

Commit
·
676df31
verified
·
0
Parent(s):
Duplicate from OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview
Browse filesCo-authored-by: Weiyun Wang <[email protected]>
- .gitattributes +38 -0
- README.md +1486 -0
- chat_template.jinja +397 -0
- config.json +124 -0
- configuration_intern_vit.py +119 -0
- configuration_internvl_chat.py +118 -0
- conversation.py +416 -0
- examples/image1.jpg +0 -0
- examples/image2.jpg +3 -0
- examples/red-panda.mp4 +3 -0
- generation_config.json +4 -0
- model-00001-of-00009.safetensors +3 -0
- model-00002-of-00009.safetensors +3 -0
- model-00003-of-00009.safetensors +3 -0
- model-00004-of-00009.safetensors +3 -0
- model-00005-of-00009.safetensors +3 -0
- model-00006-of-00009.safetensors +3 -0
- model-00007-of-00009.safetensors +3 -0
- model-00008-of-00009.safetensors +3 -0
- model-00009-of-00009.safetensors +3 -0
- model.safetensors.index.json +765 -0
- modeling_intern_vit.py +433 -0
- modeling_internvl_chat.py +399 -0
- preprocessor_config.json +34 -0
- processor_config.json +4 -0
- special_tokens_map.json +23 -0
- tokenizer.json +3 -0
- tokenizer_config.json +256 -0
- video_preprocessor_config.json +70 -0
.gitattributes
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
examples/image2.jpg filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
examples/red-panda.mp4 filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,1486 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
pipeline_tag: image-text-to-text
|
| 4 |
+
library_name: transformers
|
| 5 |
+
base_model:
|
| 6 |
+
- OpenGVLab/InternViT-300M-448px-V2_5
|
| 7 |
+
- openai/gpt-oss-20b
|
| 8 |
+
base_model_relation: merge
|
| 9 |
+
datasets:
|
| 10 |
+
- OpenGVLab/MMPR-v1.2
|
| 11 |
+
- OpenGVLab/MMPR-Tiny
|
| 12 |
+
language:
|
| 13 |
+
- multilingual
|
| 14 |
+
tags:
|
| 15 |
+
- internvl
|
| 16 |
+
- custom_code
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
# InternVL3_5-GPT-OSS-20B-A4B-Preview
|
| 20 |
+
|
| 21 |
+
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479) [\[📜 InternVL3.5\]](https://huggingface.co/papers/2508.18265)
|
| 22 |
+
|
| 23 |
+
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://chat.intern-ai.org.cn/) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
|
| 24 |
+
|
| 25 |
+
<div align="center">
|
| 26 |
+
<img width="500" alt="image" src="https://cdn-uploads.huggingface.co/production/uploads/64006c09330a45b03605bba3/zJsd2hqd3EevgXo6fNgC-.png">
|
| 27 |
+
</div>
|
| 28 |
+
|
| 29 |
+
## Introduction
|
| 30 |
+
|
| 31 |
+
We introduce *InternVL3.5*, a new family of open-source multimodal models that significantly advances versatility, reasoning capability, and inference efficiency along the InternVL series. A key innovation is the *Cascade Reinforcement Learning (Cascade RL)* framework, which enhances reasoning through a two-stage process: offline RL for stable convergence and online RL for refined alignment. This coarse-to-fine training strategy leads to substantial improvements on downstream reasoning tasks, e.g., MMMU and MathVista. To optimize efficiency, we propose a *Visual Resolution Router (ViR)* that dynamically adjusts the resolution of visual tokens without compromising performance. Coupled with ViR, our Decoupled *Vision-Language Deployment (DvD)* strategy separates the vision encoder and language model across different GPUs, effectively balancing computational load. These contributions collectively enable InternVL3.5 to achieve up to a +16.0\% gain in overall reasoning performance and a 4.05 \\(\times\\) inference speedup compared to its predecessor, i.e., InternVL3. In addition, InternVL3.5 supports novel capabilities such as GUI interaction and embodied agency. Notably, our largest model, i.e., InternVL3.5-241B-A28B, attains state-of-the-art results among open-source MLLMs across general multimodal, reasoning, text, and agentic tasks—narrowing the performance gap with leading commercial models like GPT-5. All models and code are publicly released.
|
| 32 |
+
|
| 33 |
+

|
| 34 |
+
|
| 35 |
+
> Hatched bars represent closed-source commercial models. We report average scores on a set of multimodal general, reasoning, text, and agentic benchmarks: MMBench v1.1 (en), MMStar,BLINK, HallusionBench, AI2D, OCRBench, MMVet, MME-RealWorld (en), MVBench, VideoMME, MMMU, MathVista, MathVision, MathVerse, DynaMath, WeMath, LogicVista, MATH500, AIME24, AIME25, GPQA, MMLU-Pro, GAOKAO, IFEval, SGP-Bench, VSI-Bench, ERQA, SpaCE-10, and OmniSpatial.
|
| 36 |
+
|
| 37 |
+
See [quick start](#quick-start) for how to use our model.
|
| 38 |
+
|
| 39 |
+
## InternVL3.5 Family
|
| 40 |
+
|
| 41 |
+
In the following table, we provide an overview of the InternVL3.5 series.
|
| 42 |
+
To maintain consistency with earlier generations, we provide two model formats: [the GitHub format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B), consistent with prior releases, and [the HF format](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF), aligned with the official Transformers standard.
|
| 43 |
+
|
| 44 |
+
> If you want to convert the checkpoint between these two formats, please refer to the scripts about [custom2hf](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_custom2hf.py) and [hf2custom](https://github.com/OpenGVLab/InternVL/blob/main/internvl_chat/tools/internvl_hf2custom.py).
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
### Github Format
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
|
| 51 |
+
| --------------------- | ------------- | --------------- | ------------ | ------------------------------------------------------------------------------ | ---------------------------------------------------------------------------------------- |
|
| 52 |
+
| InternVL3.5-1B | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
|
| 53 |
+
| InternVL3.5-2B | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
|
| 54 |
+
| InternVL3.5-4B | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
|
| 55 |
+
| InternVL3.5-8B | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
|
| 56 |
+
| InternVL3.5-14B | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
|
| 57 |
+
| InternVL3.5-38B | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
|
| 58 |
+
| InternVL3.5-20B-A4B | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview) |
|
| 59 |
+
| InternVL3.5-30B-A3B | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
|
| 60 |
+
| InternVL3.5-241B-A28B | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
### HuggingFace Format
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
| Model | #Vision Param | #Language Param | #Total Param | HF Link | ModelScope Link |
|
| 67 |
+
| ------------------------ | ------------- | --------------- | ------------ | --------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- |
|
| 68 |
+
| InternVL3.5-1B-HF | 0.3B | 0.8B | 1.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-HF) |
|
| 69 |
+
| InternVL3.5-2B-HF | 0.3B | 2.0B | 2.3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-HF) |
|
| 70 |
+
| InternVL3.5-4B-HF | 0.3B | 4.4B | 4.7B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-HF) |
|
| 71 |
+
| InternVL3.5-8B-HF | 0.3B | 8.2B | 8.5B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-HF) |
|
| 72 |
+
| InternVL3.5-14B-HF | 0.3B | 14.8B | 15.1B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-HF) |
|
| 73 |
+
| InternVL3.5-38B-HF | 5.5B | 32.8B | 38.4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-HF) |
|
| 74 |
+
| InternVL3.5-20B-A4B-HF | 0.3B | 20.9B | 21.2B-A4B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-GPT-OSS-20B-A4B-Preview-HF) |
|
| 75 |
+
| InternVL3.5-30B-A3B-HF | 0.3B | 30.5B | 30.8B-A3B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-HF) |
|
| 76 |
+
| InternVL3.5-241B-A28B-HF | 5.5B | 235.1B | 240.7B-A28B | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-HF) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-HF) |
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+

|
| 80 |
+
|
| 81 |
+
> We conduct the evaluation with [VLMEvalkit](https://github.com/open-compass/VLMEvalKit). ***To enable the Thinking mode of our model, please set the system prompt to [R1_SYSTEM_PROMPT](https://github.com/open-compass/VLMEvalKit/blob/main/vlmeval/vlm/internvl/internvl_chat.py#L38).*** When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
|
| 82 |
+
|
| 83 |
+
Our training pipeline comprises four stages: Multimodal Continual Pre-Training (**CPT**), Supervised Fine-Tuning (**SFT**), and Cascade Reinforcement Learning (**CascadeRL**). In CascadeRL, we first fine-tune the model using Mixed Preference Optimization (**MPO**) under an offline RL setting, followed by **GSPO** under an oneline RL setting.
|
| 84 |
+
For the Flash version of InternVL3.5, we additionally introduce a lightweight training stage, termed Visual Consistency Learning (**ViCO**), which reduces the token cost required to represent an image patch.
|
| 85 |
+
|
| 86 |
+

|
| 87 |
+
|
| 88 |
+
Here, we also open-source the model weights after different training stages for potential research usage.
|
| 89 |
+
***If you're unsure which version to use, please select the one without any suffix, as it has completed the full training pipeline.***
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
| Model | Training Pipeline | HF Link | ModelScope Link |
|
| 93 |
+
| -------------------------------- | --------------------- | --------------------------------------------------------------------------- | ------------------------------------------------------------------------------------- |
|
| 94 |
+
| InternVL3.5-1B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Pretrained) |
|
| 95 |
+
| InternVL3.5-1B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-Instruct) |
|
| 96 |
+
| InternVL3.5-1B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B-MPO) |
|
| 97 |
+
| InternVL3.5-1B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-1B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-1B) |
|
| 98 |
+
| InternVL3.5-2B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Pretrained) |
|
| 99 |
+
| InternVL3.5-2B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-Instruct) |
|
| 100 |
+
| InternVL3.5-2B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B-MPO) |
|
| 101 |
+
| InternVL3.5-2B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-2B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-2B) |
|
| 102 |
+
| InternVL3.5-4B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Pretrained) |
|
| 103 |
+
| InternVL3.5-4B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-Instruct) |
|
| 104 |
+
| InternVL3.5-4B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B-MPO) |
|
| 105 |
+
| InternVL3.5-4B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-4B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-4B) |
|
| 106 |
+
| InternVL3.5-8B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Pretrained) |
|
| 107 |
+
| InternVL3.5-8B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-Instruct) |
|
| 108 |
+
| InternVL3.5-8B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B-MPO) |
|
| 109 |
+
| InternVL3.5-8B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-8B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-8B) |
|
| 110 |
+
| InternVL3.5-14B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Pretrained) |
|
| 111 |
+
| InternVL3.5-14B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-Instruct) |
|
| 112 |
+
| InternVL3.5-14B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B-MPO) |
|
| 113 |
+
| InternVL3.5-14B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-14B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-14B) |
|
| 114 |
+
| InternVL3.5-30B-A3B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Pretrained) |
|
| 115 |
+
| InternVL3.5-30B-A3B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-Instruct) |
|
| 116 |
+
| InternVL3.5-30B-A3B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B-MPO) |
|
| 117 |
+
| InternVL3.5-30B-A3B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-30B-A3B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-30B-A3B) |
|
| 118 |
+
| InternVL3.5-38B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Pretrained) |
|
| 119 |
+
| InternVL3.5-38B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-Instruct) |
|
| 120 |
+
| InternVL3.5-38B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B-MPO) |
|
| 121 |
+
| InternVL3.5-38B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-38B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-38B) |
|
| 122 |
+
| InternVL3.5-241B-A28B-Pretrained | CPT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Pretrained) |
|
| 123 |
+
| InternVL3.5-241B-A28B-Instruct | CPT + SFT | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-Instruct) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-Instruct) |
|
| 124 |
+
| InternVL3.5-241B-A28B-MPO | CPT + SFT + MPO | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B-MPO) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B-MPO) |
|
| 125 |
+
| InternVL3.5-241B-A28B | CPT + SFT + CascadeRL | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3_5-241B-A28B) | [🤖 link](https://www.modelscope.cn/models/OpenGVLab/InternVL3_5-241B-A28B) |
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
The Flash version of our model will be released as soon as possible.
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
## Model Architecture
|
| 133 |
+
|
| 134 |
+
`InternVL3.5`:
|
| 135 |
+
This series of models follow the "ViT–MLP–LLM" paradigm adopted in previous versions of InternVL.
|
| 136 |
+
We initialize the language model using the Qwen3 series and GPT-OSS, and the vision encoder using InternViT-300M and InternViT-6B.
|
| 137 |
+
The Dynamic High Resolution strategy introduced in InternVL1.5 is also retained in our design.
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
`InternVL3.5-Flash`:
|
| 141 |
+
Compared to InternVL3.5, InternVL3.5-Flash further integrates the *Visual Resolution Router (ViR)*, thus yielding a series of efficient variants friendly suitable for resource-constrained scenarios.
|
| 142 |
+
Specifically, in InternVL3.5, each image patch is initially represented as 1024 visual tokens for the vision encoder, which are then compressed into 256 tokens via a pixel shuffle module before being passed to the Large Language Model (LLM).
|
| 143 |
+
In InternVL3.5-Flash, as shown in the Figure below, an additional pixel shuffle module with a higher compression rate is included, enabling the compression of visual tokens down to 64 tokens.
|
| 144 |
+
For each patch, the patch router determines the appropriate compression rate by assessing its semantic richness, and routes it to the corresponding pixel shuffle module accordingly.
|
| 145 |
+
Benefiting from this patch-aware compression mechanism, InternVL3.5-Flash is able to reduce the number of visual tokens by 50\% while maintaining nearly 100\% of the performance of InternVL3.5.
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+

|
| 149 |
+
|
| 150 |
+
## Training and Deployment Strategy
|
| 151 |
+
|
| 152 |
+
### Pre-Training
|
| 153 |
+
|
| 154 |
+
During the pre-training stage, we update all model parameters jointly using the combination of large-scale text and multimodal corpora. Specifically, given an arbitrary training sample consisting of a multimodal token sequence \\(\mathbf{x}=\left(x_1, x_2, \ldots, x_L\right)\\), the next token prediction (NTP) loss is calculated on each text token as follows:
|
| 155 |
+
|
| 156 |
+
$$
|
| 157 |
+
\mathcal{L}_{i}=-\log p_\theta\left(x_i \mid x_1, \ldots, x_{i-1}\right),
|
| 158 |
+
$$
|
| 159 |
+
|
| 160 |
+
where \\(x_i\\) is the predicted token and prefix tokens in \\(\{x_1, x_2, \ldots, x_{i-1}\}\\) can be either text tokens or image tokens. Notably, for conversation samples, only response tokens are included for the calculation of the loss.
|
| 161 |
+
Additionally, to mitigate bias toward either longer or shorter responses during training, we adopt the square averaging to re-weight the NTP loss as follows:
|
| 162 |
+
|
| 163 |
+
$$
|
| 164 |
+
\mathcal{L}_{i}^{'} = \frac{w_i}{\sum_j w_j} \cdot \mathcal{L}_i, \quad w_i = \frac{1}{N^{0.5}},
|
| 165 |
+
$$
|
| 166 |
+
|
| 167 |
+
where \\(N\\) denotes the number of tokens in the training sample on which the loss needs to be calculated. The random JPEG compression is also included to enhance the model's real-world performance.
|
| 168 |
+
|
| 169 |
+
### Supervised Fine-Tuning
|
| 170 |
+
|
| 171 |
+
During the SFT phase, we adopt the same objective as in the pre-training stage and use the square-root averaging strategy to calculate the final loss. In this stage, the context window is set to 32K tokens to adapt long-context information.
|
| 172 |
+
Compared to InternVL3, the SFT stage of InternVL3.5 contains more high-quality and diverse training data derived from three sources:
|
| 173 |
+
|
| 174 |
+
(1) Instruction-following data from InternVL3, which are reused to preserve broad coverage of vision–language tasks.
|
| 175 |
+
|
| 176 |
+
(2) Multimodal reasoning data in the "Thinking" mode, which are included to instill long-thinking capabilities in the model. To construct such data, we first use InternVL3-78B to describe the image and then input the description into DeepSeek-R1 to sample rollouts with detailed reasoning processes. Rollouts with an incorrect final answer are filtered out. The questions in these datasets cover various expert domains, such as mathematics and scientific disciplines, thereby strengthening performance on different reasoning tasks.
|
| 177 |
+
|
| 178 |
+
(3) Capability-expansion datasets, which endow InternVL3.5 with new skills, including GUI-based interaction, embodied interaction, and scalable vect
|
| 179 |
+
|
| 180 |
+
### Cascade Reinforcement Learning
|
| 181 |
+
|
| 182 |
+
Cascade RL aims to combine the benefits of offline RL and online RL to progressively facilitate the post-training of MLLMs in an efficient manner.
|
| 183 |
+
Specifically, we first fine-tune the model using an offline RL algorithm as an efficient warm-up stage to reach a satisfied results, which can guarantee the high-quality rollouts for the latter stage.
|
| 184 |
+
Subsequently, we employ an online RL algorithm to further refine the output distribution based on rollouts generated by the model itself. Compared to the single offline or online RL stage, our cascaded RL achieves significant performance improvements at a fraction of the GPU time cost.
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
During the offline RL stage, we employ mixed preference optimization (MPO) to fine-tune the model. Specifically, the training objective of MPO is a combination of preference loss \\(\mathcal{L}_{p}\\), quality loss \\(\mathcal{L}_{q}\\), and generation loss \\(\mathcal{L}_{g}\\), which can be formulated as follows:
|
| 189 |
+
|
| 190 |
+
$$
|
| 191 |
+
\mathcal{L}_{\text{MPO}}=
|
| 192 |
+
w_{p} \mathcal{L}_{p}
|
| 193 |
+
+
|
| 194 |
+
w_{q} \mathcal{L}_{q}
|
| 195 |
+
+
|
| 196 |
+
w_{g} \mathcal{L}_{g}
|
| 197 |
+
,
|
| 198 |
+
$$
|
| 199 |
+
|
| 200 |
+
where \\(w_{*}\\) represents the weight assigned to each loss component.
|
| 201 |
+
The DPO loss, BCO loss, and LM loss serve as the preference loss, quality loss, and generation loss, respectively.
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
During the online RL stage, we employ GSPO, without reference model constraints, as our online RL algorithm, which we find more effective in training both dense and mixture-of-experts (MoE) models. Similar to GRPO, the advantage is defined as the normalized reward across responses sampled from the same query.
|
| 205 |
+
The training objective of GSPO is given by:
|
| 206 |
+
|
| 207 |
+
$$
|
| 208 |
+
\mathcal{L}_{\mathrm{GSPO}}(\theta)=\mathbb{E}_{x \sim \mathcal{D},\left\{y_i\right\}_{i=1}^G \sim \pi_{\theta \text { old }}(\cdot \mid x)}\left[\frac{1}{G} \sum_{i=1}^G \min \left(s_i(\theta) \widehat{A}_i, \operatorname{clip}\left(s_i(\theta), 1-\varepsilon, 1+\varepsilon\right) \widehat{A}_i\right)\right],
|
| 209 |
+
$$
|
| 210 |
+
|
| 211 |
+
where the importance sampling ratio is defined as the geometric mean of the per-token ratios.
|
| 212 |
+
|
| 213 |
+
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
|
| 214 |
+
|
| 215 |
+
|
| 216 |
+
### Visual Consistency Learning
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
We further include ViCO as an additional training stage to integrate the *visual resolution router (ViR)* into InternVL3.5, thereby reducing the inference cost of InternVL3.5. The obtained efficient version of InternVL3.5 are termed as *InternVL3.5-Flash*. In particular, ViCO comprises two stages:
|
| 220 |
+
|
| 221 |
+
`Consistency training`:
|
| 222 |
+
In this stage, the entire model is trained to minimize the divergence between response distributions conditioned on visual tokens with different compression rates.
|
| 223 |
+
In practice, we introduce an extra reference model, which is frozen and initialized with InternVL3.5.
|
| 224 |
+
Given a sample, each image patch is represented as either 256 or 64 tokens, and the training objective is defined as follows:
|
| 225 |
+
|
| 226 |
+
|
| 227 |
+
$$
|
| 228 |
+
\mathcal{L}_\text{ViCO} =
|
| 229 |
+
\mathbb{E}_{\xi \sim \mathcal{R}} \Bigg[
|
| 230 |
+
\frac{1}{N} \sum_{i=1}^{N} \mathrm{KL} \Big(
|
| 231 |
+
\pi_{\theta_{ref}}\left(y_i \mid y_{<i}, I\right) \;\Big\|\;
|
| 232 |
+
\pi_{\theta_{policy}}\left(y_i \mid y_{<i}, I_\xi\right)
|
| 233 |
+
\Big)
|
| 234 |
+
\Bigg],
|
| 235 |
+
$$
|
| 236 |
+
|
| 237 |
+
where \\(\mathrm{KL}\) denotes the KL divergence and \(\xi\) denotes the compression rate, which is uniformly sampled from \(\{\frac{1}{4},\frac{1}{16}\}\). The image \(I_\xi\) is represented as 256 tokens when \(\xi=\frac{1}{4}\) and 64 tokens when \(\xi=\frac{1}{16}\). Notably, the reference model always performs inference with \(\xi=\frac{1}{4}\).
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
`Router training`:
|
| 241 |
+
This stage aims to train the ViR to select an appropriate trade-off resolution for different inputs.
|
| 242 |
+
ViR is formulated as a binary classifier and trained using standard cross-entropy loss.
|
| 243 |
+
To construct the route targets, we first compute the KL divergence between the model outputs conditioned on uncompressed visual tokens (i.e., 256 tokens per patch) and those conditioned on compressed visual tokens (i.e., 64 tokens per patch).
|
| 244 |
+
During this stage, the main MLLM (ViT, MLP and LLM) is kept frozen, and only the ViR is trained.
|
| 245 |
+
Specifically, we first compute the loss ratio for each patch:
|
| 246 |
+
|
| 247 |
+
$$
|
| 248 |
+
r_i = \frac{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{16}}\big)}{\mathcal{L}_\text{ViCO}\big(y_i \mid I_{\frac{1}{4}}\big)},
|
| 249 |
+
$$
|
| 250 |
+
|
| 251 |
+
which quantifies the relative increase in loss caused by compressing the visual tokens. Based on this ratio, the binary ground-truth label for the patch router is defined as:
|
| 252 |
+
|
| 253 |
+
$$
|
| 254 |
+
y_i^\text{router} =
|
| 255 |
+
\begin{cases}
|
| 256 |
+
0, & r_i < \tau \; \text{(compression has negligible impact)} \\
|
| 257 |
+
1, & r_i \ge \tau \; \text{(compression has significant impact)},
|
| 258 |
+
\end{cases}
|
| 259 |
+
$$
|
| 260 |
+
|
| 261 |
+
where \(y_i^{\text{router}}=0\) and \(y_i^{\text{router}}=1\) indicate that the compression rate \(\xi\) is set to \(\tfrac{1}{16}\) and \(\tfrac{1}{4}\), respectively.
|
| 262 |
+
|
| 263 |
+
> Please see [our paper](https://huggingface.co/papers/2508.18265) for more technical and experimental details.
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
### Test-Time Scaling
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
Test-time scaling (TTS) has been empirically demonstrated as an effective approach to enhance the reasoning capabilities of LLMs and MLLMs, particularly for complex tasks necessitating multi-step inference.
|
| 270 |
+
In this work, we implement a comprehensive test-time scaling approach that simultaneously improves reasoning depth (i.e., deep thinking) and breadth (i.e., parallel thinking).
|
| 271 |
+
|
| 272 |
+
`Deep Thinking`: By activating the Thinking mode, we guide the model to deliberately engage in step-by-step reasoning (i.e., decomposing complex problems into logical steps and validating intermediate conclusions) prior to generating the final answer. This approach systematically improves the logical structure of solutions for complex problems, particularly those requiring multi-step inference, and enhances reasoning depth.
|
| 273 |
+
|
| 274 |
+
`Parallel Thinking`: Following InternVL3, for reasoning tasks, we adopt the Best-of-N (BoN) strategy by employing [VisualPRM-v1.1](https://huggingface.co/OpenGVLab/VisualPRM-8B-v1_1) as the critic model to select the optimal response from multiple reasoning candidates.
|
| 275 |
+
This approach improves reasoning breadth.
|
| 276 |
+
|
| 277 |
+
> Notably, unless otherwise specified, the experimental results reported in our paper are obtained without applying TTS. Thus far, we have only applied TTS to reasoning benchmarks, since we found that the model already exhibits strong perception and understanding capabilities, and initiating TTS yields no significant improvement.
|
| 278 |
+
|
| 279 |
+
|
| 280 |
+
### Decoupled Vision-Language Deployment
|
| 281 |
+
|
| 282 |
+
In multimodal inference, the vision encoder and language model have distinct computational characteristics. The vision encoder that transforms images into semantic features is highly parallelizable and does not rely on long-term history state. In contrast, the language model adopts the inference in an autoregressive manner, which requires previous states to compute the next one. This sequential property makes the language part more sensitive to memory bandwidth and latency.
|
| 283 |
+
When MLLMs are deployed online at scale, the vision and language models often block each other, thus incurring additional inference cost. This effect becomes more pronounced with larger vision models or higher-resolution images.
|
| 284 |
+
|
| 285 |
+
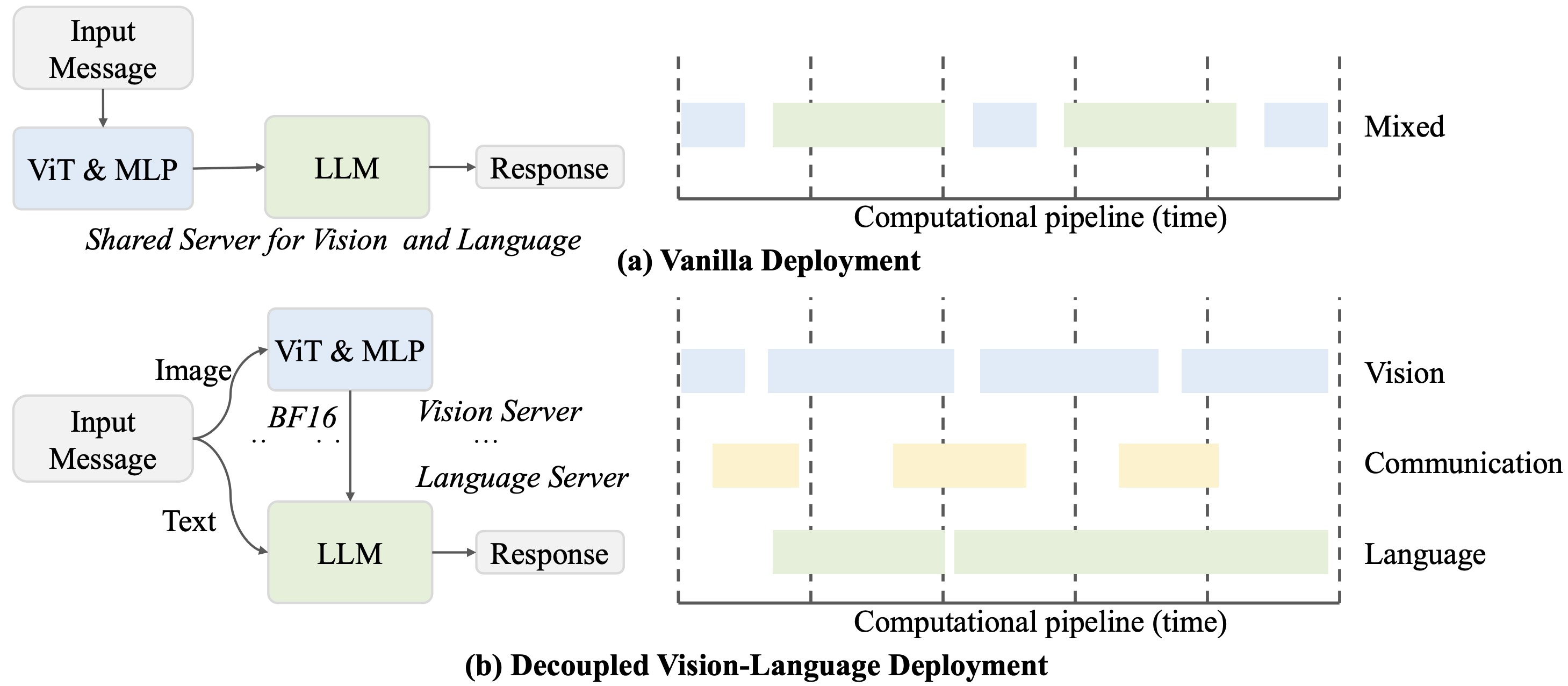
|
| 286 |
+
|
| 287 |
+
As shown in the Figure above, we propose decoupled vision-language deployment (DvD) to address this issue by separating vision and language processing, with a particular focus on optimizing the prefilling stage. The vision subsystem batches and processes images to produce compact feature embeddings, which are then transmitted to the language subsystem for fusion with the text context prior to decoding. This separation alleviates blocking and brings multimodal prefilling performance closer to that of pure language models.
|
| 288 |
+
In our system implementation, the ViT and MLP (and ViR for InternVL3.5-Flash) are deployed on the vision server, while the language server executes only the LLM. The communication is unidirectional, transmitting BF16 visual features over TCP, with RDMA optionally employed to achieve higher transmission speed. Vision processing, feature transmission, and language processing are organized into an asynchronous three-stage pipeline, enabling overlapped execution and minimizing pipeline stalls.
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
DvD increases GPU utilization and processing efficiency on the vision side, while enabling the language server to focus exclusively on the LLM’s prefilling and decoding without being blocked by vision computation. This design leads to improved throughput and responsiveness. Moreover, the architecture supports independent hardware cost optimization for the vision and language modules, and facilitates the seamless integration of new modules without requiring modifications to the language server deployment.
|
| 292 |
+
|
| 293 |
+
|
| 294 |
+
## Evaluation on Multimodal Capability
|
| 295 |
+
|
| 296 |
+
### Multimodal Reasoning and Mathematics
|
| 297 |
+
|
| 298 |
+

|
| 299 |
+
|
| 300 |
+
### OCR, Chart, and Document Understanding
|
| 301 |
+
|
| 302 |
+

|
| 303 |
+
|
| 304 |
+
### Multi-Image Understanding & Real-World Comprehension
|
| 305 |
+
|
| 306 |
+

|
| 307 |
+
|
| 308 |
+
### Comprehensive Multimodal Understanding & Multimodal Hallucination Evaluation
|
| 309 |
+
|
| 310 |
+

|
| 311 |
+
|
| 312 |
+
### Visual Grounding
|
| 313 |
+
|
| 314 |
+

|
| 315 |
+
|
| 316 |
+
### Multimodal Multilingual Understanding
|
| 317 |
+
|
| 318 |
+

|
| 319 |
+
|
| 320 |
+
### Video Understanding
|
| 321 |
+
|
| 322 |
+
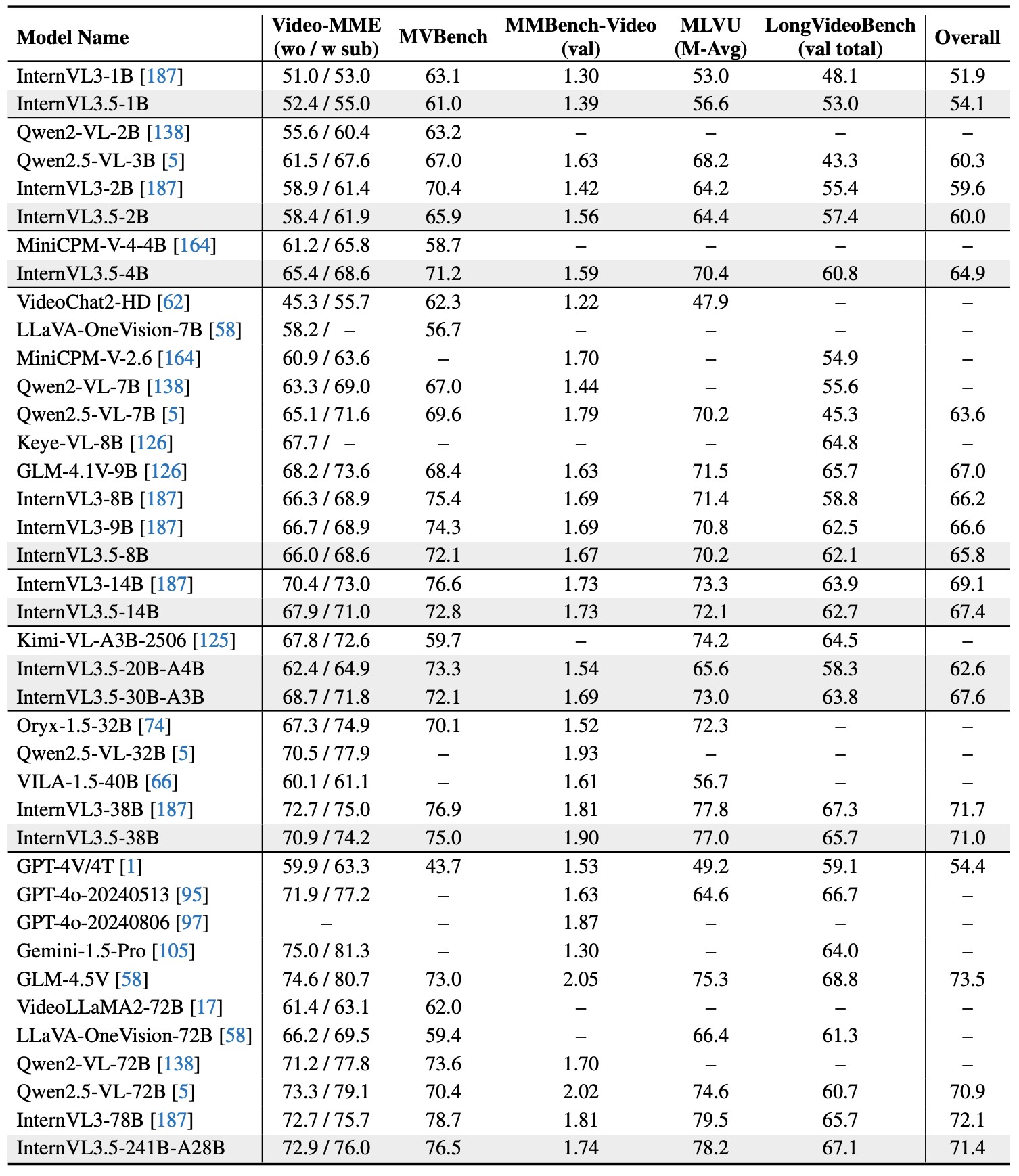
|
| 323 |
+
|
| 324 |
+
### GUI Tasks
|
| 325 |
+
|
| 326 |
+
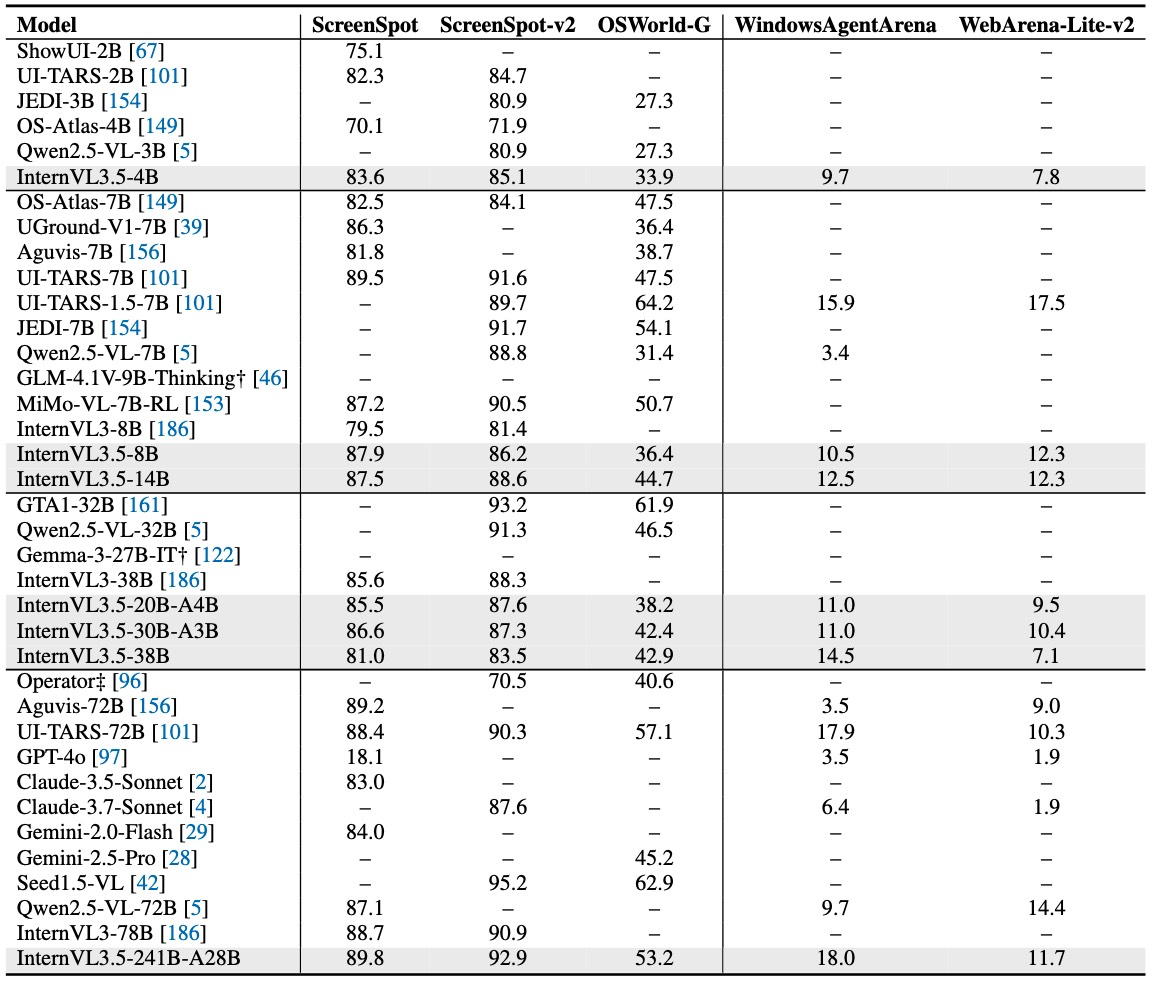
|
| 327 |
+
|
| 328 |
+
### Embodied Tasks
|
| 329 |
+
|
| 330 |
+
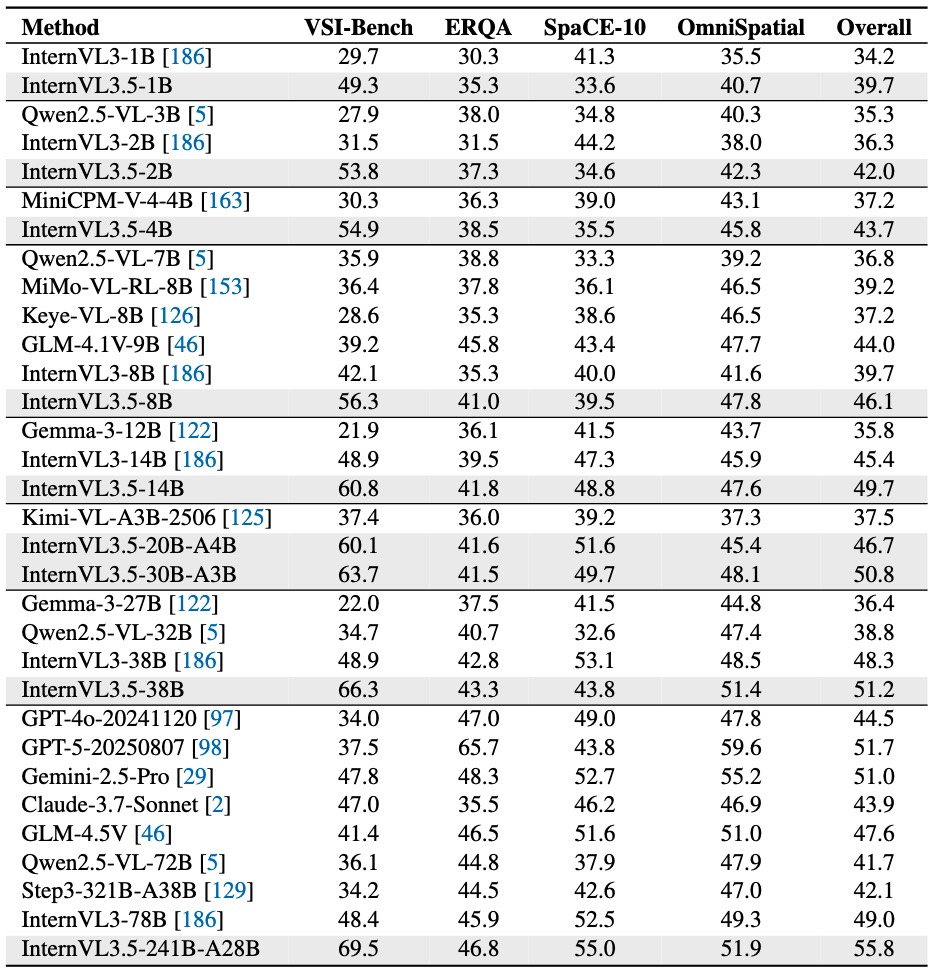
|
| 331 |
+
|
| 332 |
+
### SVG Tasks
|
| 333 |
+
|
| 334 |
+

