch),
|
| 72 |
+
# number of indices to include
|
| 73 |
+
tf.maximum(tf.reduce_sum(tf.cast(cumulative_probs <= p, tf.int32), axis=-1) - 1, 0),
|
| 74 |
+
], axis=-1)
|
| 75 |
+
min_values = tf.gather_nd(sorted_logits, indices)
|
| 76 |
+
return tf.where(
|
| 77 |
+
logits < min_values,
|
| 78 |
+
tf.ones_like(logits) * -1e10,
|
| 79 |
+
logits,
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
def evaluate(inp_img, tokenizer, transformer, temperature, top_k, top_p, options, seed, MAX_LENGTH=128):
|
| 84 |
+
|
| 85 |
+
# The first token to the transformer should be the start token
|
| 86 |
+
output = tf.convert_to_tensor([[tokenizer.token_to_id('<s>')]])
|
| 87 |
+
|
| 88 |
+
my_bar = st.progress(0)
|
| 89 |
+
for i in tqdm.tqdm(range(MAX_LENGTH)):
|
| 90 |
+
my_bar.progress(i/MAX_LENGTH)
|
| 91 |
+
|
| 92 |
+
# predictions.shape == (batch_size, seq_len, vocab_size)
|
| 93 |
+
predictions = transformer([inp_img, output], training=False)
|
| 94 |
+
|
| 95 |
+
# select the last word from the seq_len dimension
|
| 96 |
+
predictions = predictions[:, -1, :] / temperature # (batch_size, vocab_size)
|
| 97 |
+
predictions = top_k_logits(predictions, k=top_k)
|
| 98 |
+
predictions = top_p_logits(predictions, p=top_p)
|
| 99 |
+
|
| 100 |
+
if options == 'Greedy':
|
| 101 |
+
predicted_id = tf.cast(tf.argmax(predictions, axis=-1), tf.int32)[:, tf.newaxis]
|
| 102 |
+
elif options == 'Sampling':
|
| 103 |
+
predicted_id = tf.random.categorical(predictions, num_samples=1, dtype=tf.int32, seed=seed)
|
| 104 |
+
else:
|
| 105 |
+
st.write('SHOULD NOT HAPPEN')
|
| 106 |
+
|
| 107 |
+
# return the result if the predicted_id is equal to the end token
|
| 108 |
+
if predicted_id == 2: # stop token #tokenizer_en.vocab_size + 1:
|
| 109 |
+
my_bar.empty()
|
| 110 |
+
break
|
| 111 |
+
|
| 112 |
+
# concatentate the predicted_id to the output which is given to the decoder
|
| 113 |
+
# as its input.
|
| 114 |
+
output = tf.concat([output, predicted_id], axis=-1)
|
| 115 |
+
|
| 116 |
+
my_bar.empty()
|
| 117 |
+
|
| 118 |
+
# transformer([inp_img, output[:, :-1]], training=False)
|
| 119 |
+
return tf.squeeze(output, axis=0)[1:], transformer.decoder.last_attn_scores
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def main():
|
| 123 |
+
|
| 124 |
+
st.title('Chest X-ray AI Diagnosis Demo')
|
| 125 |
+
st.text('Made with Streamlit and Attention RNN')
|
| 126 |
+
|
| 127 |
+
transformer, tokenizer = load_model()
|
| 128 |
+
cxr_validator_model = load_validator()
|
| 129 |
+
|
| 130 |
+
st.sidebar.title('Configuration')
|
| 131 |
+
options = st.sidebar.selectbox('Generation Method', ('Greedy', 'Sampling'))
|
| 132 |
+
seed = st.sidebar.number_input('Sampling Seed:', value=42)
|
| 133 |
+
temperature = st.sidebar.number_input('Temperature', value=1.)