|
| 335 |
+
|
| 336 |
+

|
| 337 |
+
|
| 338 |
+
## Evaluation on Language Capability
|
| 339 |
+
|
| 340 |
+

|
| 341 |
+
|
| 342 |
+
## Ablation Study
|
| 343 |
+
|
| 344 |
+
### Cascade Reinforcement Learning
|
| 345 |
+
|
| 346 |
+
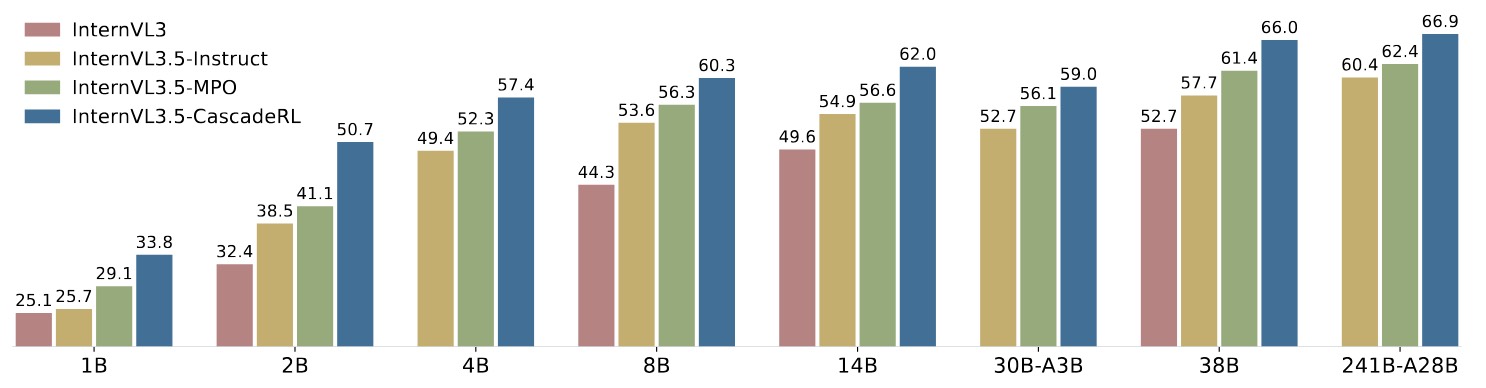
|
| 347 |
+
|
| 348 |
+
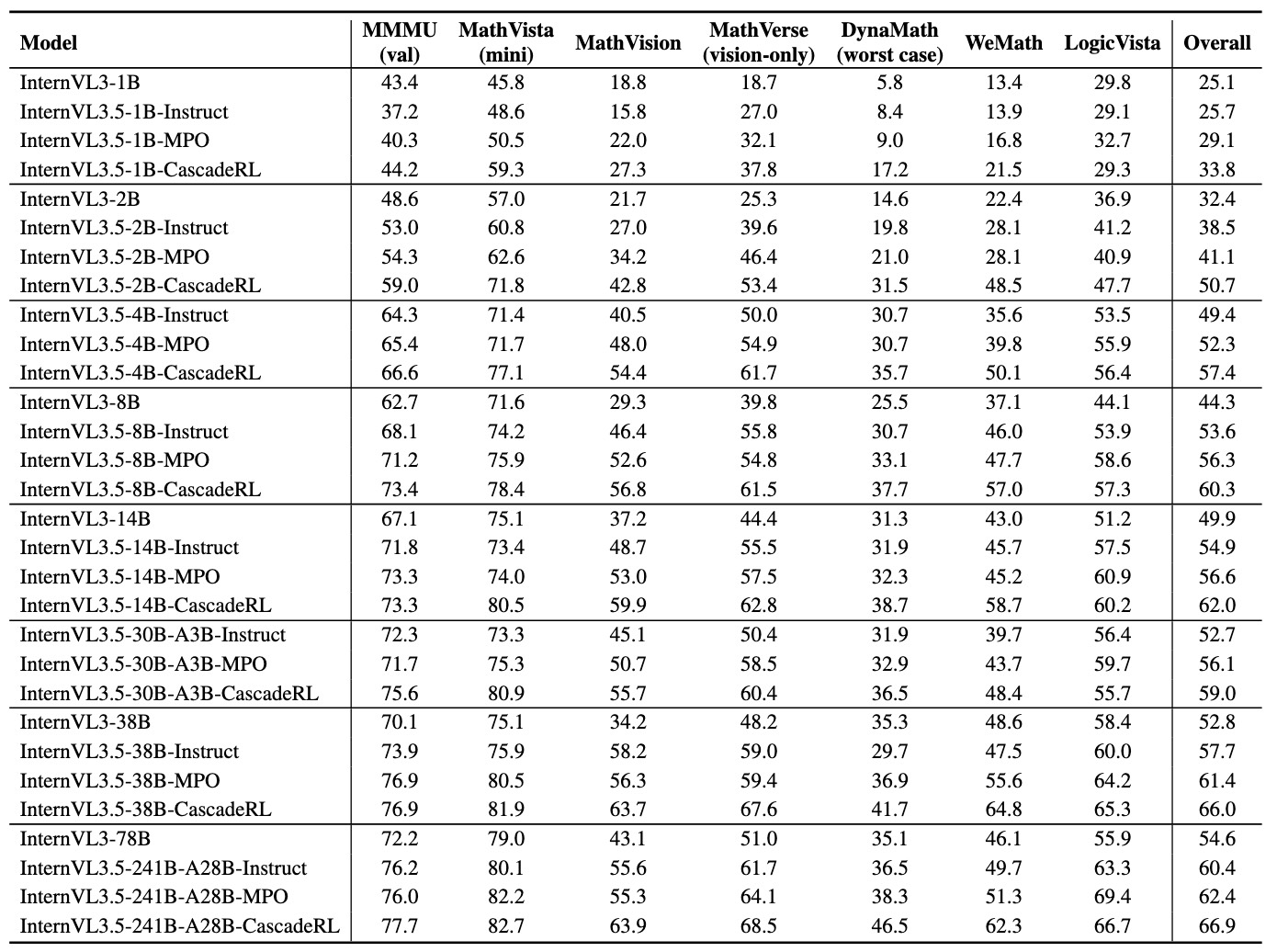
|
| 349 |
+
|
| 350 |
+
### Decoupled Vision-Language Deployment
|
| 351 |
+
|
| 352 |
+
|
| 353 |
+