|
| 134 |
+
top_k = st.sidebar.slider('top_k', min_value=0, max_value=tokenizer.get_vocab_size(), value=6, step=1)
|
| 135 |
+
top_p = st.sidebar.slider('top_p', min_value=0., max_value=1., value=1., step=0.01)
|
| 136 |
+
attention_head = st.sidebar.slider('attention_head', min_value=-1, max_value=7, value=-1, step=1)
|
| 137 |
+
|
| 138 |
+
st.sidebar.info('PRIVACY POLICY: Uploaded images are never stored on disk.')
|
| 139 |
+
|
| 140 |
+
st.set_option('deprecation.showfileUploaderEncoding', False)
|
| 141 |
+
uploaded_file = st.file_uploader('Choose an image...', type=('png', 'jpg', 'jpeg'))
|
| 142 |
+
|
| 143 |
+
if uploaded_file:
|
| 144 |
+
|
| 145 |
+
# Read input image with size [1, H, W, 1] and range (0, 255)
|
| 146 |
+
img_array = io.imread(uploaded_file, as_gray=True)[None, ..., None]
|
| 147 |
+
|
| 148 |
+
# Convert image to float values in (0, 1)
|
| 149 |
+
img_array = tf.image.convert_image_dtype(img_array, tf.float32)
|
| 150 |
+
|
| 151 |
+
# Resize image with padding to [1, 224, 224, 1]
|
| 152 |
+
img_array = tf.image.resize_with_pad(img_array, 224, 224, method=tf.image.ResizeMethod.BILINEAR)
|
| 153 |
+
|
| 154 |
+
# Display input image
|
| 155 |
+
st.image(np.squeeze(img_array.numpy()), caption='Uploaded Image')
|
| 156 |
+
|
| 157 |
+
# Check image
|
| 158 |
+
valid = tf.nn.sigmoid(cxr_validator_model(img_array))
|
| 159 |
+
if valid < 0.1:
|
| 160 |
+
st.info('Image is not a Chest X-ray')
|
| 161 |
+
return
|
| 162 |
+
|
| 163 |
+
# Log datetime
|
| 164 |
+
print('[{}] Running Analysis...'
|
| 165 |
+
.format(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")))
|
| 166 |
+
|
| 167 |
+
# Generate radiology report
|
| 168 |
+
with st.spinner('Generating report... Do not refresh or close window.'):
|
| 169 |
+
result, attention_weights = evaluate(img_array, tokenizer, transformer,
|
| 170 |
+
temperature, top_k, top_p,
|
| 171 |
+
options, seed)
|
| 172 |
+
predicted_sentence = tokenizer.decode(result)
|
| 173 |
+
|
| 174 |
+
# Display generated text
|
| 175 |
+
st.subheader('Generated Report:')
|
| 176 |
+
st.write(predicted_sentence)
|
| 177 |
+
# st.info(predicted_sentence)
|
| 178 |
+
|
| 179 |
+
st.subheader('Attention Plot:')
|
| 180 |
+
|
| 181 |
+
attn_map = attention_weights[0] # squeeze
|
| 182 |
+
if attention_head == -1: # average attention heads
|
| 183 |
+
attn_map = tf.reduce_mean(attn_map, axis=0)
|
| 184 |
+
else: # select attention heads
|
| 185 |
+
attn_map = attn_map[attention_head]
|
| 186 |
+
attn_map = attn_map / attn_map.numpy().max() * 255
|
| 187 |
+
|
| 188 |
+
fig = plt.figure(figsize=(40, 80))
|
| 189 |
+
|
| 190 |
+
for i in range(attn_map.shape[0] - 1):
|
| 191 |
+
attn_token = attn_map[i, ...]
|
| 192 |
+
attn_token = tf.reshape(attn_token, [7, 7])
|
| 193 |
+
|
| 194 |
+
ax = fig.add_subplot(16, 8, i + 1)
|
| 195 |
+
ax.set_title(tokenizer.decode([result.numpy()[i]]))
|
| 196 |
+
img = ax.imshow(np.squeeze(img_array))
|
| 197 |
+
ax.imshow(attn_token, cmap='gray', alpha=0.6, extent=img.get_extent())
|
| 198 |
+
|
| 199 |
+
st.pyplot(plt)
|
| 200 |
+
|
| 201 |
+
# Run again?
|
| 202 |
+
st.button('Regenerate Report')
|
| 203 |
+
|
| 204 |
+
|
| 205 |
+
if __name__ == '__main__':
|
| 206 |
+
|
| 207 |
+
tf.config.set_visible_devices([], 'GPU')
|
| 208 |
+
|
| 209 |
+
main()
|
assets/attn_plot.png
ADDED

|
Git LFS Details
|
assets/examples.png
ADDED
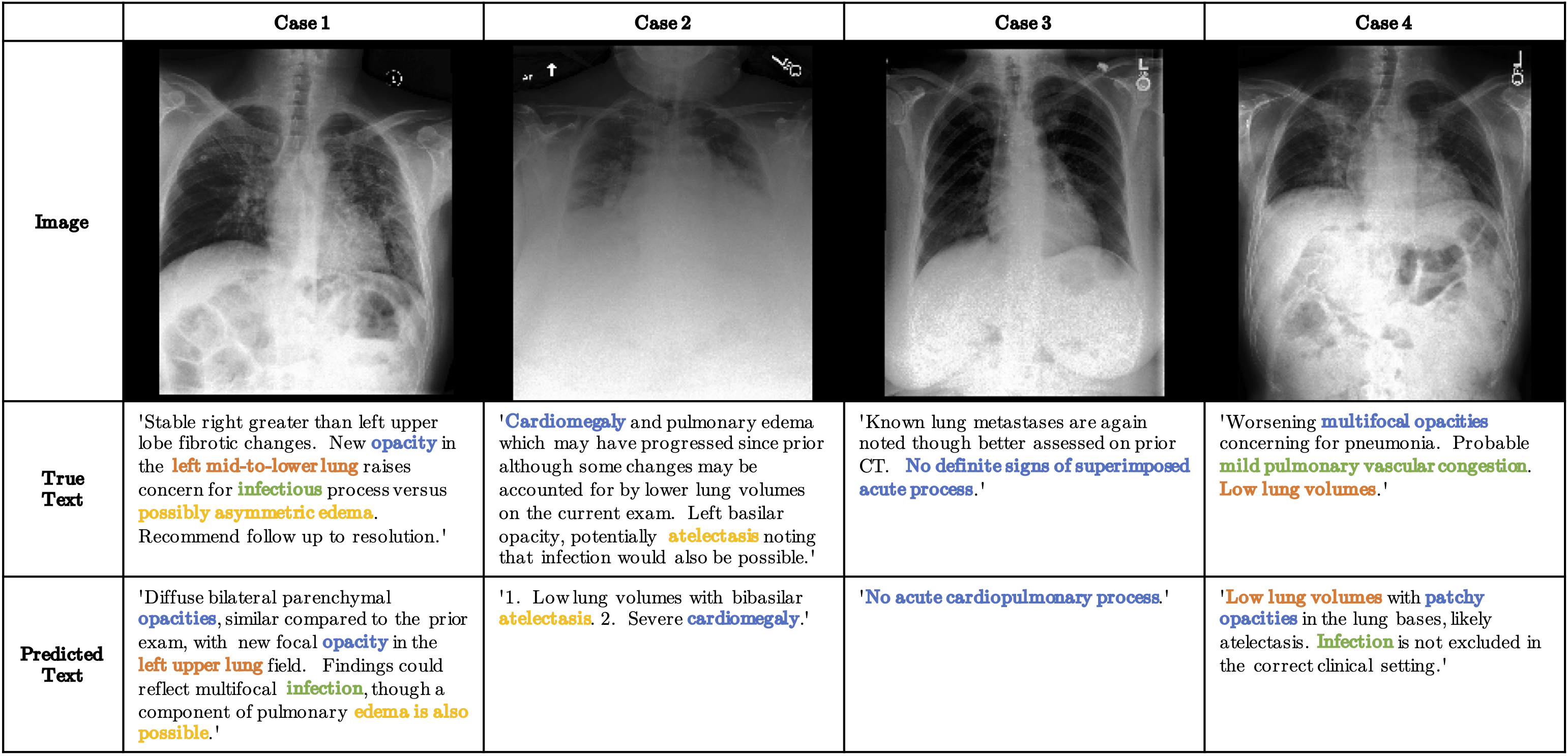
|
Git LFS Details
|
assets/model_transformer.png
ADDED
|
|
checkpoints/RATCHET.tf/keras_metadata.pb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a8fa018ac83d10617e20e3f03de3718d9d3d6e1b89673707cb510318fd3198b3
|
| 3 |
+
size 1065144
|
checkpoints/RATCHET.tf/saved_model.pb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:84e9d837b881c58edee113c7bbdc793159e6e57c2ddcf9d2a3e4da7c5104a7db
|
| 3 |
+
size 26013311
|
checkpoints/RATCHET.tf/variables/variables.data-00000-of-00001
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ae18face6fa821f8c6c62923ef5533fca681e01b6bb8ae511a9c94844f618c8e
|
| 3 |
+
size 1669994429
|
checkpoints/RATCHET.tf/variables/variables.index
ADDED
|
Binary file (121 kB). View file
|
|
|
checkpoints/cxr_validator_model.tf/fingerprint.pb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:21a31ac72a46d124de283ecbd75c35efc8ac0c5f597efd3040ed8dd00d071ef2
|
| 3 |
+
size 53
|
checkpoints/cxr_validator_model.tf/keras_metadata.pb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:19106ee698a03e8b9ec11b0092fd65c32654380171a3c55a7976d56313e4438a
|
| 3 |
+
size 2538679
|
checkpoints/cxr_validator_model.tf/saved_model.pb
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:16e7434007981626733e6f925cd0b226e1f4130cfaec7e79ba81ffd16d7ab1cb
|
| 3 |
+
size 14320368
|
checkpoints/cxr_validator_model.tf/variables/variables.data-00000-of-00001
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e2edd5cef46c1624f31464e13f3b5fb8c0ceb4ce8a1d834a6cde9c2e71dd509e
|
| 3 |
+
size 224256098
|
checkpoints/cxr_validator_model.tf/variables/variables.index
ADDED
|
Binary file (51.9 kB). View file
|
|
|
mimic/mimic-merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
mimic/mimic-vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
matplotlib
|
| 2 |
+
numpy
|