|
| 354 |
+
|
| 355 |
+
## Quick Start
|
| 356 |
+
|
| 357 |
+
We provide an example code to run `InternVL3.5-8B` using `transformers`. Please note that our models with up to 30B parameters can be deployed on a single A100 GPU, while the 38B model requires two A100 GPUs and the 235B model requires eight A100 GPUs.
|
| 358 |
+
|
| 359 |
+
> In most cases, both [LMDeploy](https://github.com/InternLM/lmdeploy) and [vLLM](https://github.com/vllm-project/vllm) can be used for model deployment. However, for InternVL3.5-20B-A4B, we recommend using vLLM since lmdeploy has not yet supported GPT-OSS.
|
| 360 |
+
|
| 361 |
+
> Please use transformers>=4.52.1 to ensure the model works normally. For the 20B version of our model, transformers>=4.55.0 is required.
|
| 362 |
+
|
| 363 |
+
### Model Loading
|
| 364 |
+
|
| 365 |
+
#### 16-bit (bf16 / fp16)
|
| 366 |
+
|
| 367 |
+
```python
|
| 368 |
+
import torch
|
| 369 |
+
from transformers import AutoTokenizer, AutoModel
|
| 370 |
+
path = "OpenGVLab/InternVL3_5-8B"
|
| 371 |
+
model = AutoModel.from_pretrained(
|
| 372 |
+
path,
|
| 373 |
+
torch_dtype=torch.bfloat16,
|
| 374 |
+
low_cpu_mem_usage=True,
|
| 375 |
+
use_flash_attn=True,
|
| 376 |
+
trust_remote_code=True).eval().cuda()
|
| 377 |
+
```
|
| 378 |
+
|
| 379 |
+
#### BNB 8-bit Quantization
|
| 380 |
+
|
| 381 |
+
```python
|
| 382 |
+
import torch
|
| 383 |
+
from transformers import AutoTokenizer, AutoModel
|
| 384 |
+
path = "OpenGVLab/InternVL3_5-8B"
|
| 385 |
+
model = AutoModel.from_pretrained(
|
| 386 |
+
path,
|
| 387 |
+
torch_dtype=torch.bfloat16,
|
| 388 |
+
load_in_8bit=True,
|
| 389 |
+
low_cpu_mem_usage=True,
|
| 390 |
+
use_flash_attn=True,
|
| 391 |
+
trust_remote_code=True).eval()
|
| 392 |
+
```
|
| 393 |
+
|
| 394 |
+
#### Multiple GPUs
|
| 395 |
+
|
| 396 |
+
```python
|
| 397 |
+
import math
|
| 398 |
+
import torch
|
| 399 |
+
from transformers import AutoTokenizer, AutoModel
|
| 400 |
+
|
| 401 |
+
path = "OpenGVLab/InternVL3_5-8B"
|
| 402 |
+
model = AutoModel.from_pretrained(
|
| 403 |
+
path,
|
| 404 |
+
torch_dtype=torch.bfloat16,
|
| 405 |
+
low_cpu_mem_usage=True,
|
| 406 |
+
use_flash_attn=True,
|
| 407 |
+
trust_remote_code=True,
|
| 408 |
+
device_map="auto").eval()
|
| 409 |
+
```
|
| 410 |
+
|
| 411 |
+
### Thinking Mode
|
| 412 |
+
|
| 413 |
+
To enable thinking mode, please set the system prompt to our Thinking System Prompt. When enabling Thinking mode, we recommend setting `do_sample=True` and `temperature=0.6` to mitigate undesired repetition.
|
| 414 |
+
|
| 415 |
+
```python
|
| 416 |
+
R1_SYSTEM_PROMPT = """
|
| 417 |
+
You are an AI assistant that rigorously follows this response protocol:
|
| 418 |
+
|
| 419 |
+
1. First, conduct a detailed analysis of the question. Consider different angles, potential solutions, and reason through the problem step-by-step. Enclose this entire thinking process within <think> and </think> tags.
|
| 420 |
+
|
| 421 |
+
2. After the thinking section, provide a clear, concise, and direct answer to the user's question. Separate the answer from the think section with a newline.
|
| 422 |
+
|
| 423 |
+
Ensure that the thinking process is thorough but remains focused on the query. The final answer should be standalone and not reference the thinking section.
|
| 424 |
+
""".strip()
|
| 425 |
+
|
| 426 |
+
model.system_message = R1_SYSTEMP_PROMPT
|
| 427 |
+
```
|
| 428 |
+
|
| 429 |
+
### Inference with Transformers
|
| 430 |
+
|
| 431 |
+
```python
|
| 432 |
+
import math
|
| 433 |
+
import numpy as np
|
| 434 |
+
import torch
|
| 435 |
+
import torchvision.transforms as T
|
| 436 |
+
from decord import VideoReader, cpu
|
| 437 |
+
from PIL import Image
|
| 438 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 439 |
+
from transformers import AutoModel, AutoTokenizer
|
| 440 |
+
|
| 441 |
+
IMAGENET_MEAN = (0.485, 0.456, 0.406)
|
| 442 |
+
IMAGENET_STD = (0.229, 0.224, 0.225)
|
| 443 |
+
|
| 444 |
+
def build_transform(input_size):
|
| 445 |
+
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
|
| 446 |
+
transform = T.Compose([
|
| 447 |
+
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
|
| 448 |
+
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
|
| 449 |
+
T.ToTensor(),
|
| 450 |
+
T.Normalize(mean=MEAN, std=STD)
|
| 451 |
+
])
|
| 452 |
+
return transform
|
| 453 |
+
|
| 454 |
+
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
|
| 455 |
+
best_ratio_diff = float('inf')
|
| 456 |
+
best_ratio = (1, 1)
|
| 457 |
+
area = width * height
|
| 458 |
+
for ratio in target_ratios:
|
| 459 |
+
target_aspect_ratio = ratio[0] / ratio[1]
|
| 460 |
+
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
|
| 461 |
+
if ratio_diff < best_ratio_diff:
|
| 462 |
+
best_ratio_diff = ratio_diff
|
| 463 |
+
best_ratio = ratio
|
| 464 |
+
elif ratio_diff == best_ratio_diff:
|
| 465 |
+
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
|
| 466 |
+
best_ratio = ratio
|
| 467 |
+
return best_ratio
|
| 468 |
+
|
| 469 |
+
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
|
| 470 |
+
orig_width, orig_height = image.size
|
| 471 |
+
aspect_ratio = orig_width / orig_height
|
| 472 |
+
|
| 473 |
+
# calculate the existing image aspect ratio
|
| 474 |
+
target_ratios = set(
|
| 475 |
+
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
|
| 476 |
+
i * j <= max_num and i * j >= min_num)
|
| 477 |
+
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
|
| 478 |
+
|
| 479 |
+
# find the closest aspect ratio to the target
|
| 480 |
+
target_aspect_ratio = find_closest_aspect_ratio(
|
| 481 |
+
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
|
| 482 |
+
|
| 483 |
+
# calculate the target width and height
|
| 484 |
+
target_width = image_size * target_aspect_ratio[0]
|
| 485 |
+
target_height = image_size * target_aspect_ratio[1]
|
| 486 |
+
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
|
| 487 |
+
|
| 488 |
+
# resize the image
|
| 489 |
+
resized_img = image.resize((target_width, target_height))
|
| 490 |
+
processed_images = []
|
| 491 |
+
for i in range(blocks):
|
| 492 |
+
box = (
|
| 493 |
+
(i % (target_width // image_size)) * image_size,
|
| 494 |
+
(i // (target_width // image_size)) * image_size,
|
| 495 |
+
((i % (target_width // image_size)) + 1) * image_size,
|
| 496 |
+
((i // (target_width // image_size)) + 1) * image_size
|
| 497 |
+
)
|
| 498 |
+
# split the image
|
| 499 |
+
split_img = resized_img.crop(box)
|
| 500 |
+
processed_images.append(split_img)
|
| 501 |
+
assert len(processed_images) == blocks
|
| 502 |
+
if use_thumbnail and len(processed_images) != 1:
|
| 503 |
+
thumbnail_img = image.resize((image_size, image_size))
|
| 504 |
+
processed_images.append(thumbnail_img)
|
| 505 |
+
return processed_images
|
| 506 |
+
|
| 507 |
+
def load_image(image_file, input_size=448, max_num=12):
|
| 508 |
+
image = Image.open(image_file).convert('RGB')
|
| 509 |
+
transform = build_transform(input_size=input_size)
|
| 510 |
+
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 511 |
+
pixel_values = [transform(image) for image in images]
|
| 512 |
+
pixel_values = torch.stack(pixel_values)
|
| 513 |
+
return pixel_values
|
| 514 |
+
|
| 515 |
+
path = 'OpenGVLab/InternVL3_5-8B'
|
| 516 |
+
model = AutoModel.from_pretrained(
|
| 517 |
+
path,
|
| 518 |
+
torch_dtype=torch.bfloat16,
|
| 519 |
+
load_in_8bit=False,
|
| 520 |
+
low_cpu_mem_usage=True,
|
| 521 |
+
use_flash_attn=True,
|
| 522 |
+
trust_remote_code=True,
|
| 523 |
+
device_map="auto").eval()
|
| 524 |
+
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
|
| 525 |
+
|
| 526 |
+
# set the max number of tiles in `max_num`
|
| 527 |
+
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 528 |
+
generation_config = dict(max_new_tokens=1024, do_sample=True)
|
| 529 |
+
|
| 530 |
+
# pure-text conversation (纯文本对话)
|
| 531 |
+
question = 'Hello, who are you?'
|
| 532 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
|
| 533 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 534 |
+
|
| 535 |
+
question = 'Can you tell me a story?'
|
| 536 |
+
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
|
| 537 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 538 |
+
|
| 539 |
+
# single-image single-round conversation (单图单轮对话)
|
| 540 |
+
question = '<image>\nPlease describe the image shortly.'
|
| 541 |
+
response = model.chat(tokenizer, pixel_values, question, generation_config)
|
| 542 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 543 |
+
|
| 544 |
+
# single-image multi-round conversation (单图多轮对话)
|
| 545 |
+
question = '<image>\nPlease describe the image in detail.'
|
| 546 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
|
| 547 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 548 |
+
|
| 549 |
+
question = 'Please write a poem according to the image.'
|
| 550 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
|
| 551 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 552 |
+
|
| 553 |
+
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
|
| 554 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 555 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 556 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 557 |
+
|
| 558 |
+
question = '<image>\nDescribe the two images in detail.'
|
| 559 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 560 |
+
history=None, return_history=True)
|
| 561 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 562 |
+
|
| 563 |
+
question = 'What are the similarities and differences between these two images.'
|
| 564 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 565 |
+
history=history, return_history=True)
|
| 566 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 567 |
+
|
| 568 |
+
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
|
| 569 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 570 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 571 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 572 |
+
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
|
| 573 |
+
|
| 574 |
+
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
|
| 575 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 576 |
+
num_patches_list=num_patches_list,
|
| 577 |
+
history=None, return_history=True)
|
| 578 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 579 |
+
|
| 580 |
+
question = 'What are the similarities and differences between these two images.'
|
| 581 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 582 |
+
num_patches_list=num_patches_list,
|
| 583 |
+
history=history, return_history=True)
|
| 584 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 585 |
+
|
| 586 |
+
# batch inference, single image per sample (单图批处理)
|
| 587 |
+
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 588 |
+
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
|
| 589 |
+
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
|
| 590 |
+
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
|
| 591 |
+
|
| 592 |
+
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
|
| 593 |
+
responses = model.batch_chat(tokenizer, pixel_values,
|
| 594 |
+
num_patches_list=num_patches_list,
|
| 595 |
+
questions=questions,
|
| 596 |
+
generation_config=generation_config)
|
| 597 |
+
for question, response in zip(questions, responses):
|
| 598 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 599 |
+
|
| 600 |
+
# video multi-round conversation (视频多轮对话)
|
| 601 |
+
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
|
| 602 |
+
if bound:
|
| 603 |
+
start, end = bound[0], bound[1]
|
| 604 |
+
else:
|
| 605 |
+
start, end = -100000, 100000
|
| 606 |
+
start_idx = max(first_idx, round(start * fps))
|
| 607 |
+
end_idx = min(round(end * fps), max_frame)
|
| 608 |
+
seg_size = float(end_idx - start_idx) / num_segments
|
| 609 |
+
frame_indices = np.array([
|
| 610 |
+
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
|
| 611 |
+
for idx in range(num_segments)
|
| 612 |
+
])
|
| 613 |
+
return frame_indices
|
| 614 |
+
|
| 615 |
+
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
|
| 616 |
+
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
|
| 617 |
+
max_frame = len(vr) - 1
|
| 618 |
+
fps = float(vr.get_avg_fps())
|
| 619 |
+
|
| 620 |
+
pixel_values_list, num_patches_list = [], []
|
| 621 |
+
transform = build_transform(input_size=input_size)
|
| 622 |
+
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
|
| 623 |
+
for frame_index in frame_indices:
|
| 624 |
+
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
|
| 625 |
+
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 626 |
+
pixel_values = [transform(tile) for tile in img]
|
| 627 |
+
pixel_values = torch.stack(pixel_values)
|
| 628 |
+
num_patches_list.append(pixel_values.shape[0])
|
| 629 |
+
pixel_values_list.append(pixel_values)
|
| 630 |
+
pixel_values = torch.cat(pixel_values_list)
|
| 631 |
+
return pixel_values, num_patches_list
|
| 632 |
+
|
| 633 |
+
video_path = './examples/red-panda.mp4'
|
| 634 |
+
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
|
| 635 |
+
pixel_values = pixel_values.to(torch.bfloat16).cuda()
|
| 636 |
+
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
|
| 637 |
+
question = video_prefix + 'What is the red panda doing?'
|
| 638 |
+
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
|
| 639 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 640 |
+
num_patches_list=num_patches_list, history=None, return_history=True)
|
| 641 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 642 |
+
|
| 643 |
+
question = 'Describe this video in detail.'
|
| 644 |
+
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
|
| 645 |
+
num_patches_list=num_patches_list, history=history, return_history=True)
|
| 646 |
+
print(f'User: {question}\nAssistant: {response}')
|
| 647 |
+
```
|
| 648 |
+
|
| 649 |
+
#### Streaming Output
|
| 650 |
+
|
| 651 |
+
Besides this method, you can also use the following code to get streamed output.
|
| 652 |
+
|
| 653 |
+
```python
|
| 654 |
+
from transformers import TextIteratorStreamer
|
| 655 |
+
from threading import Thread
|
| 656 |
+
|
| 657 |
+
# Initialize the streamer
|
| 658 |
+
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
|
| 659 |
+
# Define the generation configuration
|
| 660 |
+
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
|
| 661 |
+
# Start the model chat in a separate thread
|
| 662 |
+
thread = Thread(target=model.chat, kwargs=dict(
|
| 663 |
+
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
|
| 664 |
+
history=None, return_history=False, generation_config=generation_config,
|
| 665 |
+
))
|
| 666 |
+
thread.start()
|
| 667 |
+
|
| 668 |
+
# Initialize an empty string to store the generated text
|
| 669 |
+
generated_text = ''
|
| 670 |
+
# Loop through the streamer to get the new text as it is generated
|
| 671 |
+
for new_text in streamer:
|
| 672 |
+
if new_text == model.conv_template.sep:
|
| 673 |
+
break
|
| 674 |
+
generated_text += new_text
|
| 675 |
+
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
|
| 676 |
+
```
|
| 677 |
+
|
| 678 |
+
## Finetune
|
| 679 |
+
|
| 680 |
+
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTuner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
|
| 681 |
+
|
| 682 |
+
## Deployment
|
| 683 |
+
|
| 684 |
+
### vLLM
|
| 685 |
+
|
| 686 |
+
vLLM is a high-throughput and memory-efficient inference and serving engine for LLMs and MLLMs.
|
| 687 |
+
Please refer to the [documentation](https://docs.vllm.ai/en/latest/examples/offline_inference/vision_language.html?h=internvl#vision-language) for how to deploy internvl series.
|
| 688 |
+
|
| 689 |
+
```sh
|
| 690 |
+
pip install vllm>=0.10.1
|
| 691 |
+
```
|
| 692 |
+
|
| 693 |
+
NOTE: Up to version 0.10.1.1, vLLM exhibits compatibility issues with GPT-OSS when applied in MLLMs. If you encounter any errors, please try replacing the `vllm/model_executor/models/gpt_oss.py` file with the following content:
|
| 694 |
+
|
| 695 |
+
```python
|
| 696 |
+
# SPDX-License-Identifier: Apache-2.0
|
| 697 |
+
# SPDX-FileCopyrightText: Copyright contributors to the vLLM project
|
| 698 |
+
from collections.abc import Iterable
|
| 699 |
+
from typing import Optional
|
| 700 |
+
|
| 701 |
+
import torch
|
| 702 |
+
import torch.distributed as dist
|
| 703 |
+
from torch import nn
|
| 704 |
+
from transformers import GptOssConfig
|
| 705 |
+
|
| 706 |
+
from vllm.attention import Attention, AttentionType
|
| 707 |
+
from vllm.compilation.decorators import support_torch_compile
|
| 708 |
+
from vllm.config import CacheConfig, VllmConfig
|
| 709 |
+
from vllm.distributed import (get_ep_group, get_tensor_model_parallel_rank, get_pp_group,
|
| 710 |
+
get_tensor_model_parallel_world_size)
|
| 711 |
+
from vllm.model_executor.layers.fused_moe import FusedMoE
|
| 712 |
+
from vllm.model_executor.layers.layernorm import RMSNorm
|
| 713 |
+
from vllm.model_executor.layers.linear import (QKVParallelLinear,
|
| 714 |
+
RowParallelLinear)
|
| 715 |
+
from vllm.model_executor.layers.logits_processor import LogitsProcessor
|
| 716 |
+
from vllm.model_executor.layers.quantization import QuantizationConfig
|
| 717 |
+
from vllm.model_executor.layers.rotary_embedding import get_rope
|
| 718 |
+
from vllm.model_executor.layers.vocab_parallel_embedding import (
|
| 719 |
+
ParallelLMHead, VocabParallelEmbedding)
|
| 720 |
+
from vllm.model_executor.model_loader.weight_utils import default_weight_loader
|
| 721 |
+
from vllm.model_executor.sampling_metadata import SamplingMetadata
|
| 722 |
+
from vllm.sequence import IntermediateTensors
|
| 723 |
+
from vllm.utils import cdiv
|
| 724 |
+
|
| 725 |
+
from .utils import (extract_layer_index,
|
| 726 |
+
make_empty_intermediate_tensors_factory,
|
| 727 |
+
maybe_prefix)
|
| 728 |
+
|
| 729 |
+
class OAIAttention(nn.Module):
|
| 730 |
+
|
| 731 |
+
def __init__(
|
| 732 |
+
self,
|
| 733 |
+
config: GptOssConfig,
|
| 734 |
+
quant_config: Optional[QuantizationConfig] = None,
|
| 735 |
+
cache_config: Optional[CacheConfig] = None,
|
| 736 |
+
prefix: str = "",
|
| 737 |
+
):
|
| 738 |
+
super().__init__()
|
| 739 |
+
self.layer_idx = extract_layer_index(prefix)
|
| 740 |
+
self.head_dim = config.head_dim
|
| 741 |
+
self.num_attention_heads = config.num_attention_heads
|
| 742 |
+
self.num_key_value_heads = config.num_key_value_heads
|
| 743 |
+
self.hidden_size = config.hidden_size
|
| 744 |
+
|
| 745 |
+
self.rotary_emb = get_rope(
|
| 746 |
+
self.head_dim,
|
| 747 |
+
rotary_dim=self.head_dim,
|
| 748 |
+
max_position=config.max_position_embeddings,
|
| 749 |
+
base=config.rope_theta,
|
| 750 |
+
dtype=torch.float32,
|
| 751 |
+
rope_scaling={
|
| 752 |
+
"rope_type":
|
| 753 |
+
"yarn",
|
| 754 |
+
"factor":
|
| 755 |
+
config.rope_scaling["factor"],
|
| 756 |
+
"original_max_position_embeddings":
|
| 757 |
+
config.rope_scaling["original_max_position_embeddings"],
|
| 758 |
+
"beta_fast":
|
| 759 |
+
config.rope_scaling["beta_fast"],
|
| 760 |
+
"beta_slow":
|
| 761 |
+
config.rope_scaling["beta_slow"],
|
| 762 |
+
},
|
| 763 |
+
is_neox_style=True,
|
| 764 |
+
)
|
| 765 |
+
|
| 766 |
+
tp_size = get_tensor_model_parallel_world_size()
|
| 767 |
+
|
| 768 |
+
self.sinks = torch.nn.Parameter(
|
| 769 |
+
torch.empty(config.num_attention_heads // tp_size,
|
| 770 |
+
dtype=torch.bfloat16,
|
| 771 |
+
requires_grad=False))
|
| 772 |
+
|
| 773 |
+
self.norm = RMSNorm(config.hidden_size, eps=1e-5)
|
| 774 |
+
|
| 775 |
+
self.q_size = self.num_attention_heads * self.head_dim // tp_size
|
| 776 |
+
self.kv_size = self.num_key_value_heads * self.head_dim // tp_size
|
| 777 |
+
self.scaling = self.head_dim**-0.5
|
| 778 |
+
self.rope_theta = config.rope_theta
|
| 779 |
+
|
| 780 |
+
self.qkv = QKVParallelLinear(
|
| 781 |
+
hidden_size=self.hidden_size,
|
| 782 |
+
head_size=self.head_dim,
|
| 783 |
+
total_num_heads=self.num_attention_heads,
|
| 784 |
+
total_num_kv_heads=self.num_key_value_heads,
|
| 785 |
+
quant_config=quant_config,
|
| 786 |
+
prefix=f"{prefix}.qkv_proj",
|
| 787 |
+
)
|
| 788 |
+
|
| 789 |
+
self.o_proj = RowParallelLinear(
|
| 790 |
+
input_size=self.num_attention_heads * self.head_dim,
|
| 791 |
+
output_size=self.hidden_size,
|
| 792 |
+
quant_config=quant_config,
|
| 793 |
+
prefix=f"{prefix}.o_proj",
|
| 794 |
+
)
|
| 795 |
+
|
| 796 |
+
self.num_local_attention_heads = config.num_attention_heads // tp_size
|
| 797 |
+
self.num_local_key_value_heads = config.num_key_value_heads // tp_size
|
| 798 |
+
|
| 799 |
+
# Only apply sliding window to every other layer
|
| 800 |
+
sliding_window = (config.sliding_window if self.layer_idx %
|
| 801 |
+
2 == 0 else None)
|
| 802 |
+
self.attn = Attention(
|
| 803 |
+
self.num_local_attention_heads,
|
| 804 |
+
self.head_dim,
|
| 805 |
+
self.scaling,
|
| 806 |
+
num_kv_heads=self.num_local_key_value_heads,
|
| 807 |
+
cache_config=cache_config,
|
| 808 |
+
quant_config=quant_config,
|
| 809 |
+
per_layer_sliding_window=sliding_window,
|
| 810 |
+
attn_type=AttentionType.DECODER,
|
| 811 |
+
prefix=f"{prefix}.attn",
|
| 812 |
+
sinks=self.sinks,
|
| 813 |
+
)
|
| 814 |
+
|
| 815 |
+
def forward(self, hidden_states: torch.Tensor,
|
| 816 |
+
positions: torch.Tensor) -> torch.Tensor:
|
| 817 |
+
t = self.norm(hidden_states)
|
| 818 |
+
|
| 819 |
+
qkv, _ = self.qkv(t)
|
| 820 |
+
q, k, v = qkv.split([self.q_size, self.kv_size, self.kv_size], dim=-1)
|
| 821 |
+
q, k = self.rotary_emb(positions, q, k)
|
| 822 |
+
v = v.contiguous()
|
| 823 |
+
attn_output = self.attn(q, k, v)
|
| 824 |
+
output, _ = self.o_proj(attn_output)
|
| 825 |
+
|
| 826 |
+
return output + hidden_states
|
| 827 |
+
|
| 828 |
+
|
| 829 |
+
class MLPBlock(torch.nn.Module):
|
| 830 |
+
|
| 831 |
+
def __init__(
|
| 832 |
+
self,
|
| 833 |
+
config: GptOssConfig,
|
| 834 |
+
layer_idx: int,
|
| 835 |
+
quant_config: QuantizationConfig,
|
| 836 |
+
prefix: str = "",
|
| 837 |
+
):
|
| 838 |
+
super().__init__()
|
| 839 |
+
self.layer_idx = layer_idx
|
| 840 |
+
self.num_experts = config.num_local_experts
|
| 841 |
+
self.experts_per_token = config.num_experts_per_tok
|
| 842 |
+
# self.world_size = dist.get_world_size() if dist.is_initialized() else 1
|
| 843 |
+
self.norm = RMSNorm(config.hidden_size, eps=1e-5)
|
| 844 |
+
self.router = torch.nn.Linear(config.hidden_size,
|
| 845 |
+
config.num_local_experts,
|
| 846 |
+
dtype=torch.bfloat16)
|
| 847 |
+
# assert config.intermediate_size % self.world_size == 0
|
| 848 |
+
self.experts = FusedMoE(num_experts=config.num_local_experts,
|
| 849 |
+
top_k=config.num_experts_per_tok,
|
| 850 |
+
hidden_size=config.hidden_size,
|
| 851 |
+
intermediate_size=config.intermediate_size,
|
| 852 |
+
reduce_results=True,
|
| 853 |
+
renormalize=True,
|
| 854 |
+
quant_config=quant_config,
|
| 855 |
+
prefix=f"{prefix}.experts",
|
| 856 |
+
apply_router_weight_on_input=False,
|
| 857 |
+
has_bias=True,
|
| 858 |
+
activation="swigluoai")
|
| 859 |
+
|
| 860 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 861 |
+
t = self.norm(x)
|
| 862 |
+
g = self.router(t)
|
| 863 |
+
t = self.experts(hidden_states=t, router_logits=g)
|
| 864 |
+
return x + t
|
| 865 |
+
|
| 866 |
+
|
| 867 |
+
class TransformerBlock(torch.nn.Module):
|
| 868 |
+
|
| 869 |
+
def __init__(
|
| 870 |
+
self,
|
| 871 |
+
config: GptOssConfig,
|
| 872 |
+
quant_config: QuantizationConfig,
|
| 873 |
+
prefix: str = "",
|
| 874 |
+
):
|
| 875 |
+
super().__init__()
|
| 876 |
+
self.layer_idx = extract_layer_index(prefix)
|
| 877 |
+
self.attn = OAIAttention(config, prefix=f"{prefix}.attn")
|
| 878 |
+
self.mlp = MLPBlock(config,
|
| 879 |
+
self.layer_idx,
|
| 880 |
+
quant_config=quant_config,
|
| 881 |
+
prefix=f"{prefix}.mlp")
|
| 882 |
+
|
| 883 |
+
def forward(self, hidden_states: torch.Tensor,
|
| 884 |
+
positions: torch.Tensor) -> torch.Tensor:
|
| 885 |
+
attn_output = self.attn(hidden_states, positions)
|
| 886 |
+
output = self.mlp(attn_output)
|
| 887 |
+
return output
|
| 888 |
+
|
| 889 |
+
|
| 890 |
+
@support_torch_compile
|
| 891 |
+
class GptOssModel(nn.Module):
|
| 892 |
+
|
| 893 |
+
def __init__(
|
| 894 |
+
self,
|
| 895 |
+
*,
|
| 896 |
+
vllm_config: VllmConfig,
|
| 897 |
+
prefix: str = "",
|
| 898 |
+
):
|
| 899 |
+
super().__init__()
|
| 900 |
+
self.config = vllm_config.model_config.hf_config
|
| 901 |
+
self.quant_config = vllm_config.quant_config
|
| 902 |
+
self.config.hidden_size = self.config.hidden_size
|
| 903 |
+
self.embedding = VocabParallelEmbedding(
|
| 904 |
+
self.config.vocab_size,
|
| 905 |
+
self.config.hidden_size,
|
| 906 |
+
)
|
| 907 |
+
self.layers = torch.nn.ModuleList([
|
| 908 |
+
TransformerBlock(
|
| 909 |
+
self.config,
|
| 910 |
+
quant_config=self.quant_config,
|
| 911 |
+
prefix=maybe_prefix(prefix, f"block.{layer_idx}"),
|
| 912 |
+
) for layer_idx in range(self.config.num_hidden_layers)
|
| 913 |
+
])
|
| 914 |
+
self.norm = RMSNorm(self.config.hidden_size, eps=1e-5)
|
| 915 |
+
self.make_empty_intermediate_tensors = (
|
| 916 |
+
make_empty_intermediate_tensors_factory(
|
| 917 |
+
["hidden_states", "residual"], self.config.hidden_size))
|
| 918 |
+
def forward(self, input_ids: torch.Tensor,
|
| 919 |
+
positions: torch.Tensor,
|
| 920 |
+
intermediate_tensors: Optional[IntermediateTensors] = None,
|
| 921 |
+
inputs_embeds: Optional[torch.Tensor] = None,) -> torch.Tensor:
|
| 922 |
+
if get_pp_group().is_first_rank:
|
| 923 |
+
if inputs_embeds is not None:
|
| 924 |
+
hidden_states = inputs_embeds
|
| 925 |
+
else:
|
| 926 |
+
# hidden_states = self.get_input_embeddings(input_ids)
|
| 927 |
+
hidden_states = self.embedding(input_ids)
|
| 928 |
+
|
| 929 |
+
residual = None
|
| 930 |
+
else:
|
| 931 |
+
assert intermediate_tensors is not None
|
| 932 |
+
hidden_states = intermediate_tensors["hidden_states"]
|
| 933 |
+
residual = intermediate_tensors["residual"]
|
| 934 |
+
# x = self.embedding(input_ids)
|
| 935 |
+
# for layer in self.layers:
|
| 936 |
+
# x = layer(x, positions)
|
| 937 |
+
# x = self.norm(x)
|
| 938 |
+
for layer in self.layers:
|
| 939 |
+
hidden_states = layer(hidden_states, positions)
|
| 940 |
+
hidden_states = self.norm(hidden_states)
|
| 941 |
+
return hidden_states
|
| 942 |
+
|
| 943 |
+
|
| 944 |
+
class GptOssForCausalLM(nn.Module):
|
| 945 |
+
|
| 946 |
+
def __init__(
|
| 947 |
+
self,
|
| 948 |
+
vllm_config: VllmConfig,
|
| 949 |
+
prefix: str = "",
|
| 950 |
+
):
|
| 951 |
+
super().__init__()
|
| 952 |
+
self.vllm_config = vllm_config
|
| 953 |
+
self.model_config = vllm_config.model_config.hf_config
|
| 954 |
+
self.model = GptOssModel(
|
| 955 |
+
vllm_config=vllm_config,
|
| 956 |
+
prefix=maybe_prefix(prefix, "model"),
|
| 957 |
+
)
|
| 958 |
+
self.lm_head = ParallelLMHead(
|
| 959 |
+
self.model_config.vocab_size,
|
| 960 |
+
self.model_config.hidden_size,
|
| 961 |
+
)
|
| 962 |
+
self.logits_processor = LogitsProcessor(self.model_config.vocab_size)
|
| 963 |
+
self.make_empty_intermediate_tensors = (
|
| 964 |
+
self.model.make_empty_intermediate_tensors)
|
| 965 |
+
def forward(self,
|
| 966 |
+
input_ids: torch.Tensor,
|
| 967 |
+
positions: torch.Tensor,
|
| 968 |
+
intermediate_tensors: Optional[IntermediateTensors] = None,
|
| 969 |
+
inputs_embeds: Optional[torch.Tensor] = None) -> torch.Tensor:
|
| 970 |
+
assert intermediate_tensors is None
|
| 971 |
+
assert inputs_embeds is None
|
| 972 |
+
return self.model(input_ids, positions)
|
| 973 |
+
|
| 974 |
+
def compute_logits(self, hidden_states: torch.Tensor,
|
| 975 |
+
sampling_metadata: SamplingMetadata) -> torch.Tensor:
|
| 976 |
+
logits = self.logits_processor(self.lm_head, hidden_states,
|
| 977 |
+
sampling_metadata)
|
| 978 |
+
return logits
|
| 979 |
+
|
| 980 |
+
def get_input_embeddings(self, input_ids: torch.Tensor) -> torch.Tensor:
|
| 981 |
+
return self.model.embedding(input_ids)
|
| 982 |
+
|
| 983 |
+
def _load_weights_mxfp4(
|
| 984 |
+
self, weights: Iterable[tuple[str, torch.Tensor]]) -> set[str]:
|
| 985 |
+
rename_mapping = {
|
| 986 |
+
"self_attn": "attn",
|
| 987 |
+
"input_layernorm.weight": "attn.norm.weight",
|
| 988 |
+
"post_attention_layernorm.weight": "mlp.norm.weight",
|
| 989 |
+
"embed_tokens": "embedding",
|
| 990 |
+
}
|
| 991 |
+
|
| 992 |
+
def maybe_rename(name: str) -> str:
|
| 993 |
+
for remap_name, new_name in rename_mapping.items():
|
| 994 |
+
if remap_name in name:
|
| 995 |
+
return name.replace(remap_name, new_name)
|
| 996 |
+
return name
|
| 997 |
+
|
| 998 |
+
params_dict = dict(self.named_parameters())
|
| 999 |
+
loaded_params: set[str] = set()
|
| 1000 |
+
mxfp4_block = 32
|
| 1001 |
+
|
| 1002 |
+
tp_rank = get_tensor_model_parallel_rank()
|
| 1003 |
+
tp_size = get_tensor_model_parallel_world_size()
|
| 1004 |
+
intermediate_size = self.model_config.intermediate_size
|
| 1005 |
+
intermediate_size_block = intermediate_size // mxfp4_block
|
| 1006 |
+
per_rank_intermediate_size_block = cdiv(intermediate_size_block,
|
| 1007 |
+
tp_size)
|
| 1008 |
+
per_rank_intermediate_size = (per_rank_intermediate_size_block *
|
| 1009 |
+
mxfp4_block)
|
| 1010 |
+
|
| 1011 |
+
# Calculate common slicing bounds for current rank
|
| 1012 |
+
tp_rank_start = tp_rank * per_rank_intermediate_size
|
| 1013 |
+
tp_rank_end = min((tp_rank + 1) * per_rank_intermediate_size,
|
| 1014 |
+
intermediate_size)
|
| 1015 |
+
|
| 1016 |
+
# Attention heads per rank
|
| 1017 |
+
heads_per_rank = self.model_config.num_attention_heads // tp_size
|
| 1018 |
+
head_start = tp_rank * heads_per_rank
|
| 1019 |
+
|
| 1020 |
+
use_ep = self.vllm_config.parallel_config.enable_expert_parallel
|
| 1021 |
+
ep_size = get_ep_group().world_size
|
| 1022 |
+
ep_rank = get_ep_group().rank
|
| 1023 |
+
num_experts = self.model_config.num_local_experts
|
| 1024 |
+
experts_per_rank = num_experts // ep_size
|
| 1025 |
+
ep_rank_start = ep_rank * experts_per_rank
|
| 1026 |
+
ep_rank_end = (ep_rank + 1) * experts_per_rank
|
| 1027 |
+
|
| 1028 |
+
for name, weight in weights:
|
| 1029 |
+
# FIXME(woosuk): Remove this after testing.
|
| 1030 |
+
weight = weight.cuda()
|
| 1031 |
+
|
| 1032 |
+
if "gate_up_proj_blocks" in name:
|
| 1033 |
+
# Handle MLP gate and up projection weights
|
| 1034 |
+
new_name = name.replace("gate_up_proj_blocks", "w13_weight")
|
| 1035 |
+
|
| 1036 |
+
# flat weight from (E, 2 * N, block_size, entry_per_block)
|
| 1037 |
+
# to (E, 2 * N, -1), shouldn't trigger copy for contiguous
|
| 1038 |
+
weight = weight.view(num_experts, 2 * intermediate_size,
|
| 1039 |
+
-1).contiguous()
|
| 1040 |
+
|
| 1041 |
+
# Extract gate and up projection parts
|
| 1042 |
+
# since the weight is shuffled, we can slice directly
|
| 1043 |
+
if use_ep:
|
| 1044 |
+
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
|
| 1045 |
+
else:
|
| 1046 |
+
narrow_weight = weight[:,
|
| 1047 |
+
2 * tp_rank_start:2 * tp_rank_end,
|
| 1048 |
+
...]
|
| 1049 |
+
|
| 1050 |
+
param = params_dict[new_name]
|
| 1051 |
+
weight_loader = getattr(param, "weight_loader",
|
| 1052 |
+
default_weight_loader)
|
| 1053 |
+
weight_loader(param,
|
| 1054 |
+
narrow_weight,
|
| 1055 |
+
weight_name=new_name,
|
| 1056 |
+
shard_id=None,
|
| 1057 |
+
expert_id=None)
|
| 1058 |
+
loaded_params.add(new_name)
|
| 1059 |
+
|
| 1060 |
+
elif "down_proj_blocks" in name:
|
| 1061 |
+
# Handle MLP down projection weights
|
| 1062 |
+
new_name = name.replace("down_proj_blocks", "w2_weight")
|
| 1063 |
+
# same flatten here, but since 2 mx4 value are packed in 1
|
| 1064 |
+
# uint8, divide by 2
|
| 1065 |
+
weight = weight.view(num_experts, -1,
|
| 1066 |
+
intermediate_size // 2).contiguous()
|
| 1067 |
+
if use_ep:
|
| 1068 |
+
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
|
| 1069 |
+
else:
|
| 1070 |
+
narrow_weight = weight[...,
|
| 1071 |
+
tp_rank_start // 2:tp_rank_end // 2]
|
| 1072 |
+
|
| 1073 |
+
param = params_dict[new_name]
|
| 1074 |
+
weight_loader = getattr(param, "weight_loader",
|
| 1075 |
+
default_weight_loader)
|
| 1076 |
+
weight_loader(param,
|
| 1077 |
+
narrow_weight,
|
| 1078 |
+
weight_name=new_name,
|
| 1079 |
+
shard_id=None,
|
| 1080 |
+
expert_id=None)
|
| 1081 |
+
loaded_params.add(new_name)
|
| 1082 |
+
|
| 1083 |
+
elif "gate_up_proj_scales" in name:
|
| 1084 |
+
# Handle MLP gate and up projection weights scale
|
| 1085 |
+
new_name = name.replace("gate_up_proj_scales",
|
| 1086 |
+
"w13_weight_scale")
|
| 1087 |
+
if use_ep:
|
| 1088 |
+
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
|
| 1089 |
+
else:
|
| 1090 |
+
narrow_weight = weight[:,
|
| 1091 |
+
2 * tp_rank_start:2 * tp_rank_end,
|
| 1092 |
+
...]
|
| 1093 |
+
|
| 1094 |
+
param = params_dict[new_name]
|
| 1095 |
+
weight_loader = getattr(param, "weight_loader",
|
| 1096 |
+
default_weight_loader)
|
| 1097 |
+
weight_loader(param,
|
| 1098 |
+
narrow_weight,
|
| 1099 |
+
weight_name=new_name,
|
| 1100 |
+
shard_id=None,
|
| 1101 |
+
expert_id=None)
|
| 1102 |
+
loaded_params.add(new_name)
|
| 1103 |
+
|
| 1104 |
+
elif "down_proj_scales" in name:
|
| 1105 |
+
# Handle MLP down projection weights
|
| 1106 |
+
new_name = name.replace("down_proj_scales", "w2_weight_scale")
|
| 1107 |
+
if use_ep:
|
| 1108 |
+
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
|
| 1109 |
+
else:
|
| 1110 |
+
narrow_weight = weight[..., tp_rank_start //
|
| 1111 |
+
mxfp4_block:tp_rank_end //
|
| 1112 |
+
mxfp4_block]
|
| 1113 |
+
|
| 1114 |
+
param = params_dict[new_name]
|
| 1115 |
+
weight_loader = getattr(param, "weight_loader",
|
| 1116 |
+
default_weight_loader)
|
| 1117 |
+
weight_loader(param,
|
| 1118 |
+
narrow_weight,
|
| 1119 |
+
weight_name=new_name,
|
| 1120 |
+
shard_id=None,
|
| 1121 |
+
expert_id=None)
|
| 1122 |
+
loaded_params.add(new_name)
|
| 1123 |
+
elif "gate_up_proj_bias" in name:
|
| 1124 |
+
# Handle MLP gate and up projection biases
|
| 1125 |
+
new_name = name.replace("gate_up_proj_bias", "w13_bias")
|
| 1126 |
+
|
| 1127 |
+
# Extract gate and up projection bias parts
|
| 1128 |
+
if use_ep:
|
| 1129 |
+
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
|
| 1130 |
+
else:
|
| 1131 |
+
narrow_weight = weight[:,
|
| 1132 |
+
2 * tp_rank_start:2 * tp_rank_end]
|
| 1133 |
+
|
| 1134 |
+
param = params_dict[new_name]
|
| 1135 |
+
weight_loader = getattr(param, "weight_loader",
|
| 1136 |
+
default_weight_loader)
|
| 1137 |
+
weight_loader(param,
|
| 1138 |
+
narrow_weight,
|
| 1139 |
+
weight_name=new_name,
|
| 1140 |
+
shard_id=None,
|
| 1141 |
+
expert_id=None)
|
| 1142 |
+
loaded_params.add(new_name)
|
| 1143 |
+
|
| 1144 |
+
elif "down_proj_bias" in name:
|
| 1145 |
+
# Handle MLP down projection bias
|
| 1146 |
+
new_name = name.replace("down_proj_bias", "w2_bias")
|
| 1147 |
+
param = params_dict[new_name]
|
| 1148 |
+
weight_loader = getattr(param, "weight_loader",
|
| 1149 |
+
default_weight_loader)
|
| 1150 |
+
if use_ep:
|
| 1151 |
+
weight = weight[ep_rank_start:ep_rank_end, ...]
|
| 1152 |
+
else:
|
| 1153 |
+
# (only load on rank 0 to avoid duplication)
|
| 1154 |
+
if tp_rank != 0:
|
| 1155 |
+
weight.zero_()
|
| 1156 |
+
weight_loader(param,
|
| 1157 |
+
weight,
|
| 1158 |
+
weight_name=new_name,
|
| 1159 |
+
shard_id=None,
|
| 1160 |
+
expert_id=None)
|
| 1161 |
+
loaded_params.add(new_name)
|
| 1162 |
+
elif "sinks" in name:
|
| 1163 |
+
# Handle attention sinks (distributed across ranks)
|
| 1164 |
+
name = name.replace("self_attn", "attn")
|
| 1165 |
+
param = params_dict[name]
|
| 1166 |
+
narrow_weight = weight.narrow(0, head_start, heads_per_rank)
|
| 1167 |
+
param.data.copy_(narrow_weight)
|
| 1168 |
+
loaded_params.add(name)
|
| 1169 |
+
elif "q_proj" in name or "k_proj" in name or "v_proj" in name:
|
| 1170 |
+
shard_id = ("q" if "q_proj" in name else
|
| 1171 |
+
"k" if "k_proj" in name else "v")
|
| 1172 |
+
name = name.replace("self_attn", "attn")
|
| 1173 |
+
param_name = name.replace(f"{shard_id}_proj", "qkv")
|
| 1174 |
+
param = params_dict[param_name]
|
| 1175 |
+
weight_loader = param.weight_loader
|
| 1176 |
+
weight_loader(param, weight, loaded_shard_id=shard_id)
|
| 1177 |
+
loaded_params.add(param_name)
|
| 1178 |
+
else:
|
| 1179 |
+
# Handle all other weights with potential renaming
|
| 1180 |
+
renamed_name = maybe_rename(name)
|
| 1181 |
+
if renamed_name not in params_dict:
|
| 1182 |
+
continue
|
| 1183 |
+
param = params_dict[renamed_name]
|
| 1184 |
+
weight_loader = getattr(param, "weight_loader",
|
| 1185 |
+
default_weight_loader)
|
| 1186 |
+
weight_loader(param, weight)
|
| 1187 |
+
loaded_params.add(renamed_name)
|
| 1188 |
+
|
| 1189 |
+
return loaded_params
|
| 1190 |
+
|
| 1191 |
+
def _load_weights_other(
|
| 1192 |
+
self, weights: Iterable[tuple[str, torch.Tensor]]) -> set[str]:
|
| 1193 |
+
rename_mapping = {
|
| 1194 |
+
"self_attn": "attn",
|
| 1195 |
+
"input_layernorm.weight": "attn.norm.weight",
|
| 1196 |
+
"post_attention_layernorm.weight": "mlp.norm.weight",
|
| 1197 |
+
"embed_tokens": "embedding",
|
| 1198 |
+
}
|
| 1199 |
+
|
| 1200 |
+
def maybe_rename(name: str) -> str:
|
| 1201 |
+
for remap_name, new_name in rename_mapping.items():
|
| 1202 |
+
if remap_name in name:
|
| 1203 |
+
return name.replace(remap_name, new_name)
|
| 1204 |
+
return name
|
| 1205 |
+
|
| 1206 |
+
params_dict = dict(self.named_parameters())
|
| 1207 |
+
loaded_params: set[str] = set()
|
| 1208 |
+
|
| 1209 |
+
tp_rank = get_tensor_model_parallel_rank()
|
| 1210 |
+
tp_size = get_tensor_model_parallel_world_size()
|
| 1211 |
+
intermediate_size = self.model_config.intermediate_size
|
| 1212 |
+
|
| 1213 |
+
per_rank_intermediate_size = cdiv(intermediate_size, tp_size)
|
| 1214 |
+
# Calculate common slicing bounds for current rank
|
| 1215 |
+
tp_rank_start = tp_rank * per_rank_intermediate_size
|
| 1216 |
+
tp_rank_end = min((tp_rank + 1) * per_rank_intermediate_size,
|
| 1217 |
+
intermediate_size)
|
| 1218 |
+
|
| 1219 |
+
# Attention heads per rank
|
| 1220 |
+
heads_per_rank = self.model_config.num_attention_heads // tp_size
|
| 1221 |
+
head_start = tp_rank * heads_per_rank
|
| 1222 |
+
|
| 1223 |
+
use_ep = self.vllm_config.parallel_config.enable_expert_parallel
|
| 1224 |
+
ep_size = get_ep_group().world_size
|
| 1225 |
+
ep_rank = get_ep_group().rank
|
| 1226 |
+
num_experts = self.model_config.num_local_experts
|
| 1227 |
+
experts_per_rank = num_experts // ep_size
|
| 1228 |
+
ep_rank_start = ep_rank * experts_per_rank
|
| 1229 |
+
ep_rank_end = (ep_rank + 1) * experts_per_rank
|
| 1230 |
+
|
| 1231 |
+
for name, weight in weights:
|
| 1232 |
+
if ".experts.gate_up_proj" in name and "bias" not in name:
|
| 1233 |
+
# Handle MLP gate and up projection weights
|
| 1234 |
+
new_name = name.replace(".experts.gate_up_proj",
|
| 1235 |
+
".experts.w13_weight")
|
| 1236 |
+
|
| 1237 |
+
# Extract gate and up projection parts
|
| 1238 |
+
# since the weight is shuffled, we can slice directly
|
| 1239 |
+
if use_ep:
|
| 1240 |
+
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
|
| 1241 |
+
else:
|
| 1242 |
+
narrow_weight = weight[:, :,
|
| 1243 |
+
2 * tp_rank_start:2 * tp_rank_end]
|
| 1244 |
+
|
| 1245 |
+
narrow_weight = narrow_weight.permute(0, 2, 1).contiguous()
|
| 1246 |
+
param = params_dict[new_name]
|
| 1247 |
+
|
| 1248 |
+
param.copy_(narrow_weight)
|
| 1249 |
+
loaded_params.add(new_name)
|
| 1250 |
+
|
| 1251 |
+
elif ".experts.down_proj" in name and "bias" not in name:
|
| 1252 |
+
# Handle MLP down projection weights
|
| 1253 |
+
new_name = name.replace(".experts.down_proj",
|
| 1254 |
+
".experts.w2_weight")
|
| 1255 |
+
|
| 1256 |
+
if use_ep:
|
| 1257 |
+
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
|
| 1258 |
+
else:
|
| 1259 |
+
narrow_weight = weight[:, tp_rank_start:tp_rank_end, :]
|
| 1260 |
+
narrow_weight = narrow_weight.permute(0, 2, 1).contiguous()
|
| 1261 |
+
param = params_dict[new_name]
|
| 1262 |
+
|
| 1263 |
+
param.copy_(narrow_weight)
|
| 1264 |
+
loaded_params.add(new_name)
|
| 1265 |
+
|
| 1266 |
+
elif "gate_up_proj_bias" in name:
|
| 1267 |
+
# Handle MLP gate and up projection biases
|
| 1268 |
+
new_name = name.replace("gate_up_proj_bias", "w13_bias")
|
| 1269 |
+
|
| 1270 |
+
# Extract gate and up projection bias parts
|
| 1271 |
+
if use_ep:
|
| 1272 |
+
narrow_weight = weight[ep_rank_start:ep_rank_end, ...]
|
| 1273 |
+
else:
|
| 1274 |
+
narrow_weight = weight[:,
|
| 1275 |
+
2 * tp_rank_start:2 * tp_rank_end]
|
| 1276 |
+
|
| 1277 |
+
param = params_dict[new_name]
|
| 1278 |
+
|
| 1279 |
+
param.copy_(narrow_weight)
|
| 1280 |
+
loaded_params.add(new_name)
|
| 1281 |
+
|
| 1282 |
+
elif "down_proj_bias" in name:
|
| 1283 |
+
# Handle MLP down projection bias
|
| 1284 |
+
new_name = name.replace("down_proj_bias", "w2_bias")
|
| 1285 |
+
|
| 1286 |
+
if use_ep:
|
| 1287 |
+
weight = weight[ep_rank_start:ep_rank_end, ...]
|
| 1288 |
+
else:
|
| 1289 |
+
# (only load on rank 0 to avoid duplication)
|
| 1290 |
+
if tp_rank != 0:
|
| 1291 |
+
weight.zero_()
|
| 1292 |
+
param = params_dict[new_name]
|
| 1293 |
+
param.copy_(weight)
|
| 1294 |
+
loaded_params.add(new_name)
|
| 1295 |
+
elif "sinks" in name:
|
| 1296 |
+
# Handle attention sinks (distributed across ranks)
|
| 1297 |
+
name = name.replace("self_attn", "attn")
|
| 1298 |
+
param = params_dict[name]
|
| 1299 |
+
narrow_weight = weight.narrow(0, head_start, heads_per_rank)
|
| 1300 |
+
param.data.copy_(narrow_weight)
|
| 1301 |
+
loaded_params.add(name)
|
| 1302 |
+
elif "q_proj" in name or "k_proj" in name or "v_proj" in name:
|
| 1303 |
+
shard_id = ("q" if "q_proj" in name else
|
| 1304 |
+
"k" if "k_proj" in name else "v")
|
| 1305 |
+
name = name.replace("self_attn", "attn")
|
| 1306 |
+
param_name = name.replace(f"{shard_id}_proj", "qkv")
|
| 1307 |
+
param = params_dict[param_name]
|
| 1308 |
+
weight_loader = param.weight_loader
|
| 1309 |
+
weight_loader(param, weight, loaded_shard_id=shard_id)
|
| 1310 |
+
loaded_params.add(param_name)
|
| 1311 |
+
else:
|
| 1312 |
+
# Handle all other weights with potential renaming
|
| 1313 |
+
|
| 1314 |
+
renamed_name = maybe_rename(name)
|
| 1315 |
+
if renamed_name not in params_dict:
|
| 1316 |
+
continue
|
| 1317 |
+
param = params_dict[renamed_name]
|
| 1318 |
+
weight_loader = getattr(param, "weight_loader",
|
| 1319 |
+
default_weight_loader)
|
| 1320 |
+
weight_loader(param, weight)
|
| 1321 |
+
loaded_params.add(renamed_name)
|
| 1322 |
+
|
| 1323 |
+
return loaded_params
|
| 1324 |
+
|
| 1325 |
+
def load_weights(self, weights: Iterable[tuple[str,
|
| 1326 |
+
torch.Tensor]]) -> set[str]:
|
| 1327 |
+
quant_method = (self.model_config.quantization_config['quant_method']
|
| 1328 |
+
if hasattr(self.model_config, "quantization_config")
|
| 1329 |
+
else None)
|
| 1330 |
+
if quant_method == "mxfp4":
|
| 1331 |
+
return self._load_weights_mxfp4(weights)
|
| 1332 |
+
else:
|
| 1333 |
+
return self._load_weights_other(weights)
|
| 1334 |
+
```
|
| 1335 |
+
|
| 1336 |
+
### LMDeploy
|
| 1337 |
+
|
| 1338 |
+
***WARNING: Up to version 0.9.2, lmdeploy does not provide support for GPT-OSS. To deploy InternVL3_5-GPT-OSS-20B-Preview, we recommend using vLLM.***
|
| 1339 |
+
|
| 1340 |
+
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
|
| 1341 |
+
|
| 1342 |
+
```sh
|
| 1343 |
+
pip install lmdeploy>=0.9.1
|
| 1344 |
+
```
|
| 1345 |
+
|
| 1346 |
+
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
|
| 1347 |
+
|
| 1348 |
+
#### A 'Hello, world' Example
|
| 1349 |
+
|
| 1350 |
+
```python
|
| 1351 |
+
from lmdeploy import pipeline, PytorchEngineConfig
|
| 1352 |
+
from lmdeploy.vl import load_image
|
| 1353 |
+
|
| 1354 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
|
| 1355 |
+
|
| 1356 |
+
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
|
| 1357 |
+
model = 'OpenGVLab/InternVL3_5-8B'
|
| 1358 |
+
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
|
| 1359 |
+
|
| 1360 |
+
response = pipe(('describe this image', image))
|
| 1361 |
+
print(response.text)
|
| 1362 |
+
```
|
| 1363 |
+
|
| 1364 |
+
#### Multi-images Inference
|
| 1365 |
+
|
| 1366 |
+
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
|
| 1367 |
+
|
| 1368 |
+
```python
|
| 1369 |
+
from lmdeploy import pipeline, PytorchEngineConfig
|
| 1370 |
+
from lmdeploy.vl import load_image
|
| 1371 |
+
from lmdeploy.vl.constants import IMAGE_TOKEN
|
| 1372 |
+
|
| 1373 |
+
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
|
| 1374 |
+
model = 'OpenGVLab/InternVL3_5-8B'
|
| 1375 |
+
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
|
| 1376 |
+
|
| 1377 |
+
image_urls=[
|
| 1378 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
|
| 1379 |
+
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
|
| 1380 |
+
]
|
| 1381 |
+
|
| 1382 |
+
images = [load_image(img_url) for img_url in image_urls]
|
| 1383 |
+
# Numbering images improves multi-image conversations
|
| 1384 |
+
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
|
| 1385 |
+
print(response.text)
|
| 1386 |
+
```
|
| 1387 |
+
|
| 1388 |
+
#### Batch Prompts Inference
|
| 1389 |
+
|
| 1390 |
+
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
|
| 1391 |
+
|
| 1392 |
+
```python
|
| 1393 |
+
from lmdeploy import pipeline, PytorchEngineConfig
|
| 1394 |
+
from lmdeploy.vl import load_image
|
| 1395 |
+
|
| 1396 |
+
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
|
| 1397 |
+
model = 'OpenGVLab/InternVL3_5-8B'
|
| 1398 |
+
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
|
| 1399 |
+
|
| 1400 |
+
image_urls=[
|
| 1401 |
+
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
|
| 1402 |
+
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
|
| 1403 |
+
]
|
| 1404 |
+
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
|
| 1405 |
+
response = pipe(prompts)
|
| 1406 |
+
print(response)
|
| 1407 |
+
```
|
| 1408 |
+
|
| 1409 |
+
#### Multi-turn Conversation
|
| 1410 |
+
|
| 1411 |
+
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
|
| 1412 |
+
|
| 1413 |
+
```python
|
| 1414 |
+
from lmdeploy import pipeline, PytorchEngineConfig, GenerationConfig
|
| 1415 |
+
from lmdeploy.vl import load_image
|
| 1416 |
+
|
| 1417 |
+
# Please set tp=2 for the 38B version and tp=8 for the 241B-A28B version.
|
| 1418 |
+
model = 'OpenGVLab/InternVL3_5-8B'
|
| 1419 |
+
pipe = pipeline(model, backend_config=PytorchEngineConfig(session_len=32768, tp=1))
|
| 1420 |
+
|
| 1421 |
+
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
|
| 1422 |
+
gen_config = GenerationConfig(top_k=50, top_p=0.95, temperature=0.6, max_new_tokens=8192)
|
| 1423 |
+
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
|
| 1424 |
+
print(sess.response.text)
|
| 1425 |
+
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
|
| 1426 |
+
print(sess.response.text)
|
| 1427 |
+
```
|
| 1428 |
+
|
| 1429 |
+
#### Service
|
| 1430 |
+
|
| 1431 |
+
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
|
| 1432 |
+
|
| 1433 |
+
```shell
|
| 1434 |
+
lmdeploy serve api_server OpenGVLab/InternVL3_5-8B --server-port 23333 --tp 1 --backend pytorch
|
| 1435 |
+
```
|
| 1436 |
+
|
| 1437 |
+
To use the OpenAI-style interface, you need to install OpenAI:
|
| 1438 |
+
|
| 1439 |
+
```shell
|
| 1440 |
+
pip install openai
|
| 1441 |
+
```
|
| 1442 |
+
|
| 1443 |
+
Then, use the code below to make the API call:
|
| 1444 |
+
|
| 1445 |
+
```python
|
| 1446 |
+
from openai import OpenAI
|
| 1447 |
+
|
| 1448 |
+
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
|
| 1449 |
+
model_name = client.models.list().data[0].id
|
| 1450 |
+
response = client.chat.completions.create(
|
| 1451 |
+
model=model_name,
|
| 1452 |
+
messages=[{
|
| 1453 |
+
'role':
|
| 1454 |
+
'user',
|
| 1455 |
+
'content': [{
|
| 1456 |
+
'type': 'text',
|
| 1457 |
+
'text': 'describe this image',
|
| 1458 |
+
}, {
|
| 1459 |
+
'type': 'image_url',
|
| 1460 |
+
'image_url': {
|
| 1461 |
+
'url':
|
| 1462 |
+
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
|
| 1463 |
+
},
|
| 1464 |
+
}],
|
| 1465 |
+
}],
|
| 1466 |
+
temperature=0.8,
|
| 1467 |
+
top_p=0.8)
|
| 1468 |
+
print(response)
|
| 1469 |
+
```
|
| 1470 |
+
|
| 1471 |
+
## License
|
| 1472 |
+
|
| 1473 |
+
This project is released under the apache-2.0 License. This project uses the pre-trained Qwen3 as a component, which is licensed under the apache-2.0 License.
|
| 1474 |
+
|
| 1475 |
+
## Citation
|
| 1476 |
+
|
| 1477 |
+
If you find this project useful in your research, please consider citing:
|
| 1478 |
+
|
| 1479 |
+
```BibTeX
|
| 1480 |
+
@article{wang2025internvl3_5,
|
| 1481 |
+
title={InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency},
|
| 1482 |
+
author={Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others},
|
| 1483 |
+
journal={arXiv preprint arXiv:2508.18265},
|
| 1484 |
+
year={2025}
|
| 1485 |
+
}
|
| 1486 |
+
```
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,397 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{#-
|
| 2 |
+
In addition to the normal inputs of `messages` and `tools`, this template also accepts the
|
| 3 |
+
following kwargs:
|
| 4 |
+
- "builtin_tools": A list, can contain "browser" and/or "python".
|
| 5 |
+
- "model_identity": A string that optionally describes the model identity.
|
| 6 |
+
- "reasoning_effort": A string that describes the reasoning effort, defaults to "medium".
|
| 7 |
+
#}
|
| 8 |
+
|
| 9 |
+
{#- Tool Definition Rendering ============================================== #}
|
| 10 |
+
{%- macro render_typescript_type(param_spec, required_params, is_nullable=false) -%}
|
| 11 |
+
{%- if param_spec.type == "array" -%}
|
| 12 |
+
{%- if param_spec['items'] -%}
|
| 13 |
+
{%- if param_spec['items']['type'] == "string" -%}
|
| 14 |
+
{{- "string[]" }}
|
| 15 |
+
{%- elif param_spec['items']['type'] == "number" -%}
|
| 16 |
+
{{- "number[]" }}
|
| 17 |
+
{%- elif param_spec['items']['type'] == "integer" -%}
|
| 18 |
+
{{- "number[]" }}
|
| 19 |
+
{%- elif param_spec['items']['type'] == "boolean" -%}
|
| 20 |
+
{{- "boolean[]" }}
|
| 21 |
+
{%- else -%}
|
| 22 |
+
{%- set inner_type = render_typescript_type(param_spec['items'], required_params) -%}
|
| 23 |
+
{%- if inner_type == "object | object" or inner_type|length > 50 -%}
|
| 24 |
+
{{- "any[]" }}
|
| 25 |
+
{%- else -%}
|
| 26 |
+
{{- inner_type + "[]" }}
|
| 27 |
+
{%- endif -%}
|
| 28 |
+
{%- endif -%}
|
| 29 |
+
{%- if param_spec.nullable -%}
|
| 30 |
+
{{- " | null" }}
|
| 31 |
+
{%- endif -%}
|
| 32 |
+
{%- else -%}
|
| 33 |
+
{{- "any[]" }}
|
| 34 |
+
{%- if param_spec.nullable -%}
|
| 35 |
+
{{- " | null" }}
|
| 36 |
+
{%- endif -%}
|
| 37 |
+
{%- endif -%}
|
| 38 |
+
{%- elif param_spec.type is defined and param_spec.type is iterable and param_spec.type is not string and param_spec.type is not mapping and param_spec.type[0] is defined -%}
|
| 39 |
+
{#- Handle array of types like ["object", "object"] from Union[dict, list] #}
|
| 40 |
+
{%- if param_spec.type | length > 1 -%}
|
| 41 |
+
{{- param_spec.type | join(" | ") }}
|
| 42 |
+
{%- else -%}
|
| 43 |
+
{{- param_spec.type[0] }}
|
| 44 |
+
{%- endif -%}
|
| 45 |
+
{%- elif param_spec.oneOf -%}
|
| 46 |
+
{#- Handle oneOf schemas - check for complex unions and fallback to any #}
|
| 47 |
+
{%- set has_object_variants = false -%}
|
| 48 |
+
{%- for variant in param_spec.oneOf -%}
|
| 49 |
+
{%- if variant.type == "object" -%}
|
| 50 |
+
{%- set has_object_variants = true -%}
|
| 51 |
+
{%- endif -%}
|
| 52 |
+
{%- endfor -%}
|
| 53 |
+
{%- if has_object_variants and param_spec.oneOf|length > 1 -%}
|
| 54 |
+
{{- "any" }}
|
| 55 |
+
{%- else -%}
|
| 56 |
+
{%- for variant in param_spec.oneOf -%}
|
| 57 |
+
{{- render_typescript_type(variant, required_params) -}}
|
| 58 |
+
{%- if variant.description %}
|
| 59 |
+
{{- "// " + variant.description }}
|
| 60 |
+
{%- endif -%}
|
| 61 |
+
{%- if variant.default is defined %}
|
| 62 |
+
{{ "// default: " + variant.default|tojson }}
|
| 63 |
+
{%- endif -%}
|
| 64 |
+
{%- if not loop.last %}
|
| 65 |
+
{{- " | " }}
|
| 66 |
+
{% endif -%}
|
| 67 |
+
{%- endfor -%}
|
| 68 |
+
{%- endif -%}
|
| 69 |
+
{%- elif param_spec.type == "string" -%}
|
| 70 |
+
{%- if param_spec.enum -%}
|
| 71 |
+
{{- '"' + param_spec.enum|join('" | "') + '"' -}}
|
| 72 |
+
{%- else -%}
|
| 73 |
+
{{- "string" }}
|
| 74 |
+
{%- if param_spec.nullable %}
|
| 75 |
+
{{- " | null" }}
|
| 76 |
+
{%- endif -%}
|
| 77 |
+
{%- endif -%}
|
| 78 |
+
{%- elif param_spec.type == "number" -%}
|
| 79 |
+
{{- "number" }}
|
| 80 |
+
{%- elif param_spec.type == "integer" -%}
|
| 81 |
+
{{- "number" }}
|
| 82 |
+
{%- elif param_spec.type == "boolean" -%}
|
| 83 |
+
{{- "boolean" }}
|
| 84 |
+
|
| 85 |
+
{%- elif param_spec.type == "object" -%}
|
| 86 |
+
{%- if param_spec.properties -%}
|
| 87 |
+
{{- "{
|
| 88 |
+
" }}
|
| 89 |
+
{%- for prop_name, prop_spec in param_spec.properties.items() -%}
|
| 90 |
+
{{- prop_name -}}
|
| 91 |
+
{%- if prop_name not in (param_spec.required or []) -%}
|
| 92 |
+
{{- "?" }}
|
| 93 |
+
{%- endif -%}
|
| 94 |
+
{{- ": " }}
|
| 95 |
+
{{ render_typescript_type(prop_spec, param_spec.required or []) }}
|
| 96 |
+
{%- if not loop.last -%}
|
| 97 |
+
{{-", " }}
|
| 98 |
+
{%- endif -%}
|
| 99 |
+
{%- endfor -%}
|
| 100 |
+
{{- "}" }}
|
| 101 |
+
{%- else -%}
|
| 102 |
+
{{- "object" }}
|
| 103 |
+
{%- endif -%}
|
| 104 |
+
{%- else -%}
|
| 105 |
+
{{- "any" }}
|
| 106 |
+
{%- endif -%}
|
| 107 |
+
{%- endmacro -%}
|
| 108 |
+
|
| 109 |
+
{%- macro render_tool_namespace(namespace_name, tools) -%}
|
| 110 |
+
{{- "## " + namespace_name + "
|
| 111 |
+
|
| 112 |
+
" }}
|
| 113 |
+
{{- "namespace " + namespace_name + " {
|
| 114 |
+
|
| 115 |
+
" }}
|
| 116 |
+
{%- for tool in tools %}
|
| 117 |
+
{%- set tool = tool.function %}
|
| 118 |
+
{{- "// " + tool.description + "
|
| 119 |
+
" }}
|
| 120 |
+
{{- "type "+ tool.name + " = " }}
|
| 121 |
+
{%- if tool.parameters and tool.parameters.properties %}
|
| 122 |
+
{{- "(_: {
|
| 123 |
+
" }}
|
| 124 |
+
{%- for param_name, param_spec in tool.parameters.properties.items() %}
|
| 125 |
+
{%- if param_spec.description %}
|
| 126 |
+
{{- "// " + param_spec.description + "
|
| 127 |
+
" }}
|
| 128 |
+
{%- endif %}
|
| 129 |
+
{{- param_name }}
|
| 130 |
+
{%- if param_name not in (tool.parameters.required or []) -%}
|
| 131 |
+
{{- "?" }}
|
| 132 |
+
{%- endif -%}
|
| 133 |
+
{{- ": " }}
|
| 134 |
+
{{- render_typescript_type(param_spec, tool.parameters.required or []) }}
|
| 135 |
+
{%- if param_spec.default is defined -%}
|
| 136 |
+
{%- if param_spec.enum %}
|
| 137 |
+
{{- ", // default: " + param_spec.default }}
|
| 138 |
+
{%- elif param_spec.oneOf %}
|
| 139 |
+
{{- "// default: " + param_spec.default }}
|
| 140 |
+
{%- else %}
|
| 141 |
+
{{- ", // default: " + param_spec.default|tojson }}
|
| 142 |
+
{%- endif -%}
|
| 143 |
+
{%- endif -%}
|
| 144 |
+
{%- if not loop.last %}
|
| 145 |
+
{{- ",
|
| 146 |
+
" }}
|
| 147 |
+
{%- else %}
|
| 148 |
+
{{- "
|
| 149 |
+
" }}
|
| 150 |
+
{%- endif -%}
|
| 151 |
+
{%- endfor %}
|
| 152 |
+
{{- "}) => any;
|
| 153 |
+
|
| 154 |
+
" }}
|
| 155 |
+
{%- else -%}
|
| 156 |
+
{{- "() => any;
|
| 157 |
+
|
| 158 |
+
" }}
|
| 159 |
+
{%- endif -%}
|
| 160 |
+
{%- endfor %}
|
| 161 |
+
{{- "} // namespace " + namespace_name }}
|
| 162 |
+
{%- endmacro -%}
|
| 163 |
+
|
| 164 |
+
{%- macro render_builtin_tools(browser_tool, python_tool) -%}
|
| 165 |
+
{%- if browser_tool %}
|
| 166 |
+
{{- "## browser
|
| 167 |
+
|
| 168 |
+
" }}
|
| 169 |
+
{{- "// Tool for browsing.
|
| 170 |
+
" }}
|
| 171 |
+
{{- "// The `cursor` appears in brackets before each browsing display: `[{cursor}]`.
|
| 172 |
+
" }}
|
| 173 |
+
{{- "// Cite information from the tool using the following format:
|
| 174 |
+
" }}
|
| 175 |
+
{{- "// `【{cursor}†L{line_start}(-L{line_end})?】`, for example: `【6†L9-L11】` or `【8†L3】`.
|
| 176 |
+
" }}
|
| 177 |
+
{{- "// Do not quote more than 10 words directly from the tool output.
|
| 178 |
+
" }}
|
| 179 |
+
{{- "// sources=web (default: web)
|
| 180 |
+
" }}
|
| 181 |
+
{{- "namespace browser {
|
| 182 |
+
|
| 183 |
+
" }}
|
| 184 |
+
{{- "// Searches for information related to `query` and displays `topn` results.
|
| 185 |
+
" }}
|
| 186 |
+
{{- "type search = (_: {
|
| 187 |
+
" }}
|
| 188 |
+
{{- "query: string,
|
| 189 |
+
" }}
|
| 190 |
+
{{- "topn?: number, // default: 10
|
| 191 |
+
" }}
|
| 192 |
+
{{- "source?: string,
|
| 193 |
+
" }}
|
| 194 |
+
{{- "}) => any;
|
| 195 |
+
|
| 196 |
+
" }}
|
| 197 |
+
{{- "// Opens the link `id` from the page indicated by `cursor` starting at line number `loc`, showing `num_lines` lines.
|
| 198 |
+
" }}
|
| 199 |
+
{{- "// Valid link ids are displayed with the formatting: `【{id}†.*】`.
|
| 200 |
+
" }}
|
| 201 |
+
{{- "// If `cursor` is not provided, the most recent page is implied.
|
| 202 |
+
" }}
|
| 203 |
+
{{- "// If `id` is a string, it is treated as a fully qualified URL associated with `source`.
|
| 204 |
+
" }}
|
| 205 |
+
{{- "// If `loc` is not provided, the viewport will be positioned at the beginning of the document or centered on the most relevant passage, if available.
|
| 206 |
+
" }}
|
| 207 |
+
{{- "// Use this function without `id` to scroll to a new location of an opened page.
|
| 208 |
+
" }}
|
| 209 |
+
{{- "type open = (_: {
|
| 210 |
+
" }}
|
| 211 |
+
{{- "id?: number | string, // default: -1
|
| 212 |
+
" }}
|
| 213 |
+
{{- "cursor?: number, // default: -1
|
| 214 |
+
" }}
|
| 215 |
+
{{- "loc?: number, // default: -1
|
| 216 |
+
" }}
|
| 217 |
+
{{- "num_lines?: number, // default: -1
|
| 218 |
+
" }}
|
| 219 |
+
{{- "view_source?: boolean, // default: false
|
| 220 |
+
" }}
|
| 221 |
+
{{- "source?: string,
|
| 222 |
+
" }}
|
| 223 |
+
{{- "}) => any;
|
| 224 |
+
|
| 225 |
+
" }}
|
| 226 |
+
{{- "// Finds exact matches of `pattern` in the current page, or the page given by `cursor`.
|
| 227 |
+
" }}
|
| 228 |
+
{{- "type find = (_: {
|
| 229 |
+
" }}
|
| 230 |
+
{{- "pattern: string,
|
| 231 |
+
" }}
|
| 232 |
+
{{- "cursor?: number, // default: -1
|
| 233 |
+
" }}
|
| 234 |
+
{{- "}) => any;
|
| 235 |
+
|
| 236 |
+
" }}
|
| 237 |
+
{{- "} // namespace browser
|
| 238 |
+
|
| 239 |
+
" }}
|
| 240 |
+
{%- endif -%}
|
| 241 |
+
|
| 242 |
+
{%- if python_tool %}
|
| 243 |
+
{{- "## python
|
| 244 |
+
|
| 245 |
+
" }}
|
| 246 |
+
{{- "Use this tool to execute Python code in your chain of thought. The code will not be shown to the user. This tool should be used for internal reasoning, but not for code that is intended to be visible to the user (e.g. when creating plots, tables, or files).
|
| 247 |
+
|
| 248 |
+
" }}
|
| 249 |
+
{{- "When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment. python will respond with the output of the execution or time out after 120.0 seconds. The drive at '/mnt/data' can be used to save and persist user files. Internet access for this session is UNKNOWN. Depends on the cluster.
|
| 250 |
+
|
| 251 |
+
" }}
|
| 252 |
+
{%- endif -%}
|
| 253 |
+
{%- endmacro -%}
|
| 254 |
+
|
| 255 |
+
{#- System Message Construction ============================================ #}
|
| 256 |
+
{%- macro build_system_message() -%}
|
| 257 |
+
{%- if model_identity is not defined %}
|
| 258 |
+
{%- set model_identity = "You are ChatGPT, a large language model trained by OpenAI." %}
|
| 259 |
+
{%- endif %}
|
| 260 |
+
{{- model_identity + "
|
| 261 |
+
" }}
|
| 262 |
+
{{- "Knowledge cutoff: 2024-06
|
| 263 |
+
" }}
|
| 264 |
+
{{- "Current date: " + strftime_now("%Y-%m-%d") + "
|
| 265 |
+
|
| 266 |
+
" }}
|
| 267 |
+
{%- if reasoning_effort is not defined %}
|
| 268 |
+
{%- set reasoning_effort = "medium" %}
|
| 269 |
+
{%- endif %}
|
| 270 |
+
{{- "Reasoning: " + reasoning_effort + "
|
| 271 |
+
|
| 272 |
+
" }}
|
| 273 |
+
{%- if builtin_tools %}
|
| 274 |
+
{{- "# Tools
|
| 275 |
+
|
| 276 |
+
" }}
|
| 277 |
+
{%- set available_builtin_tools = namespace(browser=false, python=false) %}
|
| 278 |
+
{%- for tool in builtin_tools %}
|
| 279 |
+
{%- if tool == "browser" %}
|
| 280 |
+
{%- set available_builtin_tools.browser = true %}
|
| 281 |
+
{%- elif tool == "python" %}
|
| 282 |
+
{%- set available_builtin_tools.python = true %}
|
| 283 |
+
{%- endif %}
|
| 284 |
+
{%- endfor %}
|
| 285 |
+
{{- render_builtin_tools(available_builtin_tools.browser, available_builtin_tools.python) }}
|
| 286 |
+
{%- endif -%}
|
| 287 |
+
{{- "# Valid channels: analysis, commentary, final. Channel must be included for every message." }}
|
| 288 |
+
{%- if tools -%}
|
| 289 |
+
{{- "
|
| 290 |
+
Calls to these tools must go to the commentary channel: 'functions'." }}
|
| 291 |
+
{%- endif -%}
|
| 292 |
+
{%- endmacro -%}
|
| 293 |
+
|
| 294 |
+
{#- Main Template Logic ================================================= #}
|
| 295 |
+
{#- Set defaults #}
|
| 296 |
+
|
| 297 |
+
{#- Render system message #}
|
| 298 |
+
{{- "<|start|>system<|message|>" }}
|
| 299 |
+
{{- build_system_message() }}
|
| 300 |
+
{{- "<|end|>" }}
|
| 301 |
+
|
| 302 |
+
{#- Extract developer message #}
|
| 303 |
+
{%- if messages[0].role == "developer" or messages[0].role == "system" %}
|
| 304 |
+
{%- set developer_message = messages[0].content %}
|
| 305 |
+
{%- set loop_messages = messages[1:] %}
|
| 306 |
+
{%- else %}
|
| 307 |
+
{%- set developer_message = "" %}
|
| 308 |
+
{%- set loop_messages = messages %}
|
| 309 |
+
{%- endif %}
|
| 310 |
+
|
| 311 |
+
{#- Render developer message #}
|
| 312 |
+
{%- if developer_message or tools %}
|
| 313 |
+
{{- "<|start|>developer<|message|>" }}
|
| 314 |
+
{%- if developer_message %}
|
| 315 |
+
{{- "# Instructions
|
| 316 |
+
|
| 317 |
+
" }}
|
| 318 |
+
{{- developer_message }}
|
| 319 |
+
{%- endif %}
|
| 320 |
+
{%- if tools -%}
|
| 321 |
+
{{- "
|
| 322 |
+
|
| 323 |
+
" }}
|
| 324 |
+
{{- "# Tools
|
| 325 |
+
|
| 326 |
+
" }}
|
| 327 |
+
{{- render_tool_namespace("functions", tools) }}
|
| 328 |
+
{%- endif -%}
|
| 329 |
+
{{- "<|end|>" }}
|
| 330 |
+
{%- endif %}
|
| 331 |
+
|
| 332 |
+
{#- Render messages #}
|
| 333 |
+
{%- set last_tool_call = namespace(name=none) %}
|
| 334 |
+
{%- for message in loop_messages -%}
|
| 335 |
+
{#- At this point only assistant/user/tool messages should remain #}
|
| 336 |
+
{%- if message.role == 'assistant' -%}
|
| 337 |
+
{#- Checks to ensure the messages are being passed in the format we expect #}
|
| 338 |
+
{%- if "content" in message %}
|
| 339 |
+
{%- if "<|channel|>analysis<|message|>" in message.content or "<|channel|>final<|message|>" in message.content %}
|
| 340 |
+
{{- raise_exception("You have passed a message containing <|channel|> tags in the content field. Instead of doing this, you should pass analysis messages (the string between '<|message|>' and '<|end|>') in the 'thinking' field, and final messages (the string between '<|message|>' and '<|end|>') in the 'content' field.") }}
|
| 341 |
+
{%- endif %}
|
| 342 |
+
{%- endif %}
|
| 343 |
+
{%- if "thinking" in message %}
|
| 344 |
+
{%- if "<|channel|>analysis<|message|>" in message.thinking or "<|channel|>final<|message|>" in message.thinking %}
|
| 345 |
+
{{- raise_exception("You have passed a message containing <|channel|> tags in the thinking field. Instead of doing this, you should pass analysis messages (the string between '<|message|>' and '<|end|>') in the 'thinking' field, and final messages (the string between '<|message|>' and '<|end|>') in the 'content' field.") }}
|
| 346 |
+
{%- endif %}
|
| 347 |
+
{%- endif %}
|
| 348 |
+
{%- if "tool_calls" in message %}
|
| 349 |
+
{#- We assume max 1 tool call per message, and so we infer the tool call name #}
|
| 350 |
+
{#- in "tool" messages from the most recent assistant tool call name #}
|
| 351 |
+
{%- set tool_call = message.tool_calls[0] %}
|
| 352 |
+
{%- if tool_call.function %}
|
| 353 |
+
{%- set tool_call = tool_call.function %}
|
| 354 |
+
{%- endif %}
|
| 355 |
+
{%- if message.content and message.thinking %}
|
| 356 |
+
{{- raise_exception("Cannot pass both content and thinking in an assistant message with tool calls! Put the analysis message in one or the other, but not both.") }}
|
| 357 |
+
{%- elif message.content %}
|
| 358 |
+
{{- "<|start|>assistant<|channel|>analysis<|message|>" + message.content + "<|end|>" }}
|
| 359 |
+
{%- elif message.thinking %}
|
| 360 |
+
{{- "<|start|>assistant<|channel|>analysis<|message|>" + message.thinking + "<|end|>" }}
|
| 361 |
+
{%- endif %}
|
| 362 |
+
{{- "<|start|>assistant to=" }}
|
| 363 |
+
{{- "functions." + tool_call.name + "<|channel|>commentary " }}
|
| 364 |
+
{{- (tool_call.content_type if tool_call.content_type is defined else "json") + "<|message|>" }}
|
| 365 |
+
{{- tool_call.arguments|tojson }}
|
| 366 |
+
{{- "<|call|>" }}
|
| 367 |
+
{%- set last_tool_call.name = tool_call.name %}
|
| 368 |
+
{%- elif loop.last and not add_generation_prompt %}
|
| 369 |
+
{#- Only render the CoT if the final turn is an assistant turn and add_generation_prompt is false #}
|
| 370 |
+
{#- This is a situation that should only occur in training, never in inference. #}
|
| 371 |
+
{%- if "thinking" in message %}
|
| 372 |
+
{{- "<|start|>assistant<|channel|>analysis<|message|>" + message.thinking + "<|end|>" }}
|
| 373 |
+
{%- endif %}
|
| 374 |
+
{#- <|return|> indicates the end of generation, but <|end|> does not #}