| 3 |
+
scikit-image
|
| 4 |
+
tensorflow
|
| 5 |
+
tokenizers
|
| 6 |
+
tqdm
|
transformer.py
ADDED
|
@@ -0,0 +1,263 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import absolute_import
|
| 2 |
+
from __future__ import division
|
| 3 |
+
from __future__ import print_function
|
| 4 |
+
from __future__ import unicode_literals
|
| 5 |
+
|
| 6 |
+
import datetime
|
| 7 |
+
|
| 8 |
+
import numpy as np
|
| 9 |
+
import tensorflow as tf
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def default_hparams():
|
| 13 |
+
return {
|
| 14 |
+
'img_x': 224,
|
| 15 |
+
'img_y': 224,
|
| 16 |
+
'img_ch': 1,
|
| 17 |
+
'd_model': 512,
|
| 18 |
+
'dff': 2048,
|
| 19 |
+
'num_heads': 8,
|
| 20 |
+
'num_layers': 6,
|
| 21 |
+
'dropout_rate': 0.1
|
| 22 |
+
}
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def positional_encoding(length, depth):
|
| 26 |
+
depth = depth / 2
|
| 27 |
+
|
| 28 |
+
positions = np.arange(length)[:, np.newaxis] # (seq, 1)
|
| 29 |
+
depths = np.arange(depth)[np.newaxis, :] / depth # (1, depth)
|
| 30 |
+
|
| 31 |
+
angle_rates = 1 / (10000 ** depths) # (1, depth)
|
| 32 |
+
angle_rads = positions * angle_rates # (pos, depth)
|
| 33 |
+
|
| 34 |
+
pos_encoding = np.concatenate(
|
| 35 |
+
[np.sin(angle_rads), np.cos(angle_rads)],
|
| 36 |
+
axis=-1)
|
| 37 |
+
|
| 38 |
+
return tf.cast(pos_encoding, dtype=tf.float32)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
class PositionalEmbedding(tf.keras.layers.Layer):
|
| 42 |
+
def __init__(self, vocab_size, d_model):
|
| 43 |
+
super().__init__()
|
| 44 |
+
self.d_model = d_model
|
| 45 |
+
self.embedding = tf.keras.layers.Embedding(vocab_size, d_model, mask_zero=True)
|
| 46 |
+
self.pos_encoding = positional_encoding(length=2048, depth=d_model)
|
| 47 |
+
|
| 48 |
+
def compute_mask(self, *args, **kwargs):
|
| 49 |
+
return self.embedding.compute_mask(*args, **kwargs)
|
| 50 |
+
|
| 51 |
+
def call(self, x):
|
| 52 |
+
length = tf.shape(x)[1]
|
| 53 |
+
x = self.embedding(x)
|
| 54 |
+
# This factor sets the relative scale of the embedding and positonal_encoding.
|
| 55 |
+
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
|
| 56 |
+
x = x + self.pos_encoding[tf.newaxis, :length, :]
|
| 57 |
+
return x
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class BaseAttention(tf.keras.layers.Layer):
|
| 61 |
+
def __init__(self, **kwargs):
|
| 62 |
+
super().__init__()
|
| 63 |
+
self.mha = tf.keras.layers.MultiHeadAttention(**kwargs)
|
| 64 |
+
self.layernorm = tf.keras.layers.LayerNormalization()