|
| 375 |
+
{#- <|return|> should never be an input to the model, but we include it as the final token #}
|
| 376 |
+
{#- when training, so the model learns to emit it. #}
|
| 377 |
+
{{- "<|start|>assistant<|channel|>final<|message|>" + message.content + "<|return|>" }}
|
| 378 |
+
{%- else %}
|
| 379 |
+
{#- CoT is dropped during all previous turns, so we never render it for inference #}
|
| 380 |
+
{{- "<|start|>assistant<|channel|>final<|message|>" + message.content + "<|end|>" }}
|
| 381 |
+
{%- set last_tool_call.name = none %}
|
| 382 |
+
{%- endif %}
|
| 383 |
+
{%- elif message.role == 'tool' -%}
|
| 384 |
+
{%- if last_tool_call.name is none %}
|
| 385 |
+
{{- raise_exception("Message has tool role, but there was no previous assistant message with a tool call!") }}
|
| 386 |
+
{%- endif %}
|
| 387 |
+
{{- "<|start|>functions." + last_tool_call.name }}
|
| 388 |
+
{{- " to=assistant<|channel|>commentary<|message|>" + message.content|tojson + "<|end|>" }}
|
| 389 |
+
{%- elif message.role == 'user' -%}
|
| 390 |
+
{{- "<|start|>user<|message|>" + message.content + "<|end|>" }}
|
| 391 |
+
{%- endif -%}
|
| 392 |
+
{%- endfor -%}
|
| 393 |
+
|
| 394 |
+
{#- Generation prompt #}
|
| 395 |
+
{%- if add_generation_prompt -%}
|
| 396 |
+
<|start|>assistant
|
| 397 |
+
{%- endif -%}
|
config.json
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"InternVLChatModel"
|
| 4 |
+
],
|
| 5 |
+
"auto_map": {
|
| 6 |
+
"AutoConfig": "configuration_internvl_chat.InternVLChatConfig",
|
| 7 |
+
"AutoModel": "modeling_internvl_chat.InternVLChatModel",
|
| 8 |
+
"AutoModelForCausalLM": "modeling_internvl_chat.InternVLChatModel"
|
| 9 |
+
},
|
| 10 |
+
"downsample_ratio": 0.5,
|
| 11 |
+
"dynamic_image_size": true,
|
| 12 |
+
"force_image_size": 448,
|
| 13 |
+
"llm_config": {
|
| 14 |
+
"_name_or_path": "/mnt/shared-storage-user/intern7shared/internvl_a4s/checkpoints/gpt-oss-20b",
|
| 15 |
+
"architectures": [
|
| 16 |
+
"GptOssForCausalLM"
|
| 17 |
+
],
|
| 18 |
+
"attention_bias": true,
|
| 19 |
+
"attention_dropout": 0.0,
|
| 20 |
+
"eos_token_id": 200002,
|
| 21 |
+
"experts_per_token": 4,
|
| 22 |
+
"head_dim": 64,
|
| 23 |
+
"hidden_act": "silu",
|
| 24 |
+
"hidden_size": 2880,
|
| 25 |
+
"initial_context_length": 4096,
|
| 26 |
+
"initializer_range": 0.02,
|
| 27 |
+
"intermediate_size": 2880,
|
| 28 |
+
"layer_types": [
|
| 29 |
+
"sliding_attention",
|
| 30 |
+
"full_attention",
|
| 31 |
+
"sliding_attention",
|
| 32 |
+
"full_attention",
|
| 33 |
+
"sliding_attention",
|
| 34 |
+
"full_attention",
|
| 35 |
+
"sliding_attention",
|
| 36 |
+
"full_attention",
|
| 37 |
+
"sliding_attention",
|
| 38 |
+
"full_attention",
|
| 39 |
+
"sliding_attention",
|
| 40 |
+
"full_attention",
|
| 41 |
+
"sliding_attention",
|
| 42 |
+
"full_attention",
|
| 43 |
+
"sliding_attention",
|
| 44 |
+
"full_attention",
|
| 45 |
+
"sliding_attention",
|
| 46 |
+
"full_attention",
|
| 47 |
+
"sliding_attention",
|
| 48 |
+
"full_attention",
|
| 49 |
+
"sliding_attention",
|
| 50 |
+
"full_attention",
|
| 51 |
+
"sliding_attention",
|
| 52 |
+
"full_attention"
|
| 53 |
+
],
|
| 54 |
+
"max_position_embeddings": 131072,
|
| 55 |
+
"model_type": "gpt_oss",
|
| 56 |
+
"num_attention_heads": 64,
|
| 57 |
+
"num_experts_per_tok": 4,
|
| 58 |
+
"num_hidden_layers": 24,
|
| 59 |
+
"num_key_value_heads": 8,
|
| 60 |
+
"num_local_experts": 32,
|
| 61 |
+
"output_router_logits": false,
|
| 62 |
+
"pad_token_id": 199999,
|
| 63 |
+
"rms_norm_eps": 1e-05,
|
| 64 |
+
"rope_scaling": {
|
| 65 |
+
"beta_fast": 32.0,
|
| 66 |
+
"beta_slow": 1.0,
|
| 67 |
+
"factor": 32.0,
|
| 68 |
+
"original_max_position_embeddings": 4096,
|
| 69 |
+
"rope_type": "yarn",
|
| 70 |
+
"truncate": false
|
| 71 |
+
},
|
| 72 |
+
"rope_theta": 150000,
|
| 73 |
+
"router_aux_loss_coef": 0.9,
|
| 74 |
+
"sliding_window": 128,
|
| 75 |
+
"swiglu_limit": 7.0,
|
| 76 |
+
"use_cache": false,
|
| 77 |
+
"vocab_size": 200028
|
| 78 |
+
},
|
| 79 |
+
"max_dynamic_patch": 12,
|
| 80 |
+
"min_dynamic_patch": 1,
|
| 81 |
+
"model_type": "internvl_chat",
|
| 82 |
+
"output_attentions": false,
|
| 83 |
+
"output_router_logits": false,
|
| 84 |
+
"pad2square": false,
|
| 85 |
+
"ps_version": "v2",
|
| 86 |
+
"router_aux_loss_coef": 0.9,
|
| 87 |
+
"select_layer": -1,
|
| 88 |
+
"template": "internvl3_5_gpt_oss",
|
| 89 |
+
"tie_word_embeddings": false,
|
| 90 |
+
"torch_dtype": "bfloat16",
|
| 91 |
+
"transformers_version": null,
|
| 92 |
+
"use_backbone_lora": 0,
|
| 93 |
+
"use_llm_lora": 0,
|
| 94 |
+
"use_thumbnail": true,
|
| 95 |
+
"vision_config": {
|
| 96 |
+
"architectures": [
|
| 97 |
+
"InternVisionModel"
|
| 98 |
+
],
|
| 99 |
+
"attention_dropout": 0.0,
|
| 100 |
+
"auto_map": {
|
| 101 |
+
"AutoConfig": "configuration_intern_vit.InternVisionConfig",
|
| 102 |
+
"AutoModel": "modeling_intern_vit.InternVisionModel"
|
| 103 |
+
},
|
| 104 |
+
"drop_path_rate": 0.1,
|
| 105 |
+
"dropout": 0.0,
|
| 106 |
+
"hidden_act": "gelu",
|
| 107 |
+
"hidden_size": 1024,
|
| 108 |
+
"image_size": 448,
|
| 109 |
+
"initializer_factor": 1.0,
|
| 110 |
+
"initializer_range": 0.02,
|
| 111 |
+
"intermediate_size": 4096,
|
| 112 |
+
"layer_norm_eps": 1e-06,
|
| 113 |
+
"model_type": "intern_vit_6b",
|
| 114 |
+
"norm_type": "layer_norm",
|
| 115 |
+
"num_attention_heads": 16,
|
| 116 |
+
"num_channels": 3,
|
| 117 |
+
"num_hidden_layers": 24,
|
| 118 |
+
"patch_size": 14,
|
| 119 |
+
"qk_normalization": false,
|
| 120 |
+
"qkv_bias": true,
|
| 121 |
+
"torch_dtype": "bfloat16",
|
| 122 |
+
"use_flash_attn": true
|
| 123 |
+
}
|
| 124 |
+
}
|
configuration_intern_vit.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
import os
|
| 7 |
+
from typing import Union
|
| 8 |
+
|
| 9 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 10 |
+
from transformers.utils import logging
|
| 11 |
+
|
| 12 |
+
logger = logging.get_logger(__name__)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class InternVisionConfig(PretrainedConfig):
|
| 16 |
+
r"""
|
| 17 |
+
This is the configuration class to store the configuration of a [`InternVisionModel`]. It is used to
|
| 18 |
+
instantiate a vision encoder according to the specified arguments, defining the model architecture.
|
| 19 |
+
|
| 20 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 21 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 22 |
+
|
| 23 |
+
Args:
|
| 24 |
+
num_channels (`int`, *optional*, defaults to 3):
|
| 25 |
+
Number of color channels in the input images (e.g., 3 for RGB).
|
| 26 |
+
patch_size (`int`, *optional*, defaults to 14):
|
| 27 |
+
The size (resolution) of each patch.
|
| 28 |
+
image_size (`int`, *optional*, defaults to 224):
|
| 29 |
+
The size (resolution) of each image.
|
| 30 |
+
qkv_bias (`bool`, *optional*, defaults to `False`):
|
| 31 |
+
Whether to add a bias to the queries and values in the self-attention layers.
|
| 32 |
+
hidden_size (`int`, *optional*, defaults to 3200):
|
| 33 |
+
Dimensionality of the encoder layers and the pooler layer.
|
| 34 |
+
num_attention_heads (`int`, *optional*, defaults to 25):
|
| 35 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 36 |
+
intermediate_size (`int`, *optional*, defaults to 12800):
|
| 37 |
+
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
|
| 38 |
+
qk_normalization (`bool`, *optional*, defaults to `True`):
|
| 39 |
+
Whether to normalize the queries and keys in the self-attention layers.
|
| 40 |
+
num_hidden_layers (`int`, *optional*, defaults to 48):
|
| 41 |
+
Number of hidden layers in the Transformer encoder.
|
| 42 |
+
use_flash_attn (`bool`, *optional*, defaults to `True`):
|
| 43 |
+
Whether to use flash attention mechanism.
|
| 44 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
|
| 45 |
+
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
|
| 46 |
+
`"relu"`, `"selu"` and `"gelu_new"` ``"gelu"` are supported.
|
| 47 |
+
layer_norm_eps (`float`, *optional*, defaults to 1e-6):
|
| 48 |
+
The epsilon used by the layer normalization layers.
|
| 49 |
+
dropout (`float`, *optional*, defaults to 0.0):
|
| 50 |
+
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
|
| 51 |
+
drop_path_rate (`float`, *optional*, defaults to 0.0):
|
| 52 |
+
Dropout rate for stochastic depth.
|
| 53 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 54 |
+
The dropout ratio for the attention probabilities.
|
| 55 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 56 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 57 |
+
initializer_factor (`float`, *optional*, defaults to 0.1):
|
| 58 |
+
A factor for layer scale.
|
| 59 |
+
"""
|
| 60 |
+
|
| 61 |
+
model_type = 'intern_vit_6b'
|
| 62 |
+
|
| 63 |
+
def __init__(
|
| 64 |
+
self,
|
| 65 |
+
num_channels=3,
|
| 66 |
+
patch_size=14,
|
| 67 |
+
image_size=224,
|
| 68 |
+
qkv_bias=False,
|
| 69 |
+
hidden_size=3200,
|
| 70 |
+
num_attention_heads=25,
|
| 71 |
+
intermediate_size=12800,
|
| 72 |
+
qk_normalization=True,
|
| 73 |
+
num_hidden_layers=48,
|
| 74 |
+
use_flash_attn=True,
|
| 75 |
+
hidden_act='gelu',
|
| 76 |
+
norm_type='rms_norm',
|
| 77 |
+
layer_norm_eps=1e-6,
|
| 78 |
+
dropout=0.0,
|
| 79 |
+
drop_path_rate=0.0,
|
| 80 |
+
attention_dropout=0.0,
|
| 81 |
+
initializer_range=0.02,
|
| 82 |
+
initializer_factor=0.1,
|
| 83 |
+
**kwargs,
|
| 84 |
+
):
|
| 85 |
+
super().__init__(**kwargs)
|
| 86 |
+
|
| 87 |
+
self.hidden_size = hidden_size
|
| 88 |
+
self.intermediate_size = intermediate_size
|
| 89 |
+
self.dropout = dropout
|
| 90 |
+
self.drop_path_rate = drop_path_rate
|
| 91 |
+
self.num_hidden_layers = num_hidden_layers
|
| 92 |
+
self.num_attention_heads = num_attention_heads
|
| 93 |
+
self.num_channels = num_channels
|
| 94 |
+
self.patch_size = patch_size
|
| 95 |
+
self.image_size = image_size
|
| 96 |
+
self.initializer_range = initializer_range
|
| 97 |
+
self.initializer_factor = initializer_factor
|
| 98 |
+
self.attention_dropout = attention_dropout
|
| 99 |
+
self.layer_norm_eps = layer_norm_eps
|
| 100 |
+
self.hidden_act = hidden_act
|
| 101 |
+
self.norm_type = norm_type
|
| 102 |
+
self.qkv_bias = qkv_bias
|
| 103 |
+
self.qk_normalization = qk_normalization
|
| 104 |
+
self.use_flash_attn = use_flash_attn
|
| 105 |
+
|
| 106 |
+
@classmethod
|
| 107 |
+
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> 'PretrainedConfig':
|
| 108 |
+
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
|
| 109 |
+
|
| 110 |
+
if 'vision_config' in config_dict:
|
| 111 |
+
config_dict = config_dict['vision_config']
|
| 112 |
+
|
| 113 |
+
if 'model_type' in config_dict and hasattr(cls, 'model_type') and config_dict['model_type'] != cls.model_type:
|
| 114 |
+
logger.warning(
|
| 115 |
+
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
|
| 116 |
+
f'{cls.model_type}. This is not supported for all configurations of models and can yield errors.'
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
return cls.from_dict(config_dict, **kwargs)
|
configuration_internvl_chat.py
ADDED
|
@@ -0,0 +1,118 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
import copy
|
| 8 |
+
from typing import Dict, Any, Optional
|
| 9 |
+
|
| 10 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 11 |
+
from transformers.utils import logging
|
| 12 |
+
|
| 13 |
+
from .configuration_intern_vit import InternVisionConfig
|
| 14 |
+
|
| 15 |
+
logger = logging.get_logger(__name__)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class InternVLChatConfig(PretrainedConfig):
|
| 19 |
+
model_type = 'internvl_chat'
|
| 20 |
+
is_composition = True
|
| 21 |
+
|
| 22 |
+
def __init__(
|
| 23 |
+
self,
|
| 24 |
+
vision_config: Optional[Dict[str, Any]] = None,
|
| 25 |
+
llm_config: Optional[Dict[str, Any]] = None,
|
| 26 |
+
use_backbone_lora=0,
|
| 27 |
+
use_llm_lora=0,
|
| 28 |
+
select_layer=-1,
|
| 29 |
+
force_image_size=None,
|
| 30 |
+
downsample_ratio=0.5,
|
| 31 |
+
template=None,
|
| 32 |
+
dynamic_image_size=False,
|
| 33 |
+
use_thumbnail=False,
|
| 34 |
+
ps_version="v1",
|
| 35 |
+
min_dynamic_patch=1,
|
| 36 |
+
max_dynamic_patch=6,
|
| 37 |
+
**kwargs,
|
| 38 |
+
):
|
| 39 |
+
super().__init__(**kwargs)
|
| 40 |
+
|
| 41 |
+
if vision_config is None:
|
| 42 |
+
vision_config = {'architectures': ['InternVisionModel']}
|
| 43 |
+
logger.info('vision_config is None. Initializing the InternVisionConfig with default values.')
|
| 44 |
+
|
| 45 |
+
if llm_config is None:
|
| 46 |
+
llm_config = {'architectures': ['Qwen2ForCausalLM']}
|
| 47 |
+
logger.info('llm_config is None. Initializing the LlamaConfig config with default values (`LlamaConfig`).')
|
| 48 |
+
assert 'architectures' in llm_config, "Should specify architecture in llm_config"
|
| 49 |
+
|
| 50 |
+
if isinstance(vision_config, dict):
|
| 51 |
+
self.vision_config = InternVisionConfig(**vision_config)
|
| 52 |
+
else:
|
| 53 |
+
self.vision_config = vision_config
|
| 54 |
+
|
| 55 |
+
if isinstance(llm_config, dict):
|
| 56 |
+
architecture: str = llm_config['architectures'][0]
|
| 57 |
+
if architecture == 'LlamaForCausalLM':
|
| 58 |
+
from transformers import LlamaConfig
|
| 59 |
+
self.llm_config = LlamaConfig(**llm_config)
|
| 60 |
+
elif architecture == 'Qwen2ForCausalLM':
|
| 61 |
+
from transformers import Qwen2Config
|
| 62 |
+
self.llm_config = Qwen2Config(**llm_config)
|
| 63 |
+
elif architecture == 'Qwen3MoeForCausalLM':
|
| 64 |
+
from transformers import Qwen3MoeConfig
|
| 65 |
+
self.llm_config = Qwen3MoeConfig(**llm_config)
|
| 66 |
+
elif architecture == 'Qwen3ForCausalLM':
|
| 67 |
+
from transformers import Qwen3Config
|
| 68 |
+
self.llm_config = Qwen3Config(**llm_config)
|
| 69 |
+
elif architecture == 'GptOssForCausalLM':
|
| 70 |
+
from transformers import GptOssConfig
|
| 71 |
+
self.llm_config = GptOssConfig(**llm_config)
|
| 72 |
+
else:
|
| 73 |
+
raise ValueError('Unsupported architecture: {}'.format(architecture))
|
| 74 |
+
else:
|
| 75 |
+
self.llm_config = llm_config
|
| 76 |
+
|
| 77 |
+
self.use_backbone_lora = use_backbone_lora
|
| 78 |
+
self.use_llm_lora = use_llm_lora
|
| 79 |
+
self.select_layer = select_layer
|
| 80 |
+
self.force_image_size = force_image_size
|
| 81 |
+
self.downsample_ratio = downsample_ratio
|
| 82 |
+
self.template = template
|
| 83 |
+
self.dynamic_image_size = dynamic_image_size
|
| 84 |
+
self.use_thumbnail = use_thumbnail
|
| 85 |
+
self.ps_version = ps_version # pixel shuffle version
|
| 86 |
+
self.min_dynamic_patch = min_dynamic_patch
|
| 87 |
+
self.max_dynamic_patch = max_dynamic_patch
|
| 88 |
+
self.tie_word_embeddings = self.llm_config.tie_word_embeddings
|
| 89 |
+
|
| 90 |
+
logger.info(f'vision_select_layer: {self.select_layer}')
|
| 91 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 92 |
+
logger.info(f'min_dynamic_patch: {self.min_dynamic_patch}')
|
| 93 |
+
logger.info(f'max_dynamic_patch: {self.max_dynamic_patch}')
|
| 94 |
+
|
| 95 |
+
def to_dict(self):
|
| 96 |
+
"""
|
| 97 |
+
Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
|
| 98 |
+
|
| 99 |
+
Returns:
|
| 100 |
+
`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
|
| 101 |
+
"""
|
| 102 |
+
output = copy.deepcopy(self.__dict__)
|
| 103 |
+
output['vision_config'] = self.vision_config.to_dict()
|
| 104 |
+
output['llm_config'] = self.llm_config.to_dict()
|
| 105 |
+
output['model_type'] = self.__class__.model_type
|
| 106 |
+
output['use_backbone_lora'] = self.use_backbone_lora
|
| 107 |
+
output['use_llm_lora'] = self.use_llm_lora
|
| 108 |
+
output['select_layer'] = self.select_layer
|
| 109 |
+
output['force_image_size'] = self.force_image_size
|
| 110 |
+
output['downsample_ratio'] = self.downsample_ratio
|
| 111 |
+
output['template'] = self.template
|
| 112 |
+
output['dynamic_image_size'] = self.dynamic_image_size
|
| 113 |
+
output['use_thumbnail'] = self.use_thumbnail
|
| 114 |
+
output['ps_version'] = self.ps_version
|
| 115 |
+
output['min_dynamic_patch'] = self.min_dynamic_patch
|
| 116 |
+
output['max_dynamic_patch'] = self.max_dynamic_patch
|
| 117 |
+
|
| 118 |
+
return output
|
conversation.py
ADDED
|
@@ -0,0 +1,416 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Conversation prompt templates.
|
| 3 |
+
|
| 4 |
+
We kindly request that you import fastchat instead of copying this file if you wish to use it.
|
| 5 |
+
If you have changes in mind, please contribute back so the community can benefit collectively and continue to maintain these valuable templates.
|
| 6 |
+
|
| 7 |
+
Modified from https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
import dataclasses
|
| 11 |
+
from enum import IntEnum, auto
|
| 12 |
+
from typing import Dict, List, Tuple, Union
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class SeparatorStyle(IntEnum):
|
| 16 |
+
"""Separator styles."""
|
| 17 |
+
|
| 18 |
+
ADD_COLON_SINGLE = auto()
|
| 19 |
+
ADD_COLON_TWO = auto()
|
| 20 |
+
ADD_COLON_SPACE_SINGLE = auto()
|
| 21 |
+
NO_COLON_SINGLE = auto()
|
| 22 |
+
NO_COLON_TWO = auto()
|
| 23 |
+
ADD_NEW_LINE_SINGLE = auto()
|
| 24 |
+
LLAMA2 = auto()
|
| 25 |
+
CHATGLM = auto()
|
| 26 |
+
CHATML = auto()
|
| 27 |
+
CHATINTERN = auto()
|
| 28 |
+
DOLLY = auto()
|
| 29 |
+
RWKV = auto()
|
| 30 |
+
PHOENIX = auto()
|
| 31 |
+
ROBIN = auto()
|
| 32 |
+
FALCON_CHAT = auto()
|
| 33 |
+
CHATGLM3 = auto()
|
| 34 |
+
INTERNVL_ZH = auto()
|
| 35 |
+
MPT = auto()
|
| 36 |
+
MPT_TWO = auto()
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
@dataclasses.dataclass
|
| 40 |
+
class Conversation:
|
| 41 |
+
"""A class that manages prompt templates and keeps all conversation history."""
|
| 42 |
+
|
| 43 |
+
# The name of this template
|
| 44 |
+
name: str
|
| 45 |
+
# The template of the system prompt
|
| 46 |
+
system_template: str = '{system_message}'
|
| 47 |
+
# The system message
|
| 48 |
+
system_message: str = ''
|
| 49 |
+
# The names of two roles
|
| 50 |
+
roles: Tuple[str] = ('USER', 'ASSISTANT')
|
| 51 |
+
# All messages. Each item is (role, message).
|
| 52 |
+
messages: List[List[str]] = ()
|
| 53 |
+
# The number of few shot examples
|
| 54 |
+
offset: int = 0
|
| 55 |
+
# The separator style and configurations
|
| 56 |
+
sep_style: SeparatorStyle = SeparatorStyle.ADD_COLON_SINGLE
|
| 57 |
+
sep: str = '\n'
|
| 58 |
+
sep2: str = None
|
| 59 |
+
# Stop criteria (the default one is EOS token)
|
| 60 |
+
stop_str: Union[str, List[str]] = None
|
| 61 |
+
# Stops generation if meeting any token in this list
|
| 62 |
+
stop_token_ids: List[int] = None
|
| 63 |
+
|
| 64 |
+
def get_prompt(self) -> str:
|
| 65 |
+
"""Get the prompt for generation."""
|
| 66 |
+
system_prompt = self.system_template.format(system_message=self.system_message)
|
| 67 |
+
if self.sep_style == SeparatorStyle.ADD_COLON_SINGLE:
|
| 68 |
+
ret = system_prompt + self.sep
|
| 69 |
+
for role, message in self.messages:
|
| 70 |
+
if message:
|
| 71 |
+
ret += role + ': ' + message + self.sep
|
| 72 |
+
else:
|
| 73 |
+
ret += role + ':'
|
| 74 |
+
return ret
|
| 75 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_TWO:
|
| 76 |
+
seps = [self.sep, self.sep2]
|
| 77 |
+
ret = system_prompt + seps[0]
|
| 78 |
+
for i, (role, message) in enumerate(self.messages):
|
| 79 |
+
if message:
|
| 80 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 81 |
+
else:
|
| 82 |
+
ret += role + ':'
|
| 83 |
+
return ret
|
| 84 |
+
elif self.sep_style == SeparatorStyle.ADD_COLON_SPACE_SINGLE:
|
| 85 |
+
ret = system_prompt + self.sep
|
| 86 |
+
for role, message in self.messages:
|
| 87 |
+
if message:
|
| 88 |
+
ret += role + ': ' + message + self.sep
|
| 89 |
+
else:
|
| 90 |
+
ret += role + ': ' # must be end with a space
|
| 91 |
+
return ret
|
| 92 |
+
elif self.sep_style == SeparatorStyle.ADD_NEW_LINE_SINGLE:
|
| 93 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep
|
| 94 |
+
for role, message in self.messages:
|
| 95 |
+
if message:
|
| 96 |
+
ret += role + '\n' + message + self.sep
|
| 97 |
+
else:
|
| 98 |
+
ret += role + '\n'
|
| 99 |
+
return ret
|
| 100 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_SINGLE:
|
| 101 |
+
ret = system_prompt
|
| 102 |
+
for role, message in self.messages:
|
| 103 |
+
if message:
|
| 104 |
+
ret += role + message + self.sep
|
| 105 |
+
else:
|
| 106 |
+
ret += role
|
| 107 |
+
return ret
|
| 108 |
+
elif self.sep_style == SeparatorStyle.NO_COLON_TWO:
|
| 109 |
+
seps = [self.sep, self.sep2]
|
| 110 |
+
ret = system_prompt
|
| 111 |
+
for i, (role, message) in enumerate(self.messages):
|
| 112 |
+
if message:
|
| 113 |
+
ret += role + message + seps[i % 2]
|
| 114 |
+
else:
|
| 115 |
+
ret += role
|
| 116 |
+
return ret
|
| 117 |
+
elif self.sep_style == SeparatorStyle.RWKV:
|
| 118 |
+
ret = system_prompt
|
| 119 |
+
for i, (role, message) in enumerate(self.messages):
|
| 120 |
+
if message:
|
| 121 |
+
ret += (
|
| 122 |
+
role
|
| 123 |
+
+ ': '
|
| 124 |
+
+ message.replace('\r\n', '\n').replace('\n\n', '\n')
|
| 125 |
+
)
|
| 126 |
+
ret += '\n\n'
|
| 127 |
+
else:
|
| 128 |
+
ret += role + ':'
|
| 129 |
+
return ret
|
| 130 |
+
elif self.sep_style == SeparatorStyle.LLAMA2:
|
| 131 |
+
seps = [self.sep, self.sep2]
|
| 132 |
+
if self.system_message:
|
| 133 |
+
ret = system_prompt
|
| 134 |
+
else:
|
| 135 |
+
ret = '[INST] '
|
| 136 |
+
for i, (role, message) in enumerate(self.messages):
|
| 137 |
+
tag = self.roles[i % 2]
|
| 138 |
+
if message:
|
| 139 |
+
if i == 0:
|
| 140 |
+
ret += message + ' '
|
| 141 |
+
else:
|
| 142 |
+
ret += tag + ' ' + message + seps[i % 2]
|
| 143 |
+
else:
|
| 144 |
+
ret += tag
|
| 145 |
+
return ret
|
| 146 |
+
elif self.sep_style == SeparatorStyle.CHATGLM:
|
| 147 |
+
# source: https://huggingface.co/THUDM/chatglm-6b/blob/1d240ba371910e9282298d4592532d7f0f3e9f3e/modeling_chatglm.py#L1302-L1308
|
| 148 |
+
# source2: https://huggingface.co/THUDM/chatglm2-6b/blob/e186c891cf64310ac66ef10a87e6635fa6c2a579/modeling_chatglm.py#L926
|
| 149 |
+
round_add_n = 1 if self.name == 'chatglm2' else 0
|
| 150 |
+
if system_prompt:
|
| 151 |
+
ret = system_prompt + self.sep
|
| 152 |
+
else:
|
| 153 |
+
ret = ''
|
| 154 |
+
|
| 155 |
+
for i, (role, message) in enumerate(self.messages):
|
| 156 |
+
if i % 2 == 0:
|
| 157 |
+
ret += f'[Round {i//2 + round_add_n}]{self.sep}'
|
| 158 |
+
|
| 159 |
+
if message:
|
| 160 |
+
ret += f'{role}:{message}{self.sep}'
|
| 161 |
+
else:
|
| 162 |
+
ret += f'{role}:'
|
| 163 |
+
return ret
|
| 164 |
+
elif self.sep_style == SeparatorStyle.CHATML:
|
| 165 |
+
ret = '' if system_prompt == '' else system_prompt + self.sep + '\n'
|
| 166 |
+
for role, message in self.messages:
|
| 167 |
+
if message:
|
| 168 |
+
ret += role + '\n' + message + self.sep + '\n'
|
| 169 |
+
else:
|
| 170 |
+
ret += role + '\n'
|
| 171 |
+
return ret
|
| 172 |
+
elif self.sep_style == SeparatorStyle.CHATGLM3:
|
| 173 |
+
ret = ''
|
| 174 |
+
if self.system_message:
|
| 175 |
+
ret += system_prompt
|
| 176 |
+
for role, message in self.messages:
|
| 177 |
+
if message:
|
| 178 |
+
ret += role + '\n' + ' ' + message
|
| 179 |
+
else:
|
| 180 |
+
ret += role
|
| 181 |
+
return ret
|
| 182 |
+
elif self.sep_style == SeparatorStyle.CHATINTERN:
|
| 183 |
+
# source: https://huggingface.co/internlm/internlm-chat-7b-8k/blob/bd546fa984b4b0b86958f56bf37f94aa75ab8831/modeling_internlm.py#L771
|
| 184 |
+
seps = [self.sep, self.sep2]
|
| 185 |
+
ret = system_prompt
|
| 186 |
+
for i, (role, message) in enumerate(self.messages):
|
| 187 |
+
# if i % 2 == 0:
|
| 188 |
+
# ret += "<s>"
|
| 189 |
+
if message:
|
| 190 |
+
ret += role + ':' + message + seps[i % 2] + '\n'
|
| 191 |
+
else:
|
| 192 |
+
ret += role + ':'
|
| 193 |
+
return ret
|
| 194 |
+
elif self.sep_style == SeparatorStyle.DOLLY:
|
| 195 |
+
seps = [self.sep, self.sep2]
|
| 196 |
+
ret = system_prompt
|
| 197 |
+
for i, (role, message) in enumerate(self.messages):
|
| 198 |
+
if message:
|
| 199 |
+
ret += role + ':\n' + message + seps[i % 2]
|
| 200 |
+
if i % 2 == 1:
|
| 201 |
+
ret += '\n\n'
|
| 202 |
+
else:
|
| 203 |
+
ret += role + ':\n'
|
| 204 |
+
return ret
|
| 205 |
+
elif self.sep_style == SeparatorStyle.PHOENIX:
|
| 206 |
+
ret = system_prompt
|
| 207 |
+
for role, message in self.messages:
|
| 208 |
+
if message:
|
| 209 |
+
ret += role + ': ' + '<s>' + message + '</s>'
|
| 210 |
+
else:
|
| 211 |
+
ret += role + ': ' + '<s>'
|
| 212 |
+
return ret
|
| 213 |
+
elif self.sep_style == SeparatorStyle.ROBIN:
|
| 214 |
+
ret = system_prompt + self.sep
|
| 215 |
+
for role, message in self.messages:
|
| 216 |
+
if message:
|
| 217 |
+
ret += role + ':\n' + message + self.sep
|
| 218 |
+
else:
|
| 219 |
+
ret += role + ':\n'
|
| 220 |
+
return ret
|
| 221 |
+
elif self.sep_style == SeparatorStyle.FALCON_CHAT:
|
| 222 |
+
ret = ''
|
| 223 |
+
if self.system_message:
|
| 224 |
+
ret += system_prompt + self.sep
|
| 225 |
+
for role, message in self.messages:
|
| 226 |
+
if message:
|
| 227 |
+
ret += role + ': ' + message + self.sep
|
| 228 |
+
else:
|
| 229 |
+
ret += role + ':'
|
| 230 |
+
|
| 231 |
+
return ret
|
| 232 |
+
elif self.sep_style == SeparatorStyle.INTERNVL_ZH:
|
| 233 |
+
seps = [self.sep, self.sep2]
|
| 234 |
+
ret = self.system_message + seps[0]
|
| 235 |
+
for i, (role, message) in enumerate(self.messages):
|
| 236 |
+
if message:
|
| 237 |
+
ret += role + ': ' + message + seps[i % 2]
|
| 238 |
+
else:
|
| 239 |
+
ret += role + ':'
|
| 240 |
+
return ret
|
| 241 |
+
elif self.sep_style == SeparatorStyle.MPT:
|
| 242 |
+
ret = system_prompt + self.sep
|
| 243 |
+
for role, message in self.messages:
|
| 244 |
+
if message:
|
| 245 |
+
if type(message) is tuple:
|
| 246 |
+
message, _, _ = message
|
| 247 |
+
ret += role + message + self.sep
|
| 248 |
+
else:
|
| 249 |
+
ret += role
|
| 250 |
+
return ret
|
| 251 |
+
elif self.sep_style == SeparatorStyle.MPT_TWO:
|
| 252 |
+
ret = system_prompt + self.sep
|
| 253 |
+
seps = [self.sep, self.sep2]
|
| 254 |
+
for i, (role, message) in enumerate(self.messages):
|
| 255 |
+
if message:
|
| 256 |
+
if type(message) is tuple:
|
| 257 |
+
message, _, _ = message
|
| 258 |
+
ret += role + message + seps[i % 2]
|
| 259 |
+
else:
|
| 260 |
+
ret += role
|
| 261 |
+
return ret
|
| 262 |
+
else:
|
| 263 |
+
raise ValueError(f'Invalid style: {self.sep_style}')
|
| 264 |
+
|
| 265 |
+
def set_system_message(self, system_message: str):
|
| 266 |
+
"""Set the system message."""
|
| 267 |
+
self.system_message = system_message
|
| 268 |
+
|
| 269 |
+
def append_message(self, role: str, message: str):
|
| 270 |
+
"""Append a new message."""
|
| 271 |
+
self.messages.append([role, message])
|
| 272 |
+
|
| 273 |
+
def update_last_message(self, message: str):
|
| 274 |
+
"""Update the last output.
|
| 275 |
+
|
| 276 |
+
The last message is typically set to be None when constructing the prompt,
|
| 277 |
+
so we need to update it in-place after getting the response from a model.
|
| 278 |
+
"""
|
| 279 |
+
self.messages[-1][1] = message
|
| 280 |
+
|
| 281 |
+
def to_gradio_chatbot(self):
|
| 282 |
+
"""Convert the conversation to gradio chatbot format."""
|
| 283 |
+
ret = []
|
| 284 |
+
for i, (role, msg) in enumerate(self.messages[self.offset :]):
|
| 285 |
+
if i % 2 == 0:
|
| 286 |
+
ret.append([msg, None])
|
| 287 |
+
else:
|
| 288 |
+
ret[-1][-1] = msg
|
| 289 |
+
return ret
|
| 290 |
+
|
| 291 |
+
def to_openai_api_messages(self):
|
| 292 |
+
"""Convert the conversation to OpenAI chat completion format."""
|
| 293 |
+
ret = [{'role': 'system', 'content': self.system_message}]
|
| 294 |
+
|
| 295 |
+
for i, (_, msg) in enumerate(self.messages[self.offset :]):
|
| 296 |
+
if i % 2 == 0:
|
| 297 |
+
ret.append({'role': 'user', 'content': msg})
|
| 298 |
+
else:
|
| 299 |
+
if msg is not None:
|
| 300 |
+
ret.append({'role': 'assistant', 'content': msg})
|
| 301 |
+
return ret
|
| 302 |
+
|
| 303 |
+
def copy(self):
|
| 304 |
+
return Conversation(
|
| 305 |
+
name=self.name,
|
| 306 |
+
system_template=self.system_template,
|
| 307 |
+
system_message=self.system_message,
|
| 308 |
+
roles=self.roles,
|
| 309 |
+
messages=[[x, y] for x, y in self.messages],
|
| 310 |
+
offset=self.offset,
|
| 311 |
+
sep_style=self.sep_style,
|
| 312 |
+
sep=self.sep,
|
| 313 |
+
sep2=self.sep2,
|
| 314 |
+
stop_str=self.stop_str,
|
| 315 |
+
stop_token_ids=self.stop_token_ids,
|
| 316 |
+
)
|
| 317 |
+
|
| 318 |
+
def dict(self):
|
| 319 |
+
return {
|
| 320 |
+
'template_name': self.name,
|
| 321 |
+
'system_message': self.system_message,
|
| 322 |
+
'roles': self.roles,
|
| 323 |
+
'messages': self.messages,
|
| 324 |
+
'offset': self.offset,
|
| 325 |
+
}
|
| 326 |
+
|
| 327 |
+
|
| 328 |
+
# A global registry for all conversation templates
|
| 329 |
+
conv_templates: Dict[str, Conversation] = {}
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
def register_conv_template(template: Conversation, override: bool = False):
|
| 333 |
+
"""Register a new conversation template."""
|
| 334 |
+
if not override:
|
| 335 |
+
assert (
|
| 336 |
+
template.name not in conv_templates
|
| 337 |
+
), f'{template.name} has been registered.'
|
| 338 |
+
|
| 339 |
+
conv_templates[template.name] = template
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
def get_conv_template(name: str) -> Conversation:
|
| 343 |
+
"""Get a conversation template."""
|
| 344 |
+
return conv_templates[name].copy()
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
# Both Hermes-2 and internlm2-chat are chatml-format conversation templates. The difference
|
| 348 |
+
# is that during training, the preprocessing function for the Hermes-2 template doesn't add
|
| 349 |
+
# <s> at the beginning of the tokenized sequence, while the internlm2-chat template does.
|
| 350 |
+
# Therefore, they are completely equivalent during inference.
|
| 351 |
+
register_conv_template(
|
| 352 |
+
Conversation(
|
| 353 |
+
name='Hermes-2',
|
| 354 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 355 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 356 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华大学及多家合作单位联合开发的多模态大语言模型。',
|
| 357 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 358 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 359 |
+
sep_style=SeparatorStyle.MPT,
|
| 360 |
+
sep='<|im_end|>',
|
| 361 |
+
stop_str='<|endoftext|>',
|
| 362 |
+
)
|
| 363 |
+
)
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
register_conv_template(
|
| 367 |
+
Conversation(
|
| 368 |
+
name='internlm2-chat',
|
| 369 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 370 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 371 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华大学及多家合作单位联合开发的多模态大语言模型。',
|
| 372 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 373 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 374 |
+
sep_style=SeparatorStyle.MPT,
|
| 375 |
+
sep='<|im_end|>',
|
| 376 |
+
)
|
| 377 |
+
)
|
| 378 |
+
|
| 379 |
+
|
| 380 |
+
register_conv_template(
|
| 381 |
+
Conversation(
|
| 382 |
+
name='phi3-chat',
|
| 383 |
+
system_template='<|system|>\n{system_message}',
|
| 384 |
+
# note: The new system prompt was not used here to avoid changes in benchmark performance.
|
| 385 |
+
# system_message='我是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华���学及多家合作单位联合开发的多模态大语言模型。',
|
| 386 |
+
system_message='你是由上海人工智能实验室联合商汤科技开发的书生多模态大模型,英文名叫InternVL, 是一个有用无害的人工智能助手。',
|
| 387 |
+
roles=('<|user|>\n', '<|assistant|>\n'),
|
| 388 |
+
sep_style=SeparatorStyle.MPT,
|
| 389 |
+
sep='<|end|>',
|
| 390 |
+
)
|
| 391 |
+
)
|
| 392 |
+
|
| 393 |
+
|
| 394 |
+
register_conv_template(
|
| 395 |
+
Conversation(
|
| 396 |
+
name='internvl2_5',
|
| 397 |
+
system_template='<|im_start|>system\n{system_message}',
|
| 398 |
+
system_message='你是书生·万象,英文名是InternVL,是由上海人工智能实验室、清华大学及多家合作单位联合开发的多模态大语言模型。',
|
| 399 |
+
roles=('<|im_start|>user\n', '<|im_start|>assistant\n'),
|
| 400 |
+
sep_style=SeparatorStyle.MPT,
|
| 401 |
+
sep='<|im_end|>\n',
|
| 402 |
+
)
|
| 403 |
+
)
|
| 404 |
+
|
| 405 |
+
|
| 406 |
+
register_conv_template(
|
| 407 |
+
Conversation(
|
| 408 |
+
name='internvl3_5_gpt_oss',
|
| 409 |
+
system_template='<|start|>system<|message|>{system_message}',
|
| 410 |
+
system_message='You are InternVL, a large language model trained by Shanghai AI Laboratory.\nKnowledge cutoff: 2024-06\nCurrent date: 2025-08-06\n\nReasoning: low\n\n# Valid channels: final. Channel must be included for every message.',
|
| 411 |
+
roles=('<|start|>user<|message|>', '<|start|>assistant'),
|
| 412 |
+
sep_style=SeparatorStyle.MPT_TWO,
|
| 413 |
+
sep='<|end|>',
|
| 414 |
+
sep2='<|return|>',
|
| 415 |
+
)
|
| 416 |
+
)
|
examples/image1.jpg
ADDED