|
| 65 |
+
self.add = tf.keras.layers.Add()
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
class CrossAttention(BaseAttention):
|
| 69 |
+
def call(self, x, context):
|
| 70 |
+
attn_output, attn_scores = self.mha(
|
| 71 |
+
query=x,
|
| 72 |
+
key=context,
|
| 73 |
+
value=context,
|
| 74 |
+
return_attention_scores=True)
|
| 75 |
+
|
| 76 |
+
# Cache the attention scores for plotting later.
|
| 77 |
+
self.last_attn_scores = attn_scores
|
| 78 |
+
|
| 79 |
+
x = self.add([x, attn_output])
|
| 80 |
+
x = self.layernorm(x)
|
| 81 |
+
|
| 82 |
+
return x
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class CausalSelfAttention(BaseAttention):
|
| 86 |
+
def call(self, x):
|
| 87 |
+
attn_output = self.mha(
|
| 88 |
+
query=x,
|
| 89 |
+
value=x,
|
| 90 |
+
key=x,
|
| 91 |
+
use_causal_mask=True)
|
| 92 |
+
x = self.add([x, attn_output])
|
| 93 |
+
x = self.layernorm(x)
|
| 94 |
+
return x
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class FeedForward(tf.keras.layers.Layer):
|
| 98 |
+
def __init__(self, d_model, dff, dropout_rate=0.1):
|
| 99 |
+
super().__init__()
|
| 100 |
+
self.seq = tf.keras.Sequential([
|
| 101 |
+
tf.keras.layers.Dense(dff, activation='relu'),
|
| 102 |
+
tf.keras.layers.Dense(d_model),
|
| 103 |
+
tf.keras.layers.Dropout(dropout_rate)
|
| 104 |
+
])
|
| 105 |
+
self.add = tf.keras.layers.Add()
|
| 106 |
+
self.layer_norm = tf.keras.layers.LayerNormalization()
|
| 107 |
+
|
| 108 |
+
def call(self, x):
|
| 109 |
+
x = self.add([x, self.seq(x)])
|
| 110 |
+
x = self.layer_norm(x)
|
| 111 |
+
return x
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
class DecoderLayer(tf.keras.layers.Layer):
|
| 115 |
+
def __init__(self,
|
| 116 |
+
*,
|
| 117 |
+
d_model,
|
| 118 |
+
num_heads,
|
| 119 |
+
dff,
|
| 120 |
+
dropout_rate=0.1):
|
| 121 |
+
super(DecoderLayer, self).__init__()
|
| 122 |
+
|
| 123 |
+
self.causal_self_attention = CausalSelfAttention(
|
| 124 |
+
num_heads=num_heads,
|
| 125 |
+
key_dim=d_model,
|
| 126 |
+
dropout=dropout_rate)
|
| 127 |
+
|
| 128 |
+
self.cross_attention = CrossAttention(
|
| 129 |
+
num_heads=num_heads,
|
| 130 |
+
key_dim=d_model,
|
| 131 |
+
dropout=dropout_rate)
|
| 132 |
+
|
| 133 |
+
self.ffn = FeedForward(d_model, dff)
|
| 134 |
+
|
| 135 |
+
def call(self, x, context):
|
| 136 |
+
x = self.causal_self_attention(x=x)
|
| 137 |
+
x = self.cross_attention(x=x, context=context)
|
| 138 |
+
|
| 139 |
+
# Cache the last attention scores for plotting later
|
| 140 |
+
self.last_attn_scores = self.cross_attention.last_attn_scores
|
| 141 |
+
|
| 142 |
+
x = self.ffn(x) # Shape `(batch_size, seq_len, d_model)`.
|
| 143 |
+
return x
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
class Encoder(tf.keras.layers.Layer):
|
| 147 |
+
def __init__(self, embedding_dim, input_shape, pretrain_weights=None):
|
| 148 |
+
super(Encoder, self).__init__()
|
| 149 |
+
|
| 150 |
+
# shape after fc == (batch_size, nf * nf, embedding_dim)
|
| 151 |
+
self.fc = tf.keras.layers.Dense(embedding_dim, activation='relu')
|
| 152 |
+
|
| 153 |
+
# Use DenseNet-121 as feature extraction model
|
| 154 |
+
self.base_model = tf.keras.applications.DenseNet121(
|
| 155 |
+
include_top=False, weights=None, input_shape=input_shape)
|
| 156 |
+
|
| 157 |
+
# Load pre-trained weights if present
|
| 158 |
+
if pretrain_weights:
|
| 159 |
+
print(f'{datetime.datetime.now()}: I Loading Pretrained DenseNet-121 weights: {pretrain_weights}')
|
| 160 |
+
self.base_model.load_weights(pretrain_weights)
|
| 161 |
+
else:
|
| 162 |
+
print(f'{datetime.datetime.now()}: I No Pretrained DenseNet-121 weights specified')
|
| 163 |
+
|
| 164 |
+
def call(self, x, **kwargs):
|
| 165 |
+
x = self.base_model(x)
|
| 166 |
+
# DenseNet-121 output is (batch_size, ?, ?, 1024)
|
| 167 |
+
s = tf.shape(x)
|
| 168 |
+
x = tf.reshape(x, (s[0], s[1] * s[2], x.shape[3]))
|
| 169 |
+
x = self.fc(x)
|
| 170 |
+
return x
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
class Decoder(tf.keras.layers.Layer):
|
| 174 |
+
def __init__(self, *, num_layers, d_model, num_heads, dff, vocab_size,
|
| 175 |
+
dropout_rate=0.1):
|
| 176 |
+
super(Decoder, self).__init__()
|
| 177 |
+
|
| 178 |
+
self.d_model = d_model
|
| 179 |
+
self.num_layers = num_layers
|
| 180 |
+
|
| 181 |
+
self.pos_embedding = PositionalEmbedding(vocab_size=vocab_size,
|
| 182 |
+
d_model=d_model)
|
| 183 |
+
self.dropout = tf.keras.layers.Dropout(dropout_rate)
|
| 184 |
+
self.dec_layers = [
|
| 185 |
+
DecoderLayer(d_model=d_model, num_heads=num_heads,
|
| 186 |
+
dff=dff, dropout_rate=dropout_rate)
|
| 187 |
+
for _ in range(num_layers)]
|
| 188 |
+
|
| 189 |
+
self.last_attn_scores = None
|
| 190 |
+
|
| 191 |
+
def call(self, x, context):
|
| 192 |
+
# `x` is token-IDs shape (batch, target_seq_len)
|
| 193 |
+
x = self.pos_embedding(x) # (batch_size, target_seq_len, d_model)
|
| 194 |
+
|
| 195 |
+
x = self.dropout(x)
|
| 196 |
+
|
| 197 |
+
for i in range(self.num_layers):
|
| 198 |
+
x = self.dec_layers[i](x, context)