|
examples/image2.jpg
ADDED

|
Git LFS Details
|
examples/red-panda.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d921c07bb97224d65a37801541d246067f0d506f08723ffa1ad85c217907ccb8
|
| 3 |
+
size 1867237
|
generation_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"transformers_version": "4.55.0"
|
| 4 |
+
}
|
model-00001-of-00009.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2f78b8941ff874279f4fa3abb4f6ce11b29548b8074e4bbf2e34d20e4f6f0b2a
|
| 3 |
+
size 4521940256
|
model-00002-of-00009.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cf3798fb7304ef5efcb7d08912b1b3b965a8223389f120224708b08022416913
|
| 3 |
+
size 4939128416
|
model-00003-of-00009.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aa7649d0df0e5428b40fdeca5899cd272c8ece09c22a58661f9cfb78fa5c5af3
|
| 3 |
+
size 4939128416
|
model-00004-of-00009.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ef463f3880b97a66121057a125559af10654aaf06a5b00c38229e87bf6c83e22
|
| 3 |
+
size 4939128448
|
model-00005-of-00009.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4bbc369234a649d76e07d239db39a3c6db4403c28aa78a5a0469db58684dad28
|
| 3 |
+
size 4939128464
|
model-00006-of-00009.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0d9fe4fd787e3dce4230dc0b128428f701f7faab9b82842193bc8d9b0717e99c
|
| 3 |
+
size 4939128464
|
model-00007-of-00009.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ec5dee9863dc5821b34b888b14c67e00db2bba44a680fa9c72509641e432fa2a
|
| 3 |
+
size 4939128464
|
model-00008-of-00009.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:29028e9a7871a30a69d7f241fcda9e24f3408c85a106e4080fb9a8a569695288
|
| 3 |
+
size 4939128464
|
model-00009-of-00009.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c7eabf59337540314a9cb2a0317b73ae4df9ce84b6a01c57cad5e3642ea4b223
|
| 3 |
+
size 3369791600
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,765 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_parameters": 392282304,
|
| 4 |
+
"total_size": 42465537408
|
| 5 |
+
},
|
| 6 |
+
"weight_map": {
|
| 7 |
+
"language_model.lm_head.weight": "model-00009-of-00009.safetensors",
|
| 8 |
+
"language_model.model.embed_tokens.weight": "model-00001-of-00009.safetensors",
|
| 9 |
+
"language_model.model.layers.0.input_layernorm.weight": "model-00001-of-00009.safetensors",
|
| 10 |
+
"language_model.model.layers.0.mlp.experts.down_proj": "model-00001-of-00009.safetensors",
|
| 11 |
+
"language_model.model.layers.0.mlp.experts.down_proj_bias": "model-00001-of-00009.safetensors",
|
| 12 |
+
"language_model.model.layers.0.mlp.experts.gate_up_proj": "model-00001-of-00009.safetensors",
|
| 13 |
+
"language_model.model.layers.0.mlp.experts.gate_up_proj_bias": "model-00001-of-00009.safetensors",
|
| 14 |
+
"language_model.model.layers.0.mlp.router.bias": "model-00001-of-00009.safetensors",
|
| 15 |
+
"language_model.model.layers.0.mlp.router.weight": "model-00001-of-00009.safetensors",
|
| 16 |
+
"language_model.model.layers.0.post_attention_layernorm.weight": "model-00001-of-00009.safetensors",
|
| 17 |
+
"language_model.model.layers.0.self_attn.k_proj.bias": "model-00001-of-00009.safetensors",
|
| 18 |
+
"language_model.model.layers.0.self_attn.k_proj.weight": "model-00001-of-00009.safetensors",
|
| 19 |
+
"language_model.model.layers.0.self_attn.o_proj.bias": "model-00001-of-00009.safetensors",
|
| 20 |
+
"language_model.model.layers.0.self_attn.o_proj.weight": "model-00001-of-00009.safetensors",
|
| 21 |
+
"language_model.model.layers.0.self_attn.q_proj.bias": "model-00001-of-00009.safetensors",
|
| 22 |
+
"language_model.model.layers.0.self_attn.q_proj.weight": "model-00001-of-00009.safetensors",
|
| 23 |
+
"language_model.model.layers.0.self_attn.sinks": "model-00001-of-00009.safetensors",
|
| 24 |
+
"language_model.model.layers.0.self_attn.v_proj.bias": "model-00001-of-00009.safetensors",
|
| 25 |
+
"language_model.model.layers.0.self_attn.v_proj.weight": "model-00001-of-00009.safetensors",
|
| 26 |
+
"language_model.model.layers.1.input_layernorm.weight": "model-00002-of-00009.safetensors",
|
| 27 |
+
"language_model.model.layers.1.mlp.experts.down_proj": "model-00002-of-00009.safetensors",
|
| 28 |
+
"language_model.model.layers.1.mlp.experts.down_proj_bias": "model-00002-of-00009.safetensors",
|
| 29 |
+
"language_model.model.layers.1.mlp.experts.gate_up_proj": "model-00001-of-00009.safetensors",
|
| 30 |
+
"language_model.model.layers.1.mlp.experts.gate_up_proj_bias": "model-00001-of-00009.safetensors",
|
| 31 |
+
"language_model.model.layers.1.mlp.router.bias": "model-00001-of-00009.safetensors",
|
| 32 |
+
"language_model.model.layers.1.mlp.router.weight": "model-00001-of-00009.safetensors",
|
| 33 |
+
"language_model.model.layers.1.post_attention_layernorm.weight": "model-00002-of-00009.safetensors",
|
| 34 |
+
"language_model.model.layers.1.self_attn.k_proj.bias": "model-00001-of-00009.safetensors",
|
| 35 |
+
"language_model.model.layers.1.self_attn.k_proj.weight": "model-00001-of-00009.safetensors",
|
| 36 |
+
"language_model.model.layers.1.self_attn.o_proj.bias": "model-00001-of-00009.safetensors",
|
| 37 |
+
"language_model.model.layers.1.self_attn.o_proj.weight": "model-00001-of-00009.safetensors",
|
| 38 |
+
"language_model.model.layers.1.self_attn.q_proj.bias": "model-00001-of-00009.safetensors",
|
| 39 |
+
"language_model.model.layers.1.self_attn.q_proj.weight": "model-00001-of-00009.safetensors",
|
| 40 |
+
"language_model.model.layers.1.self_attn.sinks": "model-00001-of-00009.safetensors",
|
| 41 |
+
"language_model.model.layers.1.self_attn.v_proj.bias": "model-00001-of-00009.safetensors",
|
| 42 |
+
"language_model.model.layers.1.self_attn.v_proj.weight": "model-00001-of-00009.safetensors",
|
| 43 |
+
"language_model.model.layers.10.input_layernorm.weight": "model-00005-of-00009.safetensors",
|
| 44 |
+
"language_model.model.layers.10.mlp.experts.down_proj": "model-00005-of-00009.safetensors",
|
| 45 |
+
"language_model.model.layers.10.mlp.experts.down_proj_bias": "model-00005-of-00009.safetensors",
|
| 46 |
+
"language_model.model.layers.10.mlp.experts.gate_up_proj": "model-00004-of-00009.safetensors",
|
| 47 |
+
"language_model.model.layers.10.mlp.experts.gate_up_proj_bias": "model-00004-of-00009.safetensors",
|
| 48 |
+
"language_model.model.layers.10.mlp.router.bias": "model-00004-of-00009.safetensors",
|
| 49 |
+
"language_model.model.layers.10.mlp.router.weight": "model-00004-of-00009.safetensors",
|
| 50 |
+
"language_model.model.layers.10.post_attention_layernorm.weight": "model-00005-of-00009.safetensors",
|
| 51 |
+
"language_model.model.layers.10.self_attn.k_proj.bias": "model-00004-of-00009.safetensors",
|
| 52 |
+
"language_model.model.layers.10.self_attn.k_proj.weight": "model-00004-of-00009.safetensors",
|
| 53 |
+
"language_model.model.layers.10.self_attn.o_proj.bias": "model-00004-of-00009.safetensors",
|
| 54 |
+
"language_model.model.layers.10.self_attn.o_proj.weight": "model-00004-of-00009.safetensors",
|
| 55 |
+
"language_model.model.layers.10.self_attn.q_proj.bias": "model-00004-of-00009.safetensors",
|
| 56 |
+
"language_model.model.layers.10.self_attn.q_proj.weight": "model-00004-of-00009.safetensors",
|
| 57 |
+
"language_model.model.layers.10.self_attn.sinks": "model-00004-of-00009.safetensors",
|
| 58 |
+
"language_model.model.layers.10.self_attn.v_proj.bias": "model-00004-of-00009.safetensors",
|
| 59 |
+
"language_model.model.layers.10.self_attn.v_proj.weight": "model-00004-of-00009.safetensors",
|
| 60 |
+
"language_model.model.layers.11.input_layernorm.weight": "model-00005-of-00009.safetensors",
|
| 61 |
+
"language_model.model.layers.11.mlp.experts.down_proj": "model-00005-of-00009.safetensors",
|
| 62 |
+
"language_model.model.layers.11.mlp.experts.down_proj_bias": "model-00005-of-00009.safetensors",
|
| 63 |
+
"language_model.model.layers.11.mlp.experts.gate_up_proj": "model-00005-of-00009.safetensors",
|
| 64 |
+
"language_model.model.layers.11.mlp.experts.gate_up_proj_bias": "model-00005-of-00009.safetensors",
|
| 65 |
+
"language_model.model.layers.11.mlp.router.bias": "model-00005-of-00009.safetensors",
|
| 66 |
+
"language_model.model.layers.11.mlp.router.weight": "model-00005-of-00009.safetensors",
|
| 67 |
+
"language_model.model.layers.11.post_attention_layernorm.weight": "model-00005-of-00009.safetensors",
|
| 68 |
+
"language_model.model.layers.11.self_attn.k_proj.bias": "model-00005-of-00009.safetensors",
|
| 69 |
+
"language_model.model.layers.11.self_attn.k_proj.weight": "model-00005-of-00009.safetensors",
|
| 70 |
+
"language_model.model.layers.11.self_attn.o_proj.bias": "model-00005-of-00009.safetensors",
|
| 71 |
+
"language_model.model.layers.11.self_attn.o_proj.weight": "model-00005-of-00009.safetensors",
|
| 72 |
+
"language_model.model.layers.11.self_attn.q_proj.bias": "model-00005-of-00009.safetensors",
|
| 73 |
+
"language_model.model.layers.11.self_attn.q_proj.weight": "model-00005-of-00009.safetensors",
|
| 74 |
+
"language_model.model.layers.11.self_attn.sinks": "model-00005-of-00009.safetensors",
|
| 75 |
+
"language_model.model.layers.11.self_attn.v_proj.bias": "model-00005-of-00009.safetensors",
|
| 76 |
+
"language_model.model.layers.11.self_attn.v_proj.weight": "model-00005-of-00009.safetensors",
|
| 77 |
+
"language_model.model.layers.12.input_layernorm.weight": "model-00005-of-00009.safetensors",
|
| 78 |
+
"language_model.model.layers.12.mlp.experts.down_proj": "model-00005-of-00009.safetensors",
|
| 79 |
+
"language_model.model.layers.12.mlp.experts.down_proj_bias": "model-00005-of-00009.safetensors",
|
| 80 |
+
"language_model.model.layers.12.mlp.experts.gate_up_proj": "model-00005-of-00009.safetensors",
|
| 81 |
+
"language_model.model.layers.12.mlp.experts.gate_up_proj_bias": "model-00005-of-00009.safetensors",
|
| 82 |
+
"language_model.model.layers.12.mlp.router.bias": "model-00005-of-00009.safetensors",
|
| 83 |
+
"language_model.model.layers.12.mlp.router.weight": "model-00005-of-00009.safetensors",
|
| 84 |
+
"language_model.model.layers.12.post_attention_layernorm.weight": "model-00005-of-00009.safetensors",
|
| 85 |
+
"language_model.model.layers.12.self_attn.k_proj.bias": "model-00005-of-00009.safetensors",
|
| 86 |
+
"language_model.model.layers.12.self_attn.k_proj.weight": "model-00005-of-00009.safetensors",
|
| 87 |
+
"language_model.model.layers.12.self_attn.o_proj.bias": "model-00005-of-00009.safetensors",
|
| 88 |
+
"language_model.model.layers.12.self_attn.o_proj.weight": "model-00005-of-00009.safetensors",
|
| 89 |
+
"language_model.model.layers.12.self_attn.q_proj.bias": "model-00005-of-00009.safetensors",
|
| 90 |
+
"language_model.model.layers.12.self_attn.q_proj.weight": "model-00005-of-00009.safetensors",
|
| 91 |
+
"language_model.model.layers.12.self_attn.sinks": "model-00005-of-00009.safetensors",
|
| 92 |
+
"language_model.model.layers.12.self_attn.v_proj.bias": "model-00005-of-00009.safetensors",
|
| 93 |
+
"language_model.model.layers.12.self_attn.v_proj.weight": "model-00005-of-00009.safetensors",
|
| 94 |
+
"language_model.model.layers.13.input_layernorm.weight": "model-00006-of-00009.safetensors",
|
| 95 |
+
"language_model.model.layers.13.mlp.experts.down_proj": "model-00006-of-00009.safetensors",
|
| 96 |
+
"language_model.model.layers.13.mlp.experts.down_proj_bias": "model-00006-of-00009.safetensors",
|
| 97 |
+
"language_model.model.layers.13.mlp.experts.gate_up_proj": "model-00005-of-00009.safetensors",
|
| 98 |
+
"language_model.model.layers.13.mlp.experts.gate_up_proj_bias": "model-00005-of-00009.safetensors",
|
| 99 |
+
"language_model.model.layers.13.mlp.router.bias": "model-00005-of-00009.safetensors",
|
| 100 |
+
"language_model.model.layers.13.mlp.router.weight": "model-00005-of-00009.safetensors",
|
| 101 |
+
"language_model.model.layers.13.post_attention_layernorm.weight": "model-00006-of-00009.safetensors",
|
| 102 |
+
"language_model.model.layers.13.self_attn.k_proj.bias": "model-00005-of-00009.safetensors",
|
| 103 |
+
"language_model.model.layers.13.self_attn.k_proj.weight": "model-00005-of-00009.safetensors",
|
| 104 |
+
"language_model.model.layers.13.self_attn.o_proj.bias": "model-00005-of-00009.safetensors",
|
| 105 |
+
"language_model.model.layers.13.self_attn.o_proj.weight": "model-00005-of-00009.safetensors",
|
| 106 |
+
"language_model.model.layers.13.self_attn.q_proj.bias": "model-00005-of-00009.safetensors",
|
| 107 |
+
"language_model.model.layers.13.self_attn.q_proj.weight": "model-00005-of-00009.safetensors",
|
| 108 |
+
"language_model.model.layers.13.self_attn.sinks": "model-00005-of-00009.safetensors",
|
| 109 |
+
"language_model.model.layers.13.self_attn.v_proj.bias": "model-00005-of-00009.safetensors",
|
| 110 |
+
"language_model.model.layers.13.self_attn.v_proj.weight": "model-00005-of-00009.safetensors",
|
| 111 |
+
"language_model.model.layers.14.input_layernorm.weight": "model-00006-of-00009.safetensors",
|
| 112 |
+
"language_model.model.layers.14.mlp.experts.down_proj": "model-00006-of-00009.safetensors",
|
| 113 |
+
"language_model.model.layers.14.mlp.experts.down_proj_bias": "model-00006-of-00009.safetensors",
|
| 114 |
+
"language_model.model.layers.14.mlp.experts.gate_up_proj": "model-00006-of-00009.safetensors",
|
| 115 |
+
"language_model.model.layers.14.mlp.experts.gate_up_proj_bias": "model-00006-of-00009.safetensors",
|
| 116 |
+
"language_model.model.layers.14.mlp.router.bias": "model-00006-of-00009.safetensors",
|
| 117 |
+
"language_model.model.layers.14.mlp.router.weight": "model-00006-of-00009.safetensors",
|
| 118 |
+
"language_model.model.layers.14.post_attention_layernorm.weight": "model-00006-of-00009.safetensors",
|
| 119 |
+
"language_model.model.layers.14.self_attn.k_proj.bias": "model-00006-of-00009.safetensors",
|
| 120 |
+
"language_model.model.layers.14.self_attn.k_proj.weight": "model-00006-of-00009.safetensors",
|
| 121 |
+
"language_model.model.layers.14.self_attn.o_proj.bias": "model-00006-of-00009.safetensors",
|
| 122 |
+
"language_model.model.layers.14.self_attn.o_proj.weight": "model-00006-of-00009.safetensors",
|
| 123 |
+
"language_model.model.layers.14.self_attn.q_proj.bias": "model-00006-of-00009.safetensors",
|
| 124 |
+
"language_model.model.layers.14.self_attn.q_proj.weight": "model-00006-of-00009.safetensors",
|
| 125 |
+
"language_model.model.layers.14.self_attn.sinks": "model-00006-of-00009.safetensors",
|
| 126 |
+
"language_model.model.layers.14.self_attn.v_proj.bias": "model-00006-of-00009.safetensors",
|
| 127 |
+
"language_model.model.layers.14.self_attn.v_proj.weight": "model-00006-of-00009.safetensors",
|
| 128 |
+
"language_model.model.layers.15.input_layernorm.weight": "model-00006-of-00009.safetensors",
|
| 129 |
+
"language_model.model.layers.15.mlp.experts.down_proj": "model-00006-of-00009.safetensors",
|
| 130 |
+
"language_model.model.layers.15.mlp.experts.down_proj_bias": "model-00006-of-00009.safetensors",
|
| 131 |
+
"language_model.model.layers.15.mlp.experts.gate_up_proj": "model-00006-of-00009.safetensors",
|
| 132 |
+
"language_model.model.layers.15.mlp.experts.gate_up_proj_bias": "model-00006-of-00009.safetensors",
|
| 133 |
+
"language_model.model.layers.15.mlp.router.bias": "model-00006-of-00009.safetensors",
|
| 134 |
+
"language_model.model.layers.15.mlp.router.weight": "model-00006-of-00009.safetensors",
|
| 135 |
+
"language_model.model.layers.15.post_attention_layernorm.weight": "model-00006-of-00009.safetensors",
|
| 136 |
+
"language_model.model.layers.15.self_attn.k_proj.bias": "model-00006-of-00009.safetensors",
|
| 137 |
+
"language_model.model.layers.15.self_attn.k_proj.weight": "model-00006-of-00009.safetensors",
|
| 138 |
+
"language_model.model.layers.15.self_attn.o_proj.bias": "model-00006-of-00009.safetensors",
|
| 139 |
+
"language_model.model.layers.15.self_attn.o_proj.weight": "model-00006-of-00009.safetensors",
|
| 140 |
+
"language_model.model.layers.15.self_attn.q_proj.bias": "model-00006-of-00009.safetensors",
|
| 141 |
+
"language_model.model.layers.15.self_attn.q_proj.weight": "model-00006-of-00009.safetensors",
|
| 142 |
+
"language_model.model.layers.15.self_attn.sinks": "model-00006-of-00009.safetensors",
|
| 143 |
+
"language_model.model.layers.15.self_attn.v_proj.bias": "model-00006-of-00009.safetensors",
|
| 144 |
+
"language_model.model.layers.15.self_attn.v_proj.weight": "model-00006-of-00009.safetensors",
|
| 145 |
+
"language_model.model.layers.16.input_layernorm.weight": "model-00007-of-00009.safetensors",
|
| 146 |
+
"language_model.model.layers.16.mlp.experts.down_proj": "model-00007-of-00009.safetensors",
|
| 147 |
+
"language_model.model.layers.16.mlp.experts.down_proj_bias": "model-00007-of-00009.safetensors",
|
| 148 |
+
"language_model.model.layers.16.mlp.experts.gate_up_proj": "model-00006-of-00009.safetensors",
|
| 149 |
+
"language_model.model.layers.16.mlp.experts.gate_up_proj_bias": "model-00006-of-00009.safetensors",
|
| 150 |
+
"language_model.model.layers.16.mlp.router.bias": "model-00006-of-00009.safetensors",
|
| 151 |
+
"language_model.model.layers.16.mlp.router.weight": "model-00006-of-00009.safetensors",
|
| 152 |
+
"language_model.model.layers.16.post_attention_layernorm.weight": "model-00007-of-00009.safetensors",
|
| 153 |
+
"language_model.model.layers.16.self_attn.k_proj.bias": "model-00006-of-00009.safetensors",
|
| 154 |
+
"language_model.model.layers.16.self_attn.k_proj.weight": "model-00006-of-00009.safetensors",
|
| 155 |
+
"language_model.model.layers.16.self_attn.o_proj.bias": "model-00006-of-00009.safetensors",
|
| 156 |
+
"language_model.model.layers.16.self_attn.o_proj.weight": "model-00006-of-00009.safetensors",
|
| 157 |
+
"language_model.model.layers.16.self_attn.q_proj.bias": "model-00006-of-00009.safetensors",
|
| 158 |
+
"language_model.model.layers.16.self_attn.q_proj.weight": "model-00006-of-00009.safetensors",
|
| 159 |
+
"language_model.model.layers.16.self_attn.sinks": "model-00006-of-00009.safetensors",
|
| 160 |
+
"language_model.model.layers.16.self_attn.v_proj.bias": "model-00006-of-00009.safetensors",
|
| 161 |
+
"language_model.model.layers.16.self_attn.v_proj.weight": "model-00006-of-00009.safetensors",
|
| 162 |
+
"language_model.model.layers.17.input_layernorm.weight": "model-00007-of-00009.safetensors",
|
| 163 |
+
"language_model.model.layers.17.mlp.experts.down_proj": "model-00007-of-00009.safetensors",
|
| 164 |
+
"language_model.model.layers.17.mlp.experts.down_proj_bias": "model-00007-of-00009.safetensors",
|
| 165 |
+
"language_model.model.layers.17.mlp.experts.gate_up_proj": "model-00007-of-00009.safetensors",
|
| 166 |
+
"language_model.model.layers.17.mlp.experts.gate_up_proj_bias": "model-00007-of-00009.safetensors",
|
| 167 |
+
"language_model.model.layers.17.mlp.router.bias": "model-00007-of-00009.safetensors",
|
| 168 |
+
"language_model.model.layers.17.mlp.router.weight": "model-00007-of-00009.safetensors",
|
| 169 |
+
"language_model.model.layers.17.post_attention_layernorm.weight": "model-00007-of-00009.safetensors",
|
| 170 |
+
"language_model.model.layers.17.self_attn.k_proj.bias": "model-00007-of-00009.safetensors",
|
| 171 |
+
"language_model.model.layers.17.self_attn.k_proj.weight": "model-00007-of-00009.safetensors",
|
| 172 |
+
"language_model.model.layers.17.self_attn.o_proj.bias": "model-00007-of-00009.safetensors",
|
| 173 |
+
"language_model.model.layers.17.self_attn.o_proj.weight": "model-00007-of-00009.safetensors",
|
| 174 |
+
"language_model.model.layers.17.self_attn.q_proj.bias": "model-00007-of-00009.safetensors",
|
| 175 |
+
"language_model.model.layers.17.self_attn.q_proj.weight": "model-00007-of-00009.safetensors",
|
| 176 |
+
"language_model.model.layers.17.self_attn.sinks": "model-00007-of-00009.safetensors",
|
| 177 |
+
"language_model.model.layers.17.self_attn.v_proj.bias": "model-00007-of-00009.safetensors",
|
| 178 |
+
"language_model.model.layers.17.self_attn.v_proj.weight": "model-00007-of-00009.safetensors",
|
| 179 |
+
"language_model.model.layers.18.input_layernorm.weight": "model-00007-of-00009.safetensors",
|
| 180 |
+
"language_model.model.layers.18.mlp.experts.down_proj": "model-00007-of-00009.safetensors",
|
| 181 |
+
"language_model.model.layers.18.mlp.experts.down_proj_bias": "model-00007-of-00009.safetensors",
|
| 182 |
+
"language_model.model.layers.18.mlp.experts.gate_up_proj": "model-00007-of-00009.safetensors",
|
| 183 |
+
"language_model.model.layers.18.mlp.experts.gate_up_proj_bias": "model-00007-of-00009.safetensors",
|
| 184 |
+
"language_model.model.layers.18.mlp.router.bias": "model-00007-of-00009.safetensors",
|
| 185 |
+
"language_model.model.layers.18.mlp.router.weight": "model-00007-of-00009.safetensors",
|
| 186 |
+
"language_model.model.layers.18.post_attention_layernorm.weight": "model-00007-of-00009.safetensors",
|
| 187 |
+
"language_model.model.layers.18.self_attn.k_proj.bias": "model-00007-of-00009.safetensors",
|
| 188 |
+
"language_model.model.layers.18.self_attn.k_proj.weight": "model-00007-of-00009.safetensors",
|
| 189 |
+
"language_model.model.layers.18.self_attn.o_proj.bias": "model-00007-of-00009.safetensors",
|
| 190 |
+
"language_model.model.layers.18.self_attn.o_proj.weight": "model-00007-of-00009.safetensors",
|
| 191 |
+
"language_model.model.layers.18.self_attn.q_proj.bias": "model-00007-of-00009.safetensors",
|
| 192 |
+
"language_model.model.layers.18.self_attn.q_proj.weight": "model-00007-of-00009.safetensors",
|
| 193 |
+
"language_model.model.layers.18.self_attn.sinks": "model-00007-of-00009.safetensors",
|
| 194 |
+
"language_model.model.layers.18.self_attn.v_proj.bias": "model-00007-of-00009.safetensors",
|
| 195 |
+
"language_model.model.layers.18.self_attn.v_proj.weight": "model-00007-of-00009.safetensors",
|
| 196 |
+
"language_model.model.layers.19.input_layernorm.weight": "model-00008-of-00009.safetensors",
|
| 197 |
+
"language_model.model.layers.19.mlp.experts.down_proj": "model-00008-of-00009.safetensors",
|
| 198 |
+
"language_model.model.layers.19.mlp.experts.down_proj_bias": "model-00008-of-00009.safetensors",
|
| 199 |
+
"language_model.model.layers.19.mlp.experts.gate_up_proj": "model-00007-of-00009.safetensors",
|
| 200 |
+
"language_model.model.layers.19.mlp.experts.gate_up_proj_bias": "model-00007-of-00009.safetensors",
|
| 201 |
+
"language_model.model.layers.19.mlp.router.bias": "model-00007-of-00009.safetensors",
|
| 202 |
+
"language_model.model.layers.19.mlp.router.weight": "model-00007-of-00009.safetensors",
|
| 203 |
+
"language_model.model.layers.19.post_attention_layernorm.weight": "model-00008-of-00009.safetensors",
|
| 204 |
+
"language_model.model.layers.19.self_attn.k_proj.bias": "model-00007-of-00009.safetensors",
|
| 205 |
+
"language_model.model.layers.19.self_attn.k_proj.weight": "model-00007-of-00009.safetensors",
|
| 206 |
+
"language_model.model.layers.19.self_attn.o_proj.bias": "model-00007-of-00009.safetensors",
|
| 207 |
+
"language_model.model.layers.19.self_attn.o_proj.weight": "model-00007-of-00009.safetensors",
|
| 208 |
+
"language_model.model.layers.19.self_attn.q_proj.bias": "model-00007-of-00009.safetensors",
|
| 209 |
+
"language_model.model.layers.19.self_attn.q_proj.weight": "model-00007-of-00009.safetensors",
|
| 210 |
+
"language_model.model.layers.19.self_attn.sinks": "model-00007-of-00009.safetensors",
|
| 211 |
+
"language_model.model.layers.19.self_attn.v_proj.bias": "model-00007-of-00009.safetensors",
|
| 212 |
+
"language_model.model.layers.19.self_attn.v_proj.weight": "model-00007-of-00009.safetensors",
|
| 213 |
+
"language_model.model.layers.2.input_layernorm.weight": "model-00002-of-00009.safetensors",
|
| 214 |
+
"language_model.model.layers.2.mlp.experts.down_proj": "model-00002-of-00009.safetensors",
|
| 215 |
+
"language_model.model.layers.2.mlp.experts.down_proj_bias": "model-00002-of-00009.safetensors",
|
| 216 |
+
"language_model.model.layers.2.mlp.experts.gate_up_proj": "model-00002-of-00009.safetensors",
|
| 217 |
+
"language_model.model.layers.2.mlp.experts.gate_up_proj_bias": "model-00002-of-00009.safetensors",
|
| 218 |
+
"language_model.model.layers.2.mlp.router.bias": "model-00002-of-00009.safetensors",
|
| 219 |
+
"language_model.model.layers.2.mlp.router.weight": "model-00002-of-00009.safetensors",
|
| 220 |
+
"language_model.model.layers.2.post_attention_layernorm.weight": "model-00002-of-00009.safetensors",
|
| 221 |
+
"language_model.model.layers.2.self_attn.k_proj.bias": "model-00002-of-00009.safetensors",
|
| 222 |
+
"language_model.model.layers.2.self_attn.k_proj.weight": "model-00002-of-00009.safetensors",
|
| 223 |
+
"language_model.model.layers.2.self_attn.o_proj.bias": "model-00002-of-00009.safetensors",
|
| 224 |
+
"language_model.model.layers.2.self_attn.o_proj.weight": "model-00002-of-00009.safetensors",
|
| 225 |
+
"language_model.model.layers.2.self_attn.q_proj.bias": "model-00002-of-00009.safetensors",
|
| 226 |
+
"language_model.model.layers.2.self_attn.q_proj.weight": "model-00002-of-00009.safetensors",
|
| 227 |
+
"language_model.model.layers.2.self_attn.sinks": "model-00002-of-00009.safetensors",
|
| 228 |
+
"language_model.model.layers.2.self_attn.v_proj.bias": "model-00002-of-00009.safetensors",
|
| 229 |
+
"language_model.model.layers.2.self_attn.v_proj.weight": "model-00002-of-00009.safetensors",
|
| 230 |
+
"language_model.model.layers.20.input_layernorm.weight": "model-00008-of-00009.safetensors",
|
| 231 |
+
"language_model.model.layers.20.mlp.experts.down_proj": "model-00008-of-00009.safetensors",
|
| 232 |
+
"language_model.model.layers.20.mlp.experts.down_proj_bias": "model-00008-of-00009.safetensors",
|
| 233 |
+
"language_model.model.layers.20.mlp.experts.gate_up_proj": "model-00008-of-00009.safetensors",
|
| 234 |
+
"language_model.model.layers.20.mlp.experts.gate_up_proj_bias": "model-00008-of-00009.safetensors",
|
| 235 |
+
"language_model.model.layers.20.mlp.router.bias": "model-00008-of-00009.safetensors",
|
| 236 |
+
"language_model.model.layers.20.mlp.router.weight": "model-00008-of-00009.safetensors",
|
| 237 |
+
"language_model.model.layers.20.post_attention_layernorm.weight": "model-00008-of-00009.safetensors",
|
| 238 |
+
"language_model.model.layers.20.self_attn.k_proj.bias": "model-00008-of-00009.safetensors",
|
| 239 |
+
"language_model.model.layers.20.self_attn.k_proj.weight": "model-00008-of-00009.safetensors",
|
| 240 |
+
"language_model.model.layers.20.self_attn.o_proj.bias": "model-00008-of-00009.safetensors",
|
| 241 |
+
"language_model.model.layers.20.self_attn.o_proj.weight": "model-00008-of-00009.safetensors",
|
| 242 |
+
"language_model.model.layers.20.self_attn.q_proj.bias": "model-00008-of-00009.safetensors",
|
| 243 |
+
"language_model.model.layers.20.self_attn.q_proj.weight": "model-00008-of-00009.safetensors",
|
| 244 |
+
"language_model.model.layers.20.self_attn.sinks": "model-00008-of-00009.safetensors",
|
| 245 |
+
"language_model.model.layers.20.self_attn.v_proj.bias": "model-00008-of-00009.safetensors",
|
| 246 |
+
"language_model.model.layers.20.self_attn.v_proj.weight": "model-00008-of-00009.safetensors",
|
| 247 |
+
"language_model.model.layers.21.input_layernorm.weight": "model-00008-of-00009.safetensors",
|
| 248 |
+
"language_model.model.layers.21.mlp.experts.down_proj": "model-00008-of-00009.safetensors",
|
| 249 |
+
"language_model.model.layers.21.mlp.experts.down_proj_bias": "model-00008-of-00009.safetensors",
|
| 250 |
+
"language_model.model.layers.21.mlp.experts.gate_up_proj": "model-00008-of-00009.safetensors",
|
| 251 |
+
"language_model.model.layers.21.mlp.experts.gate_up_proj_bias": "model-00008-of-00009.safetensors",
|
| 252 |
+
"language_model.model.layers.21.mlp.router.bias": "model-00008-of-00009.safetensors",
|
| 253 |
+
"language_model.model.layers.21.mlp.router.weight": "model-00008-of-00009.safetensors",
|
| 254 |
+
"language_model.model.layers.21.post_attention_layernorm.weight": "model-00008-of-00009.safetensors",
|
| 255 |
+
"language_model.model.layers.21.self_attn.k_proj.bias": "model-00008-of-00009.safetensors",
|
| 256 |
+
"language_model.model.layers.21.self_attn.k_proj.weight": "model-00008-of-00009.safetensors",
|
| 257 |
+
"language_model.model.layers.21.self_attn.o_proj.bias": "model-00008-of-00009.safetensors",
|
| 258 |
+
"language_model.model.layers.21.self_attn.o_proj.weight": "model-00008-of-00009.safetensors",
|
| 259 |
+
"language_model.model.layers.21.self_attn.q_proj.bias": "model-00008-of-00009.safetensors",
|
| 260 |
+
"language_model.model.layers.21.self_attn.q_proj.weight": "model-00008-of-00009.safetensors",
|
| 261 |
+
"language_model.model.layers.21.self_attn.sinks": "model-00008-of-00009.safetensors",
|
| 262 |
+
"language_model.model.layers.21.self_attn.v_proj.bias": "model-00008-of-00009.safetensors",
|
| 263 |
+
"language_model.model.layers.21.self_attn.v_proj.weight": "model-00008-of-00009.safetensors",
|
| 264 |
+
"language_model.model.layers.22.input_layernorm.weight": "model-00009-of-00009.safetensors",
|
| 265 |
+
"language_model.model.layers.22.mlp.experts.down_proj": "model-00009-of-00009.safetensors",
|
| 266 |
+
"language_model.model.layers.22.mlp.experts.down_proj_bias": "model-00009-of-00009.safetensors",
|
| 267 |
+
"language_model.model.layers.22.mlp.experts.gate_up_proj": "model-00008-of-00009.safetensors",
|
| 268 |
+
"language_model.model.layers.22.mlp.experts.gate_up_proj_bias": "model-00008-of-00009.safetensors",
|
| 269 |
+
"language_model.model.layers.22.mlp.router.bias": "model-00008-of-00009.safetensors",
|
| 270 |
+
"language_model.model.layers.22.mlp.router.weight": "model-00008-of-00009.safetensors",
|
| 271 |
+
"language_model.model.layers.22.post_attention_layernorm.weight": "model-00009-of-00009.safetensors",
|
| 272 |
+
"language_model.model.layers.22.self_attn.k_proj.bias": "model-00008-of-00009.safetensors",
|
| 273 |
+
"language_model.model.layers.22.self_attn.k_proj.weight": "model-00008-of-00009.safetensors",
|
| 274 |
+
"language_model.model.layers.22.self_attn.o_proj.bias": "model-00008-of-00009.safetensors",
|
| 275 |
+
"language_model.model.layers.22.self_attn.o_proj.weight": "model-00008-of-00009.safetensors",
|
| 276 |
+
"language_model.model.layers.22.self_attn.q_proj.bias": "model-00008-of-00009.safetensors",
|
| 277 |
+
"language_model.model.layers.22.self_attn.q_proj.weight": "model-00008-of-00009.safetensors",
|
| 278 |
+
"language_model.model.layers.22.self_attn.sinks": "model-00008-of-00009.safetensors",
|
| 279 |
+
"language_model.model.layers.22.self_attn.v_proj.bias": "model-00008-of-00009.safetensors",
|
| 280 |
+
"language_model.model.layers.22.self_attn.v_proj.weight": "model-00008-of-00009.safetensors",
|
| 281 |
+
"language_model.model.layers.23.input_layernorm.weight": "model-00009-of-00009.safetensors",
|
| 282 |
+
"language_model.model.layers.23.mlp.experts.down_proj": "model-00009-of-00009.safetensors",
|
| 283 |
+
"language_model.model.layers.23.mlp.experts.down_proj_bias": "model-00009-of-00009.safetensors",
|
| 284 |
+
"language_model.model.layers.23.mlp.experts.gate_up_proj": "model-00009-of-00009.safetensors",
|
| 285 |
+
"language_model.model.layers.23.mlp.experts.gate_up_proj_bias": "model-00009-of-00009.safetensors",
|
| 286 |
+
"language_model.model.layers.23.mlp.router.bias": "model-00009-of-00009.safetensors",
|
| 287 |
+
"language_model.model.layers.23.mlp.router.weight": "model-00009-of-00009.safetensors",
|
| 288 |
+
"language_model.model.layers.23.post_attention_layernorm.weight": "model-00009-of-00009.safetensors",
|
| 289 |
+
"language_model.model.layers.23.self_attn.k_proj.bias": "model-00009-of-00009.safetensors",
|
| 290 |
+
"language_model.model.layers.23.self_attn.k_proj.weight": "model-00009-of-00009.safetensors",
|
| 291 |
+
"language_model.model.layers.23.self_attn.o_proj.bias": "model-00009-of-00009.safetensors",
|
| 292 |
+
"language_model.model.layers.23.self_attn.o_proj.weight": "model-00009-of-00009.safetensors",
|
| 293 |
+
"language_model.model.layers.23.self_attn.q_proj.bias": "model-00009-of-00009.safetensors",
|
| 294 |
+
"language_model.model.layers.23.self_attn.q_proj.weight": "model-00009-of-00009.safetensors",
|
| 295 |
+
"language_model.model.layers.23.self_attn.sinks": "model-00009-of-00009.safetensors",
|
| 296 |
+
"language_model.model.layers.23.self_attn.v_proj.bias": "model-00009-of-00009.safetensors",
|
| 297 |
+
"language_model.model.layers.23.self_attn.v_proj.weight": "model-00009-of-00009.safetensors",
|
| 298 |
+
"language_model.model.layers.3.input_layernorm.weight": "model-00002-of-00009.safetensors",
|
| 299 |
+
"language_model.model.layers.3.mlp.experts.down_proj": "model-00002-of-00009.safetensors",
|
| 300 |
+
"language_model.model.layers.3.mlp.experts.down_proj_bias": "model-00002-of-00009.safetensors",
|
| 301 |
+
"language_model.model.layers.3.mlp.experts.gate_up_proj": "model-00002-of-00009.safetensors",
|
| 302 |
+
"language_model.model.layers.3.mlp.experts.gate_up_proj_bias": "model-00002-of-00009.safetensors",
|
| 303 |
+
"language_model.model.layers.3.mlp.router.bias": "model-00002-of-00009.safetensors",
|
| 304 |
+
"language_model.model.layers.3.mlp.router.weight": "model-00002-of-00009.safetensors",
|
| 305 |
+
"language_model.model.layers.3.post_attention_layernorm.weight": "model-00002-of-00009.safetensors",
|
| 306 |
+
"language_model.model.layers.3.self_attn.k_proj.bias": "model-00002-of-00009.safetensors",
|
| 307 |
+
"language_model.model.layers.3.self_attn.k_proj.weight": "model-00002-of-00009.safetensors",
|
| 308 |
+
"language_model.model.layers.3.self_attn.o_proj.bias": "model-00002-of-00009.safetensors",
|
| 309 |
+
"language_model.model.layers.3.self_attn.o_proj.weight": "model-00002-of-00009.safetensors",
|
| 310 |
+
"language_model.model.layers.3.self_attn.q_proj.bias": "model-00002-of-00009.safetensors",
|
| 311 |
+
"language_model.model.layers.3.self_attn.q_proj.weight": "model-00002-of-00009.safetensors",
|
| 312 |
+
"language_model.model.layers.3.self_attn.sinks": "model-00002-of-00009.safetensors",
|
| 313 |
+
"language_model.model.layers.3.self_attn.v_proj.bias": "model-00002-of-00009.safetensors",
|
| 314 |
+
"language_model.model.layers.3.self_attn.v_proj.weight": "model-00002-of-00009.safetensors",
|
| 315 |
+
"language_model.model.layers.4.input_layernorm.weight": "model-00003-of-00009.safetensors",
|
| 316 |
+
"language_model.model.layers.4.mlp.experts.down_proj": "model-00003-of-00009.safetensors",
|
| 317 |
+
"language_model.model.layers.4.mlp.experts.down_proj_bias": "model-00003-of-00009.safetensors",
|
| 318 |
+
"language_model.model.layers.4.mlp.experts.gate_up_proj": "model-00002-of-00009.safetensors",
|
| 319 |
+
"language_model.model.layers.4.mlp.experts.gate_up_proj_bias": "model-00002-of-00009.safetensors",
|
| 320 |
+
"language_model.model.layers.4.mlp.router.bias": "model-00002-of-00009.safetensors",
|
| 321 |
+
"language_model.model.layers.4.mlp.router.weight": "model-00002-of-00009.safetensors",
|
| 322 |
+
"language_model.model.layers.4.post_attention_layernorm.weight": "model-00003-of-00009.safetensors",
|
| 323 |
+
"language_model.model.layers.4.self_attn.k_proj.bias": "model-00002-of-00009.safetensors",
|
| 324 |
+
"language_model.model.layers.4.self_attn.k_proj.weight": "model-00002-of-00009.safetensors",
|
| 325 |
+
"language_model.model.layers.4.self_attn.o_proj.bias": "model-00002-of-00009.safetensors",
|
| 326 |
+
"language_model.model.layers.4.self_attn.o_proj.weight": "model-00002-of-00009.safetensors",
|
| 327 |
+
"language_model.model.layers.4.self_attn.q_proj.bias": "model-00002-of-00009.safetensors",
|
| 328 |
+
"language_model.model.layers.4.self_attn.q_proj.weight": "model-00002-of-00009.safetensors",
|
| 329 |
+
"language_model.model.layers.4.self_attn.sinks": "model-00002-of-00009.safetensors",
|
| 330 |
+
"language_model.model.layers.4.self_attn.v_proj.bias": "model-00002-of-00009.safetensors",
|
| 331 |
+
"language_model.model.layers.4.self_attn.v_proj.weight": "model-00002-of-00009.safetensors",
|
| 332 |
+
"language_model.model.layers.5.input_layernorm.weight": "model-00003-of-00009.safetensors",
|
| 333 |
+
"language_model.model.layers.5.mlp.experts.down_proj": "model-00003-of-00009.safetensors",
|
| 334 |
+
"language_model.model.layers.5.mlp.experts.down_proj_bias": "model-00003-of-00009.safetensors",
|
| 335 |
+
"language_model.model.layers.5.mlp.experts.gate_up_proj": "model-00003-of-00009.safetensors",
|
| 336 |
+
"language_model.model.layers.5.mlp.experts.gate_up_proj_bias": "model-00003-of-00009.safetensors",
|
| 337 |
+
"language_model.model.layers.5.mlp.router.bias": "model-00003-of-00009.safetensors",
|
| 338 |
+
"language_model.model.layers.5.mlp.router.weight": "model-00003-of-00009.safetensors",
|
| 339 |
+
"language_model.model.layers.5.post_attention_layernorm.weight": "model-00003-of-00009.safetensors",
|
| 340 |
+
"language_model.model.layers.5.self_attn.k_proj.bias": "model-00003-of-00009.safetensors",
|
| 341 |
+
"language_model.model.layers.5.self_attn.k_proj.weight": "model-00003-of-00009.safetensors",
|
| 342 |
+
"language_model.model.layers.5.self_attn.o_proj.bias": "model-00003-of-00009.safetensors",
|
| 343 |
+
"language_model.model.layers.5.self_attn.o_proj.weight": "model-00003-of-00009.safetensors",
|
| 344 |
+
"language_model.model.layers.5.self_attn.q_proj.bias": "model-00003-of-00009.safetensors",
|
| 345 |
+
"language_model.model.layers.5.self_attn.q_proj.weight": "model-00003-of-00009.safetensors",
|
| 346 |
+
"language_model.model.layers.5.self_attn.sinks": "model-00003-of-00009.safetensors",
|
| 347 |
+
"language_model.model.layers.5.self_attn.v_proj.bias": "model-00003-of-00009.safetensors",
|
| 348 |
+
"language_model.model.layers.5.self_attn.v_proj.weight": "model-00003-of-00009.safetensors",
|
| 349 |
+
"language_model.model.layers.6.input_layernorm.weight": "model-00003-of-00009.safetensors",
|
| 350 |
+
"language_model.model.layers.6.mlp.experts.down_proj": "model-00003-of-00009.safetensors",
|
| 351 |
+
"language_model.model.layers.6.mlp.experts.down_proj_bias": "model-00003-of-00009.safetensors",
|
| 352 |
+
"language_model.model.layers.6.mlp.experts.gate_up_proj": "model-00003-of-00009.safetensors",
|
| 353 |
+
"language_model.model.layers.6.mlp.experts.gate_up_proj_bias": "model-00003-of-00009.safetensors",
|
| 354 |
+
"language_model.model.layers.6.mlp.router.bias": "model-00003-of-00009.safetensors",
|
| 355 |
+
"language_model.model.layers.6.mlp.router.weight": "model-00003-of-00009.safetensors",
|
| 356 |
+
"language_model.model.layers.6.post_attention_layernorm.weight": "model-00003-of-00009.safetensors",
|
| 357 |
+
"language_model.model.layers.6.self_attn.k_proj.bias": "model-00003-of-00009.safetensors",
|
| 358 |
+
"language_model.model.layers.6.self_attn.k_proj.weight": "model-00003-of-00009.safetensors",
|
| 359 |
+
"language_model.model.layers.6.self_attn.o_proj.bias": "model-00003-of-00009.safetensors",
|
| 360 |
+
"language_model.model.layers.6.self_attn.o_proj.weight": "model-00003-of-00009.safetensors",
|
| 361 |
+
"language_model.model.layers.6.self_attn.q_proj.bias": "model-00003-of-00009.safetensors",
|
| 362 |
+
"language_model.model.layers.6.self_attn.q_proj.weight": "model-00003-of-00009.safetensors",
|
| 363 |
+
"language_model.model.layers.6.self_attn.sinks": "model-00003-of-00009.safetensors",
|
| 364 |
+
"language_model.model.layers.6.self_attn.v_proj.bias": "model-00003-of-00009.safetensors",
|
| 365 |
+
"language_model.model.layers.6.self_attn.v_proj.weight": "model-00003-of-00009.safetensors",
|
| 366 |
+
"language_model.model.layers.7.input_layernorm.weight": "model-00004-of-00009.safetensors",
|
| 367 |
+
"language_model.model.layers.7.mlp.experts.down_proj": "model-00004-of-00009.safetensors",
|
| 368 |
+
"language_model.model.layers.7.mlp.experts.down_proj_bias": "model-00004-of-00009.safetensors",
|
| 369 |
+
"language_model.model.layers.7.mlp.experts.gate_up_proj": "model-00003-of-00009.safetensors",
|
| 370 |
+
"language_model.model.layers.7.mlp.experts.gate_up_proj_bias": "model-00003-of-00009.safetensors",
|
| 371 |
+
"language_model.model.layers.7.mlp.router.bias": "model-00003-of-00009.safetensors",
|
| 372 |
+
"language_model.model.layers.7.mlp.router.weight": "model-00003-of-00009.safetensors",
|
| 373 |
+
"language_model.model.layers.7.post_attention_layernorm.weight": "model-00004-of-00009.safetensors",
|
| 374 |
+
"language_model.model.layers.7.self_attn.k_proj.bias": "model-00003-of-00009.safetensors",
|
| 375 |
+
"language_model.model.layers.7.self_attn.k_proj.weight": "model-00003-of-00009.safetensors",
|
| 376 |
+
"language_model.model.layers.7.self_attn.o_proj.bias": "model-00003-of-00009.safetensors",
|
| 377 |
+
"language_model.model.layers.7.self_attn.o_proj.weight": "model-00003-of-00009.safetensors",
|
| 378 |
+
"language_model.model.layers.7.self_attn.q_proj.bias": "model-00003-of-00009.safetensors",
|
| 379 |
+
"language_model.model.layers.7.self_attn.q_proj.weight": "model-00003-of-00009.safetensors",
|
| 380 |
+
"language_model.model.layers.7.self_attn.sinks": "model-00003-of-00009.safetensors",
|
| 381 |
+
"language_model.model.layers.7.self_attn.v_proj.bias": "model-00003-of-00009.safetensors",
|
| 382 |
+
"language_model.model.layers.7.self_attn.v_proj.weight": "model-00003-of-00009.safetensors",
|
| 383 |
+
"language_model.model.layers.8.input_layernorm.weight": "model-00004-of-00009.safetensors",
|
| 384 |
+
"language_model.model.layers.8.mlp.experts.down_proj": "model-00004-of-00009.safetensors",
|
| 385 |
+
"language_model.model.layers.8.mlp.experts.down_proj_bias": "model-00004-of-00009.safetensors",
|
| 386 |
+
"language_model.model.layers.8.mlp.experts.gate_up_proj": "model-00004-of-00009.safetensors",
|
| 387 |
+
"language_model.model.layers.8.mlp.experts.gate_up_proj_bias": "model-00004-of-00009.safetensors",
|
| 388 |
+
"language_model.model.layers.8.mlp.router.bias": "model-00004-of-00009.safetensors",
|
| 389 |
+
"language_model.model.layers.8.mlp.router.weight": "model-00004-of-00009.safetensors",
|
| 390 |
+
"language_model.model.layers.8.post_attention_layernorm.weight": "model-00004-of-00009.safetensors",
|
| 391 |
+
"language_model.model.layers.8.self_attn.k_proj.bias": "model-00004-of-00009.safetensors",
|
| 392 |
+
"language_model.model.layers.8.self_attn.k_proj.weight": "model-00004-of-00009.safetensors",
|
| 393 |
+
"language_model.model.layers.8.self_attn.o_proj.bias": "model-00004-of-00009.safetensors",
|
| 394 |
+
"language_model.model.layers.8.self_attn.o_proj.weight": "model-00004-of-00009.safetensors",
|
| 395 |
+
"language_model.model.layers.8.self_attn.q_proj.bias": "model-00004-of-00009.safetensors",
|
| 396 |
+
"language_model.model.layers.8.self_attn.q_proj.weight": "model-00004-of-00009.safetensors",
|
| 397 |
+
"language_model.model.layers.8.self_attn.sinks": "model-00004-of-00009.safetensors",
|
| 398 |
+
"language_model.model.layers.8.self_attn.v_proj.bias": "model-00004-of-00009.safetensors",
|
| 399 |
+
"language_model.model.layers.8.self_attn.v_proj.weight": "model-00004-of-00009.safetensors",
|
| 400 |
+
"language_model.model.layers.9.input_layernorm.weight": "model-00004-of-00009.safetensors",
|
| 401 |
+
"language_model.model.layers.9.mlp.experts.down_proj": "model-00004-of-00009.safetensors",
|
| 402 |
+
"language_model.model.layers.9.mlp.experts.down_proj_bias": "model-00004-of-00009.safetensors",
|
| 403 |
+
"language_model.model.layers.9.mlp.experts.gate_up_proj": "model-00004-of-00009.safetensors",
|
| 404 |
+
"language_model.model.layers.9.mlp.experts.gate_up_proj_bias": "model-00004-of-00009.safetensors",
|
| 405 |
+
"language_model.model.layers.9.mlp.router.bias": "model-00004-of-00009.safetensors",
|
| 406 |
+
"language_model.model.layers.9.mlp.router.weight": "model-00004-of-00009.safetensors",
|
| 407 |
+
"language_model.model.layers.9.post_attention_layernorm.weight": "model-00004-of-00009.safetensors",
|
| 408 |
+
"language_model.model.layers.9.self_attn.k_proj.bias": "model-00004-of-00009.safetensors",
|
| 409 |
+
"language_model.model.layers.9.self_attn.k_proj.weight": "model-00004-of-00009.safetensors",
|
| 410 |
+
"language_model.model.layers.9.self_attn.o_proj.bias": "model-00004-of-00009.safetensors",
|
| 411 |
+
"language_model.model.layers.9.self_attn.o_proj.weight": "model-00004-of-00009.safetensors",
|
| 412 |
+
"language_model.model.layers.9.self_attn.q_proj.bias": "model-00004-of-00009.safetensors",
|
| 413 |
+
"language_model.model.layers.9.self_attn.q_proj.weight": "model-00004-of-00009.safetensors",
|
| 414 |
+
"language_model.model.layers.9.self_attn.sinks": "model-00004-of-00009.safetensors",
|
| 415 |
+
"language_model.model.layers.9.self_attn.v_proj.bias": "model-00004-of-00009.safetensors",
|
| 416 |
+
"language_model.model.layers.9.self_attn.v_proj.weight": "model-00004-of-00009.safetensors",
|
| 417 |
+
"language_model.model.norm.weight": "model-00009-of-00009.safetensors",
|
| 418 |
+
"mlp1.0.bias": "model-00009-of-00009.safetensors",
|
| 419 |
+
"mlp1.0.weight": "model-00009-of-00009.safetensors",
|
| 420 |
+
"mlp1.1.bias": "model-00009-of-00009.safetensors",
|
| 421 |
+
"mlp1.1.weight": "model-00009-of-00009.safetensors",
|
| 422 |
+
"mlp1.3.bias": "model-00009-of-00009.safetensors",
|
| 423 |
+
"mlp1.3.weight": "model-00009-of-00009.safetensors",
|
| 424 |
+
"vision_model.embeddings.class_embedding": "model-00001-of-00009.safetensors",
|
| 425 |
+
"vision_model.embeddings.patch_embedding.bias": "model-00001-of-00009.safetensors",
|
| 426 |
+
"vision_model.embeddings.patch_embedding.weight": "model-00001-of-00009.safetensors",
|
| 427 |
+
"vision_model.embeddings.position_embedding": "model-00001-of-00009.safetensors",
|
| 428 |
+
"vision_model.encoder.layers.0.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 429 |
+
"vision_model.encoder.layers.0.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 430 |
+
"vision_model.encoder.layers.0.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 431 |
+
"vision_model.encoder.layers.0.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 432 |
+
"vision_model.encoder.layers.0.ls1": "model-00001-of-00009.safetensors",
|
| 433 |
+
"vision_model.encoder.layers.0.ls2": "model-00001-of-00009.safetensors",
|
| 434 |
+
"vision_model.encoder.layers.0.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 435 |
+
"vision_model.encoder.layers.0.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 436 |
+
"vision_model.encoder.layers.0.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 437 |
+
"vision_model.encoder.layers.0.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 438 |
+
"vision_model.encoder.layers.0.norm1.bias": "model-00001-of-00009.safetensors",
|
| 439 |
+
"vision_model.encoder.layers.0.norm1.weight": "model-00001-of-00009.safetensors",
|
| 440 |
+
"vision_model.encoder.layers.0.norm2.bias": "model-00001-of-00009.safetensors",
|
| 441 |
+
"vision_model.encoder.layers.0.norm2.weight": "model-00001-of-00009.safetensors",
|
| 442 |
+
"vision_model.encoder.layers.1.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 443 |
+
"vision_model.encoder.layers.1.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 444 |
+
"vision_model.encoder.layers.1.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 445 |
+
"vision_model.encoder.layers.1.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 446 |
+
"vision_model.encoder.layers.1.ls1": "model-00001-of-00009.safetensors",
|
| 447 |
+
"vision_model.encoder.layers.1.ls2": "model-00001-of-00009.safetensors",
|
| 448 |
+
"vision_model.encoder.layers.1.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 449 |
+
"vision_model.encoder.layers.1.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 450 |
+
"vision_model.encoder.layers.1.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 451 |
+
"vision_model.encoder.layers.1.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 452 |
+
"vision_model.encoder.layers.1.norm1.bias": "model-00001-of-00009.safetensors",
|
| 453 |
+
"vision_model.encoder.layers.1.norm1.weight": "model-00001-of-00009.safetensors",
|
| 454 |
+
"vision_model.encoder.layers.1.norm2.bias": "model-00001-of-00009.safetensors",
|
| 455 |
+
"vision_model.encoder.layers.1.norm2.weight": "model-00001-of-00009.safetensors",
|
| 456 |
+
"vision_model.encoder.layers.10.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 457 |
+
"vision_model.encoder.layers.10.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 458 |
+
"vision_model.encoder.layers.10.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 459 |
+
"vision_model.encoder.layers.10.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 460 |
+
"vision_model.encoder.layers.10.ls1": "model-00001-of-00009.safetensors",
|
| 461 |
+
"vision_model.encoder.layers.10.ls2": "model-00001-of-00009.safetensors",
|
| 462 |
+
"vision_model.encoder.layers.10.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 463 |
+
"vision_model.encoder.layers.10.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 464 |
+
"vision_model.encoder.layers.10.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 465 |
+
"vision_model.encoder.layers.10.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 466 |
+
"vision_model.encoder.layers.10.norm1.bias": "model-00001-of-00009.safetensors",
|
| 467 |
+
"vision_model.encoder.layers.10.norm1.weight": "model-00001-of-00009.safetensors",
|
| 468 |
+
"vision_model.encoder.layers.10.norm2.bias": "model-00001-of-00009.safetensors",
|
| 469 |
+
"vision_model.encoder.layers.10.norm2.weight": "model-00001-of-00009.safetensors",
|
| 470 |
+
"vision_model.encoder.layers.11.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 471 |
+
"vision_model.encoder.layers.11.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 472 |
+
"vision_model.encoder.layers.11.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 473 |
+
"vision_model.encoder.layers.11.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 474 |
+
"vision_model.encoder.layers.11.ls1": "model-00001-of-00009.safetensors",
|
| 475 |
+
"vision_model.encoder.layers.11.ls2": "model-00001-of-00009.safetensors",
|
| 476 |
+
"vision_model.encoder.layers.11.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 477 |
+
"vision_model.encoder.layers.11.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 478 |
+
"vision_model.encoder.layers.11.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 479 |
+
"vision_model.encoder.layers.11.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 480 |
+
"vision_model.encoder.layers.11.norm1.bias": "model-00001-of-00009.safetensors",
|
| 481 |
+
"vision_model.encoder.layers.11.norm1.weight": "model-00001-of-00009.safetensors",
|
| 482 |
+
"vision_model.encoder.layers.11.norm2.bias": "model-00001-of-00009.safetensors",
|
| 483 |
+
"vision_model.encoder.layers.11.norm2.weight": "model-00001-of-00009.safetensors",
|
| 484 |
+
"vision_model.encoder.layers.12.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 485 |
+
"vision_model.encoder.layers.12.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 486 |
+
"vision_model.encoder.layers.12.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 487 |
+
"vision_model.encoder.layers.12.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 488 |
+
"vision_model.encoder.layers.12.ls1": "model-00001-of-00009.safetensors",
|
| 489 |
+
"vision_model.encoder.layers.12.ls2": "model-00001-of-00009.safetensors",
|
| 490 |
+
"vision_model.encoder.layers.12.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 491 |
+
"vision_model.encoder.layers.12.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 492 |
+
"vision_model.encoder.layers.12.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 493 |
+
"vision_model.encoder.layers.12.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 494 |
+
"vision_model.encoder.layers.12.norm1.bias": "model-00001-of-00009.safetensors",
|
| 495 |
+
"vision_model.encoder.layers.12.norm1.weight": "model-00001-of-00009.safetensors",
|
| 496 |
+
"vision_model.encoder.layers.12.norm2.bias": "model-00001-of-00009.safetensors",
|
| 497 |
+
"vision_model.encoder.layers.12.norm2.weight": "model-00001-of-00009.safetensors",
|
| 498 |
+
"vision_model.encoder.layers.13.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 499 |
+
"vision_model.encoder.layers.13.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 500 |
+
"vision_model.encoder.layers.13.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 501 |
+
"vision_model.encoder.layers.13.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 502 |
+
"vision_model.encoder.layers.13.ls1": "model-00001-of-00009.safetensors",
|
| 503 |
+
"vision_model.encoder.layers.13.ls2": "model-00001-of-00009.safetensors",
|
| 504 |
+
"vision_model.encoder.layers.13.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 505 |
+
"vision_model.encoder.layers.13.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 506 |
+
"vision_model.encoder.layers.13.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 507 |
+
"vision_model.encoder.layers.13.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 508 |
+
"vision_model.encoder.layers.13.norm1.bias": "model-00001-of-00009.safetensors",
|
| 509 |
+
"vision_model.encoder.layers.13.norm1.weight": "model-00001-of-00009.safetensors",
|
| 510 |
+
"vision_model.encoder.layers.13.norm2.bias": "model-00001-of-00009.safetensors",
|
| 511 |
+
"vision_model.encoder.layers.13.norm2.weight": "model-00001-of-00009.safetensors",
|
| 512 |
+
"vision_model.encoder.layers.14.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 513 |
+
"vision_model.encoder.layers.14.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 514 |
+
"vision_model.encoder.layers.14.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 515 |
+
"vision_model.encoder.layers.14.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 516 |
+
"vision_model.encoder.layers.14.ls1": "model-00001-of-00009.safetensors",
|
| 517 |
+
"vision_model.encoder.layers.14.ls2": "model-00001-of-00009.safetensors",
|
| 518 |
+
"vision_model.encoder.layers.14.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 519 |
+
"vision_model.encoder.layers.14.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 520 |
+
"vision_model.encoder.layers.14.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 521 |
+
"vision_model.encoder.layers.14.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 522 |
+
"vision_model.encoder.layers.14.norm1.bias": "model-00001-of-00009.safetensors",
|
| 523 |
+
"vision_model.encoder.layers.14.norm1.weight": "model-00001-of-00009.safetensors",
|
| 524 |
+
"vision_model.encoder.layers.14.norm2.bias": "model-00001-of-00009.safetensors",
|
| 525 |
+
"vision_model.encoder.layers.14.norm2.weight": "model-00001-of-00009.safetensors",
|
| 526 |
+
"vision_model.encoder.layers.15.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 527 |
+
"vision_model.encoder.layers.15.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 528 |
+
"vision_model.encoder.layers.15.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 529 |
+
"vision_model.encoder.layers.15.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 530 |
+
"vision_model.encoder.layers.15.ls1": "model-00001-of-00009.safetensors",
|
| 531 |
+
"vision_model.encoder.layers.15.ls2": "model-00001-of-00009.safetensors",
|
| 532 |
+
"vision_model.encoder.layers.15.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 533 |
+
"vision_model.encoder.layers.15.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 534 |
+
"vision_model.encoder.layers.15.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 535 |
+
"vision_model.encoder.layers.15.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 536 |
+
"vision_model.encoder.layers.15.norm1.bias": "model-00001-of-00009.safetensors",
|
| 537 |
+
"vision_model.encoder.layers.15.norm1.weight": "model-00001-of-00009.safetensors",
|
| 538 |
+
"vision_model.encoder.layers.15.norm2.bias": "model-00001-of-00009.safetensors",
|
| 539 |
+
"vision_model.encoder.layers.15.norm2.weight": "model-00001-of-00009.safetensors",
|
| 540 |
+
"vision_model.encoder.layers.16.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 541 |
+
"vision_model.encoder.layers.16.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 542 |
+
"vision_model.encoder.layers.16.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 543 |
+
"vision_model.encoder.layers.16.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 544 |
+
"vision_model.encoder.layers.16.ls1": "model-00001-of-00009.safetensors",
|
| 545 |
+
"vision_model.encoder.layers.16.ls2": "model-00001-of-00009.safetensors",
|
| 546 |
+
"vision_model.encoder.layers.16.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 547 |
+
"vision_model.encoder.layers.16.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 548 |
+
"vision_model.encoder.layers.16.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 549 |
+
"vision_model.encoder.layers.16.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 550 |
+
"vision_model.encoder.layers.16.norm1.bias": "model-00001-of-00009.safetensors",
|
| 551 |
+
"vision_model.encoder.layers.16.norm1.weight": "model-00001-of-00009.safetensors",
|
| 552 |
+
"vision_model.encoder.layers.16.norm2.bias": "model-00001-of-00009.safetensors",
|
| 553 |
+
"vision_model.encoder.layers.16.norm2.weight": "model-00001-of-00009.safetensors",
|
| 554 |
+
"vision_model.encoder.layers.17.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 555 |
+
"vision_model.encoder.layers.17.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 556 |
+
"vision_model.encoder.layers.17.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 557 |
+
"vision_model.encoder.layers.17.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 558 |
+
"vision_model.encoder.layers.17.ls1": "model-00001-of-00009.safetensors",
|
| 559 |
+
"vision_model.encoder.layers.17.ls2": "model-00001-of-00009.safetensors",
|
| 560 |
+
"vision_model.encoder.layers.17.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 561 |
+
"vision_model.encoder.layers.17.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 562 |
+
"vision_model.encoder.layers.17.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 563 |
+
"vision_model.encoder.layers.17.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 564 |
+
"vision_model.encoder.layers.17.norm1.bias": "model-00001-of-00009.safetensors",
|
| 565 |
+
"vision_model.encoder.layers.17.norm1.weight": "model-00001-of-00009.safetensors",
|
| 566 |
+
"vision_model.encoder.layers.17.norm2.bias": "model-00001-of-00009.safetensors",
|
| 567 |
+
"vision_model.encoder.layers.17.norm2.weight": "model-00001-of-00009.safetensors",
|
| 568 |
+
"vision_model.encoder.layers.18.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 569 |
+
"vision_model.encoder.layers.18.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 570 |
+
"vision_model.encoder.layers.18.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 571 |
+
"vision_model.encoder.layers.18.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 572 |
+
"vision_model.encoder.layers.18.ls1": "model-00001-of-00009.safetensors",
|
| 573 |
+
"vision_model.encoder.layers.18.ls2": "model-00001-of-00009.safetensors",
|
| 574 |
+
"vision_model.encoder.layers.18.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 575 |
+
"vision_model.encoder.layers.18.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 576 |
+
"vision_model.encoder.layers.18.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 577 |
+
"vision_model.encoder.layers.18.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 578 |
+
"vision_model.encoder.layers.18.norm1.bias": "model-00001-of-00009.safetensors",
|
| 579 |
+
"vision_model.encoder.layers.18.norm1.weight": "model-00001-of-00009.safetensors",
|
| 580 |
+
"vision_model.encoder.layers.18.norm2.bias": "model-00001-of-00009.safetensors",
|
| 581 |
+
"vision_model.encoder.layers.18.norm2.weight": "model-00001-of-00009.safetensors",
|
| 582 |
+
"vision_model.encoder.layers.19.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 583 |
+
"vision_model.encoder.layers.19.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 584 |
+
"vision_model.encoder.layers.19.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 585 |
+
"vision_model.encoder.layers.19.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 586 |
+
"vision_model.encoder.layers.19.ls1": "model-00001-of-00009.safetensors",
|
| 587 |
+
"vision_model.encoder.layers.19.ls2": "model-00001-of-00009.safetensors",
|
| 588 |
+
"vision_model.encoder.layers.19.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 589 |
+
"vision_model.encoder.layers.19.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 590 |
+
"vision_model.encoder.layers.19.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 591 |
+
"vision_model.encoder.layers.19.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 592 |
+
"vision_model.encoder.layers.19.norm1.bias": "model-00001-of-00009.safetensors",
|
| 593 |
+
"vision_model.encoder.layers.19.norm1.weight": "model-00001-of-00009.safetensors",
|
| 594 |
+
"vision_model.encoder.layers.19.norm2.bias": "model-00001-of-00009.safetensors",
|
| 595 |
+
"vision_model.encoder.layers.19.norm2.weight": "model-00001-of-00009.safetensors",
|
| 596 |
+
"vision_model.encoder.layers.2.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 597 |
+
"vision_model.encoder.layers.2.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 598 |
+
"vision_model.encoder.layers.2.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 599 |
+
"vision_model.encoder.layers.2.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 600 |
+
"vision_model.encoder.layers.2.ls1": "model-00001-of-00009.safetensors",
|
| 601 |
+
"vision_model.encoder.layers.2.ls2": "model-00001-of-00009.safetensors",
|
| 602 |
+
"vision_model.encoder.layers.2.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 603 |
+
"vision_model.encoder.layers.2.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 604 |
+
"vision_model.encoder.layers.2.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 605 |
+
"vision_model.encoder.layers.2.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 606 |
+
"vision_model.encoder.layers.2.norm1.bias": "model-00001-of-00009.safetensors",
|
| 607 |
+
"vision_model.encoder.layers.2.norm1.weight": "model-00001-of-00009.safetensors",
|
| 608 |
+
"vision_model.encoder.layers.2.norm2.bias": "model-00001-of-00009.safetensors",
|
| 609 |
+
"vision_model.encoder.layers.2.norm2.weight": "model-00001-of-00009.safetensors",
|
| 610 |
+
"vision_model.encoder.layers.20.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 611 |
+
"vision_model.encoder.layers.20.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 612 |
+
"vision_model.encoder.layers.20.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 613 |
+
"vision_model.encoder.layers.20.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 614 |
+
"vision_model.encoder.layers.20.ls1": "model-00001-of-00009.safetensors",
|
| 615 |
+
"vision_model.encoder.layers.20.ls2": "model-00001-of-00009.safetensors",
|
| 616 |
+
"vision_model.encoder.layers.20.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 617 |
+
"vision_model.encoder.layers.20.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 618 |
+
"vision_model.encoder.layers.20.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 619 |
+
"vision_model.encoder.layers.20.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 620 |
+
"vision_model.encoder.layers.20.norm1.bias": "model-00001-of-00009.safetensors",
|
| 621 |
+
"vision_model.encoder.layers.20.norm1.weight": "model-00001-of-00009.safetensors",
|
| 622 |
+
"vision_model.encoder.layers.20.norm2.bias": "model-00001-of-00009.safetensors",
|
| 623 |
+
"vision_model.encoder.layers.20.norm2.weight": "model-00001-of-00009.safetensors",
|
| 624 |
+
"vision_model.encoder.layers.21.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 625 |
+
"vision_model.encoder.layers.21.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 626 |
+
"vision_model.encoder.layers.21.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 627 |
+
"vision_model.encoder.layers.21.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 628 |
+
"vision_model.encoder.layers.21.ls1": "model-00001-of-00009.safetensors",
|
| 629 |
+
"vision_model.encoder.layers.21.ls2": "model-00001-of-00009.safetensors",
|
| 630 |
+
"vision_model.encoder.layers.21.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 631 |
+
"vision_model.encoder.layers.21.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 632 |
+
"vision_model.encoder.layers.21.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 633 |
+
"vision_model.encoder.layers.21.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 634 |
+
"vision_model.encoder.layers.21.norm1.bias": "model-00001-of-00009.safetensors",
|
| 635 |
+
"vision_model.encoder.layers.21.norm1.weight": "model-00001-of-00009.safetensors",
|
| 636 |
+
"vision_model.encoder.layers.21.norm2.bias": "model-00001-of-00009.safetensors",
|
| 637 |
+
"vision_model.encoder.layers.21.norm2.weight": "model-00001-of-00009.safetensors",
|
| 638 |
+
"vision_model.encoder.layers.22.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 639 |
+
"vision_model.encoder.layers.22.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 640 |
+
"vision_model.encoder.layers.22.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 641 |
+
"vision_model.encoder.layers.22.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 642 |
+
"vision_model.encoder.layers.22.ls1": "model-00001-of-00009.safetensors",
|
| 643 |
+
"vision_model.encoder.layers.22.ls2": "model-00001-of-00009.safetensors",
|
| 644 |
+
"vision_model.encoder.layers.22.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 645 |
+
"vision_model.encoder.layers.22.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 646 |
+
"vision_model.encoder.layers.22.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 647 |
+
"vision_model.encoder.layers.22.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 648 |
+
"vision_model.encoder.layers.22.norm1.bias": "model-00001-of-00009.safetensors",
|
| 649 |
+
"vision_model.encoder.layers.22.norm1.weight": "model-00001-of-00009.safetensors",
|
| 650 |
+
"vision_model.encoder.layers.22.norm2.bias": "model-00001-of-00009.safetensors",
|
| 651 |
+
"vision_model.encoder.layers.22.norm2.weight": "model-00001-of-00009.safetensors",
|
| 652 |
+
"vision_model.encoder.layers.23.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 653 |
+
"vision_model.encoder.layers.23.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 654 |
+
"vision_model.encoder.layers.23.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 655 |
+
"vision_model.encoder.layers.23.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 656 |
+
"vision_model.encoder.layers.23.ls1": "model-00001-of-00009.safetensors",
|
| 657 |
+
"vision_model.encoder.layers.23.ls2": "model-00001-of-00009.safetensors",
|
| 658 |
+
"vision_model.encoder.layers.23.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 659 |
+
"vision_model.encoder.layers.23.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 660 |
+
"vision_model.encoder.layers.23.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 661 |
+
"vision_model.encoder.layers.23.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 662 |
+
"vision_model.encoder.layers.23.norm1.bias": "model-00001-of-00009.safetensors",
|
| 663 |
+
"vision_model.encoder.layers.23.norm1.weight": "model-00001-of-00009.safetensors",
|
| 664 |
+
"vision_model.encoder.layers.23.norm2.bias": "model-00001-of-00009.safetensors",
|
| 665 |
+
"vision_model.encoder.layers.23.norm2.weight": "model-00001-of-00009.safetensors",
|
| 666 |
+
"vision_model.encoder.layers.3.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 667 |
+
"vision_model.encoder.layers.3.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 668 |
+
"vision_model.encoder.layers.3.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 669 |
+
"vision_model.encoder.layers.3.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 670 |
+
"vision_model.encoder.layers.3.ls1": "model-00001-of-00009.safetensors",
|
| 671 |
+
"vision_model.encoder.layers.3.ls2": "model-00001-of-00009.safetensors",
|
| 672 |
+
"vision_model.encoder.layers.3.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 673 |
+
"vision_model.encoder.layers.3.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 674 |
+
"vision_model.encoder.layers.3.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 675 |
+
"vision_model.encoder.layers.3.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 676 |
+
"vision_model.encoder.layers.3.norm1.bias": "model-00001-of-00009.safetensors",
|
| 677 |
+
"vision_model.encoder.layers.3.norm1.weight": "model-00001-of-00009.safetensors",
|
| 678 |
+
"vision_model.encoder.layers.3.norm2.bias": "model-00001-of-00009.safetensors",
|
| 679 |
+
"vision_model.encoder.layers.3.norm2.weight": "model-00001-of-00009.safetensors",
|
| 680 |
+
"vision_model.encoder.layers.4.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 681 |
+
"vision_model.encoder.layers.4.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 682 |
+
"vision_model.encoder.layers.4.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 683 |
+
"vision_model.encoder.layers.4.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 684 |
+
"vision_model.encoder.layers.4.ls1": "model-00001-of-00009.safetensors",
|
| 685 |
+
"vision_model.encoder.layers.4.ls2": "model-00001-of-00009.safetensors",
|
| 686 |
+
"vision_model.encoder.layers.4.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 687 |
+
"vision_model.encoder.layers.4.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 688 |
+
"vision_model.encoder.layers.4.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 689 |
+
"vision_model.encoder.layers.4.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 690 |
+
"vision_model.encoder.layers.4.norm1.bias": "model-00001-of-00009.safetensors",
|
| 691 |
+
"vision_model.encoder.layers.4.norm1.weight": "model-00001-of-00009.safetensors",
|
| 692 |
+
"vision_model.encoder.layers.4.norm2.bias": "model-00001-of-00009.safetensors",
|
| 693 |
+
"vision_model.encoder.layers.4.norm2.weight": "model-00001-of-00009.safetensors",
|
| 694 |
+
"vision_model.encoder.layers.5.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 695 |
+
"vision_model.encoder.layers.5.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 696 |
+
"vision_model.encoder.layers.5.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 697 |
+
"vision_model.encoder.layers.5.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 698 |
+
"vision_model.encoder.layers.5.ls1": "model-00001-of-00009.safetensors",
|
| 699 |
+
"vision_model.encoder.layers.5.ls2": "model-00001-of-00009.safetensors",
|
| 700 |
+
"vision_model.encoder.layers.5.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 701 |
+
"vision_model.encoder.layers.5.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 702 |
+
"vision_model.encoder.layers.5.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 703 |
+
"vision_model.encoder.layers.5.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 704 |
+
"vision_model.encoder.layers.5.norm1.bias": "model-00001-of-00009.safetensors",
|
| 705 |
+
"vision_model.encoder.layers.5.norm1.weight": "model-00001-of-00009.safetensors",
|
| 706 |
+
"vision_model.encoder.layers.5.norm2.bias": "model-00001-of-00009.safetensors",
|
| 707 |
+
"vision_model.encoder.layers.5.norm2.weight": "model-00001-of-00009.safetensors",
|
| 708 |
+
"vision_model.encoder.layers.6.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 709 |
+
"vision_model.encoder.layers.6.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 710 |