|
| 199 |
+
|
| 200 |
+
self.last_attn_scores = self.dec_layers[-1].last_attn_scores
|
| 201 |
+
|
| 202 |
+
# The shape of x is (batch_size, target_seq_len, d_model).
|
| 203 |
+
return x
|
| 204 |
+
|
| 205 |
+
|
| 206 |
+
class Transformer(tf.keras.Model):
|
| 207 |
+
def __init__(self, num_layers, d_model, num_heads, dff,
|
| 208 |
+
target_vocab_size, dropout_rate=0.1, input_shape=(224, 224, 1),
|
| 209 |
+
classifier_weights=None):
|
| 210 |
+
super(Transformer, self).__init__()
|
| 211 |
+
|
| 212 |
+
self.encoder = Encoder(d_model, input_shape,
|
| 213 |
+
pretrain_weights=classifier_weights)
|
| 214 |
+
|
| 215 |
+
self.decoder = Decoder(num_layers=num_layers, d_model=d_model,
|
| 216 |
+
num_heads=num_heads, dff=dff,
|
| 217 |
+
vocab_size=target_vocab_size,
|
| 218 |
+
dropout_rate=dropout_rate)
|
| 219 |
+
|
| 220 |
+
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
|
| 221 |
+
|
| 222 |
+
def call(self, inputs):
|
| 223 |
+
# To use a Keras model with `.fit` you must pass all your inputs in the
|
| 224 |
+
# first argument.
|
| 225 |
+
context, x = inputs
|
| 226 |
+
|
| 227 |
+
context = self.encoder(context) # (batch_size, context_len, d_model)
|
| 228 |
+
|
| 229 |
+
x = self.decoder(x, context) # (batch_size, target_len, d_model)
|
| 230 |
+
|
| 231 |
+
# Final linear layer output.
|
| 232 |
+
logits = self.final_layer(x) # (batch_size, target_len, target_vocab_size)
|
| 233 |
+
|
| 234 |
+
try:
|
| 235 |
+
# Drop the keras mask, so it doesn't scale the losses/metrics.
|
| 236 |
+
# b/250038731
|
| 237 |
+
del logits._keras_mask
|
| 238 |
+
except AttributeError:
|
| 239 |
+
pass
|
| 240 |
+
|
| 241 |
+
# Return the final output and the attention weights.
|
| 242 |
+
return logits
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
if __name__ == "__main__":
|
| 246 |
+
|
| 247 |
+
hparams = default_hparams()
|
| 248 |
+
|
| 249 |
+
transformer = Transformer(
|
| 250 |
+
num_layers=hparams['num_layers'],
|
| 251 |
+
d_model=hparams['d_model'],
|
| 252 |
+
num_heads=hparams['num_heads'],
|
| 253 |
+
dff=hparams['dff'],
|
| 254 |
+
target_vocab_size=2048,
|
| 255 |
+
dropout_rate=hparams['dropout_rate'])
|
| 256 |
+
|
| 257 |
+
a=1
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
image = np.random.rand(1,224,224,1).astype('float32')
|
| 261 |
+
text = np.random.randint(0, 2048, size=(1, 27))
|
| 262 |
+
|
| 263 |
+
output = transformer((image, text))
|