+
"vision_model.encoder.layers.6.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 711 |
+
"vision_model.encoder.layers.6.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 712 |
+
"vision_model.encoder.layers.6.ls1": "model-00001-of-00009.safetensors",
|
| 713 |
+
"vision_model.encoder.layers.6.ls2": "model-00001-of-00009.safetensors",
|
| 714 |
+
"vision_model.encoder.layers.6.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 715 |
+
"vision_model.encoder.layers.6.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 716 |
+
"vision_model.encoder.layers.6.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 717 |
+
"vision_model.encoder.layers.6.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 718 |
+
"vision_model.encoder.layers.6.norm1.bias": "model-00001-of-00009.safetensors",
|
| 719 |
+
"vision_model.encoder.layers.6.norm1.weight": "model-00001-of-00009.safetensors",
|
| 720 |
+
"vision_model.encoder.layers.6.norm2.bias": "model-00001-of-00009.safetensors",
|
| 721 |
+
"vision_model.encoder.layers.6.norm2.weight": "model-00001-of-00009.safetensors",
|
| 722 |
+
"vision_model.encoder.layers.7.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 723 |
+
"vision_model.encoder.layers.7.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 724 |
+
"vision_model.encoder.layers.7.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 725 |
+
"vision_model.encoder.layers.7.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 726 |
+
"vision_model.encoder.layers.7.ls1": "model-00001-of-00009.safetensors",
|
| 727 |
+
"vision_model.encoder.layers.7.ls2": "model-00001-of-00009.safetensors",
|
| 728 |
+
"vision_model.encoder.layers.7.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 729 |
+
"vision_model.encoder.layers.7.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 730 |
+
"vision_model.encoder.layers.7.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 731 |
+
"vision_model.encoder.layers.7.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 732 |
+
"vision_model.encoder.layers.7.norm1.bias": "model-00001-of-00009.safetensors",
|
| 733 |
+
"vision_model.encoder.layers.7.norm1.weight": "model-00001-of-00009.safetensors",
|
| 734 |
+
"vision_model.encoder.layers.7.norm2.bias": "model-00001-of-00009.safetensors",
|
| 735 |
+
"vision_model.encoder.layers.7.norm2.weight": "model-00001-of-00009.safetensors",
|
| 736 |
+
"vision_model.encoder.layers.8.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 737 |
+
"vision_model.encoder.layers.8.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 738 |
+
"vision_model.encoder.layers.8.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 739 |
+
"vision_model.encoder.layers.8.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 740 |
+
"vision_model.encoder.layers.8.ls1": "model-00001-of-00009.safetensors",
|
| 741 |
+
"vision_model.encoder.layers.8.ls2": "model-00001-of-00009.safetensors",
|
| 742 |
+
"vision_model.encoder.layers.8.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 743 |
+
"vision_model.encoder.layers.8.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 744 |
+
"vision_model.encoder.layers.8.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 745 |
+
"vision_model.encoder.layers.8.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 746 |
+
"vision_model.encoder.layers.8.norm1.bias": "model-00001-of-00009.safetensors",
|
| 747 |
+
"vision_model.encoder.layers.8.norm1.weight": "model-00001-of-00009.safetensors",
|
| 748 |
+
"vision_model.encoder.layers.8.norm2.bias": "model-00001-of-00009.safetensors",
|
| 749 |
+
"vision_model.encoder.layers.8.norm2.weight": "model-00001-of-00009.safetensors",
|
| 750 |
+
"vision_model.encoder.layers.9.attn.proj.bias": "model-00001-of-00009.safetensors",
|
| 751 |
+
"vision_model.encoder.layers.9.attn.proj.weight": "model-00001-of-00009.safetensors",
|
| 752 |
+
"vision_model.encoder.layers.9.attn.qkv.bias": "model-00001-of-00009.safetensors",
|
| 753 |
+
"vision_model.encoder.layers.9.attn.qkv.weight": "model-00001-of-00009.safetensors",
|
| 754 |
+
"vision_model.encoder.layers.9.ls1": "model-00001-of-00009.safetensors",
|
| 755 |
+
"vision_model.encoder.layers.9.ls2": "model-00001-of-00009.safetensors",
|
| 756 |
+
"vision_model.encoder.layers.9.mlp.fc1.bias": "model-00001-of-00009.safetensors",
|
| 757 |
+
"vision_model.encoder.layers.9.mlp.fc1.weight": "model-00001-of-00009.safetensors",
|
| 758 |
+
"vision_model.encoder.layers.9.mlp.fc2.bias": "model-00001-of-00009.safetensors",
|
| 759 |
+
"vision_model.encoder.layers.9.mlp.fc2.weight": "model-00001-of-00009.safetensors",
|
| 760 |
+
"vision_model.encoder.layers.9.norm1.bias": "model-00001-of-00009.safetensors",
|
| 761 |
+
"vision_model.encoder.layers.9.norm1.weight": "model-00001-of-00009.safetensors",
|
| 762 |
+
"vision_model.encoder.layers.9.norm2.bias": "model-00001-of-00009.safetensors",
|
| 763 |
+
"vision_model.encoder.layers.9.norm2.weight": "model-00001-of-00009.safetensors"
|
| 764 |
+
}
|
| 765 |
+
}
|
modeling_intern_vit.py
ADDED
|
@@ -0,0 +1,433 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
from typing import Optional, Tuple, Union
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn.functional as F
|
| 11 |
+
import torch.utils.checkpoint
|
| 12 |
+
from einops import rearrange
|
| 13 |
+
from timm.layers import DropPath
|
| 14 |
+
from torch import nn
|
| 15 |
+
from transformers.activations import ACT2FN
|
| 16 |
+
from transformers.modeling_outputs import (BaseModelOutput,
|
| 17 |
+
BaseModelOutputWithPooling)
|
| 18 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 19 |
+
from transformers.utils import logging
|
| 20 |
+
|
| 21 |
+
from .configuration_intern_vit import InternVisionConfig
|
| 22 |
+
|
| 23 |
+
try:
|
| 24 |
+
from flash_attn.bert_padding import pad_input, unpad_input
|
| 25 |
+
from flash_attn.flash_attn_interface import \
|
| 26 |
+
flash_attn_varlen_qkvpacked_func
|
| 27 |
+
has_flash_attn = True
|
| 28 |
+
except:
|
| 29 |
+
print('FlashAttention2 is not installed.')
|
| 30 |
+
has_flash_attn = False
|
| 31 |
+
|
| 32 |
+
logger = logging.get_logger(__name__)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
class FlashAttention(nn.Module):
|
| 36 |
+
"""Implement the scaled dot product attention with softmax.
|
| 37 |
+
Arguments
|
| 38 |
+
---------
|
| 39 |
+
softmax_scale: The temperature to use for the softmax attention.
|
| 40 |
+
(default: 1/sqrt(d_keys) where d_keys is computed at
|
| 41 |
+
runtime)
|
| 42 |
+
attention_dropout: The dropout rate to apply to the attention
|
| 43 |
+
(default: 0.0)
|
| 44 |
+
"""
|
| 45 |
+
|
| 46 |
+
def __init__(self, softmax_scale=None, attention_dropout=0.0, device=None, dtype=None):
|
| 47 |
+
super().__init__()
|
| 48 |
+
self.softmax_scale = softmax_scale
|
| 49 |
+
self.dropout_p = attention_dropout
|
| 50 |
+
|
| 51 |
+
def forward(self, qkv, key_padding_mask=None, causal=False, cu_seqlens=None,
|
| 52 |
+
max_s=None, need_weights=False):
|
| 53 |
+
"""Implements the multihead softmax attention.
|
| 54 |
+
Arguments
|
| 55 |
+
---------
|
| 56 |
+
qkv: The tensor containing the query, key, and value. (B, S, 3, H, D) if key_padding_mask is None
|
| 57 |
+
if unpadded: (nnz, 3, h, d)
|
| 58 |
+
key_padding_mask: a bool tensor of shape (B, S)
|
| 59 |
+
"""
|
| 60 |
+
assert not need_weights
|
| 61 |
+
assert qkv.dtype in [torch.float16, torch.bfloat16]
|
| 62 |
+
assert qkv.is_cuda
|
| 63 |
+
|
| 64 |
+
if cu_seqlens is None:
|
| 65 |
+
batch_size = qkv.shape[0]
|
| 66 |
+
seqlen = qkv.shape[1]
|
| 67 |
+
if key_padding_mask is None:
|
| 68 |
+
qkv = rearrange(qkv, 'b s ... -> (b s) ...')
|
| 69 |
+
max_s = seqlen
|
| 70 |
+
cu_seqlens = torch.arange(0, (batch_size + 1) * seqlen, step=seqlen, dtype=torch.int32,
|
| 71 |
+
device=qkv.device)
|
| 72 |
+
output = flash_attn_varlen_qkvpacked_func(
|
| 73 |
+
qkv, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 74 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 75 |
+
)
|
| 76 |
+
output = rearrange(output, '(b s) ... -> b s ...', b=batch_size)
|
| 77 |
+
else:
|
| 78 |
+
nheads = qkv.shape[-2]
|
| 79 |
+
x = rearrange(qkv, 'b s three h d -> b s (three h d)')
|
| 80 |
+
x_unpad, indices, cu_seqlens, max_s = unpad_input(x, key_padding_mask)
|
| 81 |
+
x_unpad = rearrange(x_unpad, 'nnz (three h d) -> nnz three h d', three=3, h=nheads)
|
| 82 |
+
output_unpad = flash_attn_varlen_qkvpacked_func(
|
| 83 |
+
x_unpad, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 84 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 85 |
+
)
|
| 86 |
+
output = rearrange(pad_input(rearrange(output_unpad, 'nnz h d -> nnz (h d)'),
|
| 87 |
+
indices, batch_size, seqlen),
|
| 88 |
+
'b s (h d) -> b s h d', h=nheads)
|
| 89 |
+
else:
|
| 90 |
+
assert max_s is not None
|
| 91 |
+
output = flash_attn_varlen_qkvpacked_func(
|
| 92 |
+
qkv, cu_seqlens, max_s, self.dropout_p if self.training else 0.0,
|
| 93 |
+
softmax_scale=self.softmax_scale, causal=causal
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
return output, None
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class InternRMSNorm(nn.Module):
|
| 100 |
+
def __init__(self, hidden_size, eps=1e-6):
|
| 101 |
+
super().__init__()
|
| 102 |
+
self.weight = nn.Parameter(torch.ones(hidden_size))
|
| 103 |
+
self.variance_epsilon = eps
|
| 104 |
+
|
| 105 |
+
def forward(self, hidden_states):
|
| 106 |
+
input_dtype = hidden_states.dtype
|
| 107 |
+
hidden_states = hidden_states.to(torch.float32)
|
| 108 |
+
variance = hidden_states.pow(2).mean(-1, keepdim=True)
|
| 109 |
+
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
|
| 110 |
+
return self.weight * hidden_states.to(input_dtype)
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
try:
|
| 114 |
+
from apex.normalization import FusedRMSNorm
|
| 115 |
+
|
| 116 |
+
InternRMSNorm = FusedRMSNorm # noqa
|
| 117 |
+
|
| 118 |
+
logger.info('Discovered apex.normalization.FusedRMSNorm - will use it instead of InternRMSNorm')
|
| 119 |
+
except ImportError:
|
| 120 |
+
# using the normal InternRMSNorm
|
| 121 |
+
pass
|
| 122 |
+
except Exception:
|
| 123 |
+
logger.warning('discovered apex but it failed to load, falling back to InternRMSNorm')
|
| 124 |
+
pass
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
NORM2FN = {
|
| 128 |
+
'rms_norm': InternRMSNorm,
|
| 129 |
+
'layer_norm': nn.LayerNorm,
|
| 130 |
+
}
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
class InternVisionEmbeddings(nn.Module):
|
| 134 |
+
def __init__(self, config: InternVisionConfig):
|
| 135 |
+
super().__init__()
|
| 136 |
+
self.config = config
|
| 137 |
+
self.embed_dim = config.hidden_size
|
| 138 |
+
self.image_size = config.image_size
|
| 139 |
+
self.patch_size = config.patch_size
|
| 140 |
+
|
| 141 |
+
self.class_embedding = nn.Parameter(
|
| 142 |
+
torch.randn(1, 1, self.embed_dim),
|
| 143 |
+
)
|
| 144 |
+
|
| 145 |
+
self.patch_embedding = nn.Conv2d(
|
| 146 |
+
in_channels=3, out_channels=self.embed_dim, kernel_size=self.patch_size, stride=self.patch_size
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
self.num_patches = (self.image_size // self.patch_size) ** 2
|
| 150 |
+
self.num_positions = self.num_patches + 1
|
| 151 |
+
|
| 152 |
+
self.position_embedding = nn.Parameter(torch.randn(1, self.num_positions, self.embed_dim))
|
| 153 |
+
|
| 154 |
+
def _get_pos_embed(self, pos_embed, H, W):
|
| 155 |
+
target_dtype = pos_embed.dtype
|
| 156 |
+
pos_embed = pos_embed.float().reshape(
|
| 157 |
+
1, self.image_size // self.patch_size, self.image_size // self.patch_size, -1).permute(0, 3, 1, 2)
|
| 158 |
+
pos_embed = F.interpolate(pos_embed, size=(H, W), mode='bicubic', align_corners=False). \
|
| 159 |
+
reshape(1, -1, H * W).permute(0, 2, 1).to(target_dtype)
|
| 160 |
+
return pos_embed
|
| 161 |
+
|
| 162 |
+
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
|
| 163 |
+
target_dtype = self.patch_embedding.weight.dtype
|
| 164 |
+
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, channel, width, height]
|
| 165 |
+
batch_size, _, height, width = patch_embeds.shape
|
| 166 |
+
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
|
| 167 |
+
class_embeds = self.class_embedding.expand(batch_size, 1, -1).to(target_dtype)
|
| 168 |
+
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
|
| 169 |
+
position_embedding = torch.cat([
|
| 170 |
+
self.position_embedding[:, :1, :],
|
| 171 |
+
self._get_pos_embed(self.position_embedding[:, 1:, :], height, width)
|
| 172 |
+
], dim=1)
|
| 173 |
+
embeddings = embeddings + position_embedding.to(target_dtype)
|
| 174 |
+
return embeddings
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
class InternAttention(nn.Module):
|
| 178 |
+
"""Multi-headed attention from 'Attention Is All You Need' paper"""
|
| 179 |
+
|
| 180 |
+
def __init__(self, config: InternVisionConfig):
|
| 181 |
+
super().__init__()
|
| 182 |
+
self.config = config
|
| 183 |
+
self.embed_dim = config.hidden_size
|
| 184 |
+
self.num_heads = config.num_attention_heads
|
| 185 |
+
self.use_flash_attn = config.use_flash_attn and has_flash_attn
|
| 186 |
+
if config.use_flash_attn and not has_flash_attn:
|
| 187 |
+
print('Warning: Flash Attention is not available, use_flash_attn is set to False.')
|
| 188 |
+
self.head_dim = self.embed_dim // self.num_heads
|
| 189 |
+
if self.head_dim * self.num_heads != self.embed_dim:
|
| 190 |
+
raise ValueError(
|
| 191 |
+
f'embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:'
|
| 192 |
+
f' {self.num_heads}).'
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
self.scale = self.head_dim ** -0.5
|
| 196 |
+
self.qkv = nn.Linear(self.embed_dim, 3 * self.embed_dim, bias=config.qkv_bias)
|
| 197 |
+
self.attn_drop = nn.Dropout(config.attention_dropout)
|
| 198 |
+
self.proj_drop = nn.Dropout(config.dropout)
|
| 199 |
+
|
| 200 |
+
self.qk_normalization = config.qk_normalization
|
| 201 |
+
|
| 202 |
+
if self.qk_normalization:
|
| 203 |
+
self.q_norm = InternRMSNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 204 |
+
self.k_norm = InternRMSNorm(self.embed_dim, eps=config.layer_norm_eps)
|
| 205 |
+
|
| 206 |
+
if self.use_flash_attn:
|
| 207 |
+
self.inner_attn = FlashAttention(attention_dropout=config.attention_dropout)
|
| 208 |
+
self.proj = nn.Linear(self.embed_dim, self.embed_dim)
|
| 209 |
+
|
| 210 |
+
def _naive_attn(self, x):
|
| 211 |
+
B, N, C = x.shape
|
| 212 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 213 |
+
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
|
| 214 |
+
|
| 215 |
+
if self.qk_normalization:
|
| 216 |
+
B_, H_, N_, D_ = q.shape
|
| 217 |
+
q = self.q_norm(q.transpose(1, 2).flatten(-2, -1)).view(B_, N_, H_, D_).transpose(1, 2)
|
| 218 |
+
k = self.k_norm(k.transpose(1, 2).flatten(-2, -1)).view(B_, N_, H_, D_).transpose(1, 2)
|
| 219 |
+
|
| 220 |
+
attn = ((q * self.scale) @ k.transpose(-2, -1))
|
| 221 |
+
attn = attn.softmax(dim=-1)
|
| 222 |
+
attn = self.attn_drop(attn)
|
| 223 |
+
|
| 224 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
|
| 225 |
+
x = self.proj(x)
|
| 226 |
+
x = self.proj_drop(x)
|
| 227 |
+
return x
|
| 228 |
+
|
| 229 |
+
def _flash_attn(self, x, key_padding_mask=None, need_weights=False):
|
| 230 |
+
qkv = self.qkv(x)
|
| 231 |
+
qkv = rearrange(qkv, 'b s (three h d) -> b s three h d', three=3, h=self.num_heads)
|
| 232 |
+
|
| 233 |
+
if self.qk_normalization:
|
| 234 |
+
q, k, v = qkv.unbind(2)
|
| 235 |
+
q = self.q_norm(q.flatten(-2, -1)).view(q.shape)
|
| 236 |
+
k = self.k_norm(k.flatten(-2, -1)).view(k.shape)
|
| 237 |
+
qkv = torch.stack([q, k, v], dim=2)
|
| 238 |
+
|
| 239 |
+
context, _ = self.inner_attn(
|
| 240 |
+
qkv, key_padding_mask=key_padding_mask, need_weights=need_weights, causal=False
|
| 241 |
+
)
|
| 242 |
+
outs = self.proj(rearrange(context, 'b s h d -> b s (h d)'))
|
| 243 |
+
outs = self.proj_drop(outs)
|
| 244 |
+
return outs
|
| 245 |
+
|
| 246 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 247 |
+
x = self._naive_attn(hidden_states) if not self.use_flash_attn else self._flash_attn(hidden_states)
|
| 248 |
+
return x
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
class InternMLP(nn.Module):
|
| 252 |
+
def __init__(self, config: InternVisionConfig):
|
| 253 |
+
super().__init__()
|
| 254 |
+
self.config = config
|
| 255 |
+
self.act = ACT2FN[config.hidden_act]
|
| 256 |
+
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 257 |
+
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 258 |
+
|
| 259 |
+
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
|
| 260 |
+
hidden_states = self.fc1(hidden_states)
|
| 261 |
+
hidden_states = self.act(hidden_states)
|
| 262 |
+
hidden_states = self.fc2(hidden_states)
|
| 263 |
+
return hidden_states
|
| 264 |
+
|
| 265 |
+
|
| 266 |
+
class InternVisionEncoderLayer(nn.Module):
|
| 267 |
+
def __init__(self, config: InternVisionConfig, drop_path_rate: float):
|
| 268 |
+
super().__init__()
|
| 269 |
+
self.embed_dim = config.hidden_size
|
| 270 |
+
self.intermediate_size = config.intermediate_size
|
| 271 |
+
self.norm_type = config.norm_type
|
| 272 |
+
|
| 273 |
+
self.attn = InternAttention(config)
|
| 274 |
+
self.mlp = InternMLP(config)
|
| 275 |
+
self.norm1 = NORM2FN[self.norm_type](self.embed_dim, eps=config.layer_norm_eps)
|
| 276 |
+
self.norm2 = NORM2FN[self.norm_type](self.embed_dim, eps=config.layer_norm_eps)
|
| 277 |
+
|
| 278 |
+
self.ls1 = nn.Parameter(config.initializer_factor * torch.ones(self.embed_dim))
|
| 279 |
+
self.ls2 = nn.Parameter(config.initializer_factor * torch.ones(self.embed_dim))
|
| 280 |
+
self.drop_path1 = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
|
| 281 |
+
self.drop_path2 = DropPath(drop_path_rate) if drop_path_rate > 0. else nn.Identity()
|
| 282 |
+
|
| 283 |
+
def forward(
|
| 284 |
+
self,
|
| 285 |
+
hidden_states: torch.Tensor,
|
| 286 |
+
) -> Tuple[torch.FloatTensor, Optional[torch.FloatTensor], Optional[Tuple[torch.FloatTensor]]]:
|
| 287 |
+
"""
|
| 288 |
+
Args:
|
| 289 |
+
hidden_states (`Tuple[torch.FloatTensor, Optional[torch.FloatTensor]]`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
| 290 |
+
"""
|
| 291 |
+
hidden_states = hidden_states + self.drop_path1(self.attn(self.norm1(hidden_states).to(hidden_states.dtype)) * self.ls1)
|
| 292 |
+
|
| 293 |
+
hidden_states = hidden_states + self.drop_path2(self.mlp(self.norm2(hidden_states).to(hidden_states.dtype)) * self.ls2)
|
| 294 |
+
|
| 295 |
+
return hidden_states
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
class InternVisionEncoder(nn.Module):
|
| 299 |
+
"""
|
| 300 |
+
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
|
| 301 |
+
[`InternEncoderLayer`].
|
| 302 |
+
|
| 303 |
+
Args:
|
| 304 |
+
config (`InternConfig`):
|
| 305 |
+
The corresponding vision configuration for the `InternEncoder`.
|
| 306 |
+
"""
|
| 307 |
+
|
| 308 |
+
def __init__(self, config: InternVisionConfig):
|
| 309 |
+
super().__init__()
|
| 310 |
+
self.config = config
|
| 311 |
+
# stochastic depth decay rule
|
| 312 |
+
dpr = [x.item() for x in torch.linspace(0, config.drop_path_rate, config.num_hidden_layers)]
|
| 313 |
+
self.layers = nn.ModuleList([
|
| 314 |
+
InternVisionEncoderLayer(config, dpr[idx]) for idx in range(config.num_hidden_layers)])
|
| 315 |
+
self.gradient_checkpointing = True
|
| 316 |
+
|
| 317 |
+
def forward(
|
| 318 |
+
self,
|
| 319 |
+
inputs_embeds,
|
| 320 |
+
output_hidden_states: Optional[bool] = None,
|
| 321 |
+
return_dict: Optional[bool] = None,
|
| 322 |
+
) -> Union[Tuple, BaseModelOutput]:
|
| 323 |
+
r"""
|
| 324 |
+
Args:
|
| 325 |
+
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
|
| 326 |
+
Embedded representation of the inputs. Should be float, not int tokens.
|
| 327 |
+
output_hidden_states (`bool`, *optional*):
|
| 328 |
+
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
|
| 329 |
+
for more detail.
|
| 330 |
+
return_dict (`bool`, *optional*):
|
| 331 |
+
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
|
| 332 |
+
"""
|
| 333 |
+
output_hidden_states = (
|
| 334 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 335 |
+
)
|
| 336 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 337 |
+
|
| 338 |
+
encoder_states = () if output_hidden_states else None
|
| 339 |
+
hidden_states = inputs_embeds
|
| 340 |
+
|
| 341 |
+
for idx, encoder_layer in enumerate(self.layers):
|
| 342 |
+
if output_hidden_states:
|
| 343 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 344 |
+
if self.gradient_checkpointing and self.training:
|
| 345 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 346 |
+
encoder_layer,
|
| 347 |
+
hidden_states)
|
| 348 |
+
else:
|
| 349 |
+
layer_outputs = encoder_layer(
|
| 350 |
+
hidden_states,
|
| 351 |
+
)
|
| 352 |
+
hidden_states = layer_outputs
|
| 353 |
+
|
| 354 |
+
if output_hidden_states:
|
| 355 |
+
encoder_states = encoder_states + (hidden_states,)
|
| 356 |
+
|
| 357 |
+
if not return_dict:
|
| 358 |
+
return tuple(v for v in [hidden_states, encoder_states] if v is not None)
|
| 359 |
+
return BaseModelOutput(
|
| 360 |
+
last_hidden_state=hidden_states, hidden_states=encoder_states
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
|
| 364 |
+
class InternVisionModel(PreTrainedModel):
|
| 365 |
+
main_input_name = 'pixel_values'
|
| 366 |
+
_supports_flash_attn_2 = True
|
| 367 |
+
supports_gradient_checkpointing = True
|
| 368 |
+
config_class = InternVisionConfig
|
| 369 |
+
_no_split_modules = ['InternVisionEncoderLayer']
|
| 370 |
+
# support transformers 4.51.+
|
| 371 |
+
_tp_plan = ''
|
| 372 |
+
|
| 373 |
+
def __init__(self, config: InternVisionConfig):
|
| 374 |
+
super().__init__(config)
|
| 375 |
+
self.config = config
|
| 376 |
+
|
| 377 |
+
self.embeddings = InternVisionEmbeddings(config)
|
| 378 |
+
self.encoder = InternVisionEncoder(config)
|
| 379 |
+
|
| 380 |
+
def resize_pos_embeddings(self, old_size, new_size, patch_size):
|
| 381 |
+
pos_emb = self.embeddings.position_embedding
|
| 382 |
+
_, num_positions, embed_dim = pos_emb.shape
|
| 383 |
+
cls_emb = pos_emb[:, :1, :]
|
| 384 |
+
pos_emb = pos_emb[:, 1:, :].reshape(1, old_size // patch_size, old_size // patch_size, -1).permute(0, 3, 1, 2)
|
| 385 |
+
pos_emb = F.interpolate(pos_emb.float(), size=new_size // patch_size, mode='bicubic', align_corners=False)
|
| 386 |
+
pos_emb = pos_emb.to(cls_emb.dtype).reshape(1, embed_dim, -1).permute(0, 2, 1)
|
| 387 |
+
pos_emb = torch.cat([cls_emb, pos_emb], dim=1)
|
| 388 |
+
self.embeddings.position_embedding = nn.Parameter(pos_emb)
|
| 389 |
+
self.embeddings.image_size = new_size
|
| 390 |
+
logger.info('Resized position embeddings from {} to {}'.format(old_size, new_size))
|
| 391 |
+
|
| 392 |
+
def get_input_embeddings(self):
|
| 393 |
+
return self.embeddings
|
| 394 |
+
|
| 395 |
+
def forward(
|
| 396 |
+
self,
|
| 397 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 398 |
+
output_hidden_states: Optional[bool] = None,
|
| 399 |
+
return_dict: Optional[bool] = None,
|
| 400 |
+
pixel_embeds: Optional[torch.FloatTensor] = None,
|
| 401 |
+
) -> Union[Tuple, BaseModelOutputWithPooling]:
|
| 402 |
+
output_hidden_states = (
|
| 403 |
+
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
| 404 |
+
)
|
| 405 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 406 |
+
|
| 407 |
+
if pixel_values is None and pixel_embeds is None:
|
| 408 |
+
raise ValueError('You have to specify pixel_values or pixel_embeds')
|
| 409 |
+
|
| 410 |
+
if pixel_embeds is not None:
|
| 411 |
+
hidden_states = pixel_embeds
|
| 412 |
+
else:
|
| 413 |
+
if len(pixel_values.shape) == 4:
|
| 414 |
+
hidden_states = self.embeddings(pixel_values)
|
| 415 |
+
else:
|
| 416 |
+
raise ValueError(f'wrong pixel_values size: {pixel_values.shape}')
|
| 417 |
+
encoder_outputs = self.encoder(
|
| 418 |
+
inputs_embeds=hidden_states,
|
| 419 |
+
output_hidden_states=output_hidden_states,
|
| 420 |
+
return_dict=return_dict,
|
| 421 |
+
)
|
| 422 |
+
last_hidden_state = encoder_outputs.last_hidden_state
|
| 423 |
+
pooled_output = last_hidden_state[:, 0, :]
|
| 424 |
+
|
| 425 |
+
if not return_dict:
|
| 426 |
+
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
|
| 427 |
+
|
| 428 |
+
return BaseModelOutputWithPooling(
|
| 429 |
+
last_hidden_state=last_hidden_state,
|
| 430 |
+
pooler_output=pooled_output,
|
| 431 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 432 |
+
attentions=encoder_outputs.attentions,
|
| 433 |
+
)
|
modeling_internvl_chat.py
ADDED
|
@@ -0,0 +1,399 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# InternVL
|
| 3 |
+
# Copyright (c) 2024 OpenGVLab
|
| 4 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 5 |
+
# --------------------------------------------------------
|
| 6 |
+
|
| 7 |
+
import warnings
|
| 8 |
+
from typing import List, Optional, Tuple, Union
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.utils.checkpoint
|
| 12 |
+
import transformers
|
| 13 |
+
from torch import nn
|
| 14 |
+
from torch.nn import CrossEntropyLoss
|
| 15 |
+
from transformers import GenerationConfig
|
| 16 |
+
from transformers.modeling_outputs import CausalLMOutputWithPast, MoeCausalLMOutputWithPast
|
| 17 |
+
from transformers.modeling_utils import PreTrainedModel
|
| 18 |
+
from transformers.utils import logging
|
| 19 |
+
from transformers import AutoModelForCausalLM
|
| 20 |
+
from transformers.models.gpt_oss.modeling_gpt_oss import GptOssForCausalLM, load_balancing_loss_func
|
| 21 |
+
|
| 22 |
+
from .configuration_internvl_chat import InternVLChatConfig
|
| 23 |
+
from .conversation import get_conv_template
|
| 24 |
+
from .modeling_intern_vit import InternVisionModel, has_flash_attn
|
| 25 |
+
|
| 26 |
+
logger = logging.get_logger(__name__)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def version_cmp(v1, v2, op='eq'):
|
| 30 |
+
import operator
|
| 31 |
+
|
| 32 |
+
from packaging import version
|
| 33 |
+
op_func = getattr(operator, op)
|
| 34 |
+
return op_func(version.parse(v1), version.parse(v2))
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
class InternVLChatModel(PreTrainedModel):
|
| 38 |
+
config_class = InternVLChatConfig
|
| 39 |
+
main_input_name = 'pixel_values'
|
| 40 |
+
base_model_prefix = 'language_model'
|
| 41 |
+
_supports_flash_attn_2 = True
|
| 42 |
+
supports_gradient_checkpointing = True
|
| 43 |
+
_no_split_modules = [
|
| 44 |
+
"InternVisionModel",
|
| 45 |
+
"GptOssDecoderLayer",
|
| 46 |
+
]
|
| 47 |
+
|
| 48 |
+
# support transformers 4.51.+
|
| 49 |
+
_tp_plan = ''
|
| 50 |
+
|
| 51 |
+
def __init__(self, config: InternVLChatConfig, vision_model=None, language_model=None, use_flash_attn=True):
|
| 52 |
+
super().__init__(config)
|
| 53 |
+
|
| 54 |
+
assert version_cmp(transformers.__version__, '4.37.0', 'ge')
|
| 55 |
+
image_size = config.force_image_size or config.vision_config.image_size
|
| 56 |
+
patch_size = config.vision_config.patch_size
|
| 57 |
+
self.patch_size = patch_size
|
| 58 |
+
self.select_layer = config.select_layer
|
| 59 |
+
self.template = config.template
|
| 60 |
+
self.num_image_token = int((image_size // patch_size) ** 2 * (config.downsample_ratio ** 2))
|
| 61 |
+
self.downsample_ratio = config.downsample_ratio
|
| 62 |
+
self.ps_version = config.ps_version
|
| 63 |
+
use_flash_attn = use_flash_attn if has_flash_attn else False
|
| 64 |
+
config.vision_config.use_flash_attn = True if use_flash_attn else False
|
| 65 |
+
# config.llm_config._attn_implementation = 'flash_attention_2' if use_flash_attn else 'eager'
|
| 66 |
+
|
| 67 |
+
logger.info(f'num_image_token: {self.num_image_token}')
|
| 68 |
+
logger.info(f'ps_version: {self.ps_version}')
|
| 69 |
+
if vision_model is not None:
|
| 70 |
+
self.vision_model = vision_model
|
| 71 |
+
else:
|
| 72 |
+
self.vision_model = InternVisionModel(config.vision_config)
|
| 73 |
+
|
| 74 |
+
if language_model is not None:
|
| 75 |
+
self.language_model = language_model
|
| 76 |
+
else:
|
| 77 |
+
self.language_model = AutoModelForCausalLM.from_config(config.llm_config)
|
| 78 |
+
logger.info(f"language_model type: {type(self.language_model)}")
|
| 79 |
+
|
| 80 |
+
vit_hidden_size = config.vision_config.hidden_size
|
| 81 |
+
llm_hidden_size = config.llm_config.hidden_size
|
| 82 |
+
|
| 83 |
+
self.mlp1 = nn.Sequential(
|
| 84 |
+
nn.LayerNorm(vit_hidden_size * int(1 / self.downsample_ratio) ** 2),
|
| 85 |
+
nn.Linear(vit_hidden_size * int(1 / self.downsample_ratio) ** 2, llm_hidden_size),
|
| 86 |
+
nn.GELU(),
|
| 87 |
+
nn.Linear(llm_hidden_size, llm_hidden_size)
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
self.img_context_token_id = None
|
| 91 |
+
self.conv_template = get_conv_template(self.template)
|
| 92 |
+
self.system_message = self.conv_template.system_message
|
| 93 |
+
|
| 94 |
+
def forward(
|
| 95 |
+
self,
|
| 96 |
+
pixel_values: torch.FloatTensor,
|
| 97 |
+
input_ids: torch.LongTensor = None,
|
| 98 |
+
attention_mask: Optional[torch.Tensor] = None,
|
| 99 |
+
position_ids: Optional[torch.LongTensor] = None,
|
| 100 |
+
image_flags: Optional[torch.LongTensor] = None,
|
| 101 |
+
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
| 102 |
+
labels: Optional[torch.LongTensor] = None,
|
| 103 |
+
use_cache: Optional[bool] = None,
|
| 104 |
+
output_attentions: Optional[bool] = None,
|
| 105 |
+
output_hidden_states: Optional[bool] = None,
|
| 106 |
+
return_dict: Optional[bool] = None,
|
| 107 |
+
) -> Union[Tuple, CausalLMOutputWithPast]:
|
| 108 |
+
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
| 109 |
+
|
| 110 |
+
image_flags = image_flags.squeeze(-1)
|
| 111 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids).clone()
|
| 112 |
+
|
| 113 |
+
vit_embeds = self.extract_feature(pixel_values)
|
| 114 |
+
vit_embeds = vit_embeds[image_flags == 1]
|
| 115 |
+
vit_batch_size = pixel_values.shape[0]
|
| 116 |
+
|
| 117 |
+
B, N, C = input_embeds.shape
|
| 118 |
+
input_embeds = input_embeds.reshape(B * N, C)
|
| 119 |
+
|
| 120 |
+
# if torch.distributed.is_initialized() and torch.distributed.get_rank() == 0:
|
| 121 |
+
# print(f'dynamic ViT batch size: {vit_batch_size}, images per sample: {vit_batch_size / B}, dynamic token length: {N}')
|
| 122 |
+
|
| 123 |
+
input_ids = input_ids.reshape(B * N)
|
| 124 |
+
selected = (input_ids == self.img_context_token_id)
|
| 125 |
+
try:
|
| 126 |
+
input_embeds[selected] = input_embeds[selected] * 0.0 + vit_embeds.reshape(-1, C)
|
| 127 |
+
except Exception as e:
|
| 128 |
+
vit_embeds = vit_embeds.reshape(-1, C)
|
| 129 |
+
print(f'warning: {e}, input_embeds[selected].shape={input_embeds[selected].shape}, '
|
| 130 |
+
f'vit_embeds.shape={vit_embeds.shape}')
|
| 131 |
+
n_token = min(selected.sum(), vit_embeds.size(0))
|
| 132 |
+
input_embeds[selected][:n_token] = input_embeds[selected][:n_token] * 0.0 + vit_embeds[:n_token]
|
| 133 |
+
|
| 134 |
+
input_embeds = input_embeds.reshape(B, N, C)
|
| 135 |
+
|
| 136 |
+
outputs = self.language_model(
|
| 137 |
+
inputs_embeds=input_embeds,
|
| 138 |
+
attention_mask=attention_mask,
|
| 139 |
+
position_ids=position_ids,
|
| 140 |
+
past_key_values=past_key_values,
|
| 141 |
+
use_cache=use_cache,
|
| 142 |
+
output_attentions=output_attentions,
|
| 143 |
+
output_hidden_states=output_hidden_states,
|
| 144 |
+
return_dict=return_dict,
|
| 145 |
+
)
|
| 146 |
+
logits = outputs.logits
|
| 147 |
+
|
| 148 |
+
loss = None
|
| 149 |
+
aux_loss = None
|
| 150 |
+
if labels is not None:
|
| 151 |
+
# Shift so that tokens < n predict n
|
| 152 |
+
shift_logits = logits[..., :-1, :].contiguous()
|
| 153 |
+
shift_labels = labels[..., 1:].contiguous()
|
| 154 |
+
# Flatten the tokens
|
| 155 |
+
loss_fct = CrossEntropyLoss()
|
| 156 |
+
shift_logits = shift_logits.view(-1, self.language_model.config.vocab_size)
|
| 157 |
+
shift_labels = shift_labels.view(-1)
|
| 158 |
+
# Enable model parallelism
|
| 159 |
+
shift_labels = shift_labels.to(shift_logits.device)
|
| 160 |
+
loss = loss_fct(shift_logits, shift_labels)
|
| 161 |
+
|
| 162 |
+
if getattr(outputs, 'router_logits', None) is not None:
|
| 163 |
+
aux_loss = load_balancing_loss_func(
|
| 164 |
+
outputs.router_logits,
|
| 165 |
+
self.language_model.num_experts,
|
| 166 |
+
self.language_model.num_experts_per_tok,
|
| 167 |
+
attention_mask,
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
if loss is not None:
|
| 171 |
+
loss = loss + self.language_model.router_aux_loss_coef * aux_loss.to(loss.device)
|
| 172 |
+
|
| 173 |
+
if not return_dict:
|
| 174 |
+
output = (logits,) + outputs[1:]
|
| 175 |
+
return (loss,) + output if loss is not None else output
|
| 176 |
+
|
| 177 |
+
if aux_loss is not None:
|
| 178 |
+
return MoeCausalLMOutputWithPast(
|
| 179 |
+
loss=loss,
|
| 180 |
+
aux_loss=aux_loss,
|
| 181 |
+
logits=logits,
|
| 182 |
+
past_key_values=outputs.past_key_values,
|
| 183 |
+
hidden_states=outputs.hidden_states,
|
| 184 |
+
attentions=outputs.attentions,
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
return CausalLMOutputWithPast(
|
| 188 |
+
loss=loss,
|
| 189 |
+
logits=logits,
|
| 190 |
+
past_key_values=outputs.past_key_values,
|
| 191 |
+
hidden_states=outputs.hidden_states,
|
| 192 |
+
attentions=outputs.attentions,
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
def pixel_shuffle(self, x, scale_factor=0.5):
|
| 196 |
+
n, w, h, c = x.size()
|
| 197 |
+
# N, W, H, C --> N, W, H * scale, C // scale
|
| 198 |
+
x = x.view(n, w, int(h * scale_factor), int(c / scale_factor))
|
| 199 |
+
# N, W, H * scale, C // scale --> N, H * scale, W, C // scale
|
| 200 |
+
x = x.permute(0, 2, 1, 3).contiguous()
|
| 201 |
+
# N, H * scale, W, C // scale --> N, H * scale, W * scale, C // (scale ** 2)
|
| 202 |
+
x = x.view(n, int(h * scale_factor), int(w * scale_factor),
|
| 203 |
+
int(c / (scale_factor * scale_factor)))
|
| 204 |
+
if self.ps_version == 'v1':
|
| 205 |
+
warnings.warn("In ps_version 'v1', the height and width have not been swapped back, "
|
| 206 |
+
'which results in a transposed image.')
|
| 207 |
+
else:
|
| 208 |
+
x = x.permute(0, 2, 1, 3).contiguous()
|
| 209 |
+
return x
|
| 210 |
+
|
| 211 |
+
def extract_feature(self, pixel_values):
|
| 212 |
+
if self.select_layer == -1:
|
| 213 |
+
vit_embeds = self.vision_model(
|
| 214 |
+
pixel_values=pixel_values,
|
| 215 |
+
output_hidden_states=False,
|
| 216 |
+
return_dict=True).last_hidden_state
|
| 217 |
+
else:
|
| 218 |
+
vit_embeds = self.vision_model(
|
| 219 |
+
pixel_values=pixel_values,
|
| 220 |
+
output_hidden_states=True,
|
| 221 |
+
return_dict=True).hidden_states[self.select_layer]
|
| 222 |
+
vit_embeds = vit_embeds[:, 1:, :]
|
| 223 |
+
|
| 224 |
+
h = w = int(vit_embeds.shape[1] ** 0.5)
|
| 225 |
+
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], h, w, -1)
|
| 226 |
+
vit_embeds = self.pixel_shuffle(vit_embeds, scale_factor=self.downsample_ratio)
|
| 227 |
+
vit_embeds = vit_embeds.reshape(vit_embeds.shape[0], -1, vit_embeds.shape[-1])
|
| 228 |
+
vit_embeds = self.mlp1(vit_embeds)
|
| 229 |
+
return vit_embeds
|
| 230 |
+
|
| 231 |
+
def batch_chat(self, tokenizer, pixel_values, questions, generation_config, num_patches_list=None,
|
| 232 |
+
history=None, return_history=False, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>',
|
| 233 |
+
IMG_CONTEXT_TOKEN='<IMG_CONTEXT>', verbose=False, image_counts=None):
|
| 234 |
+
if history is not None or return_history:
|
| 235 |
+
print('Now multi-turn chat is not supported in batch_chat.')
|
| 236 |
+
raise NotImplementedError
|
| 237 |
+
|
| 238 |
+
if image_counts is not None:
|
| 239 |
+
num_patches_list = image_counts
|
| 240 |
+
print('Warning: `image_counts` is deprecated. Please use `num_patches_list` instead.')
|
| 241 |
+
|
| 242 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(IMG_CONTEXT_TOKEN)
|
| 243 |
+
self.img_context_token_id = img_context_token_id
|
| 244 |
+
|
| 245 |
+
if verbose and pixel_values is not None:
|
| 246 |
+
image_bs = pixel_values.shape[0]
|
| 247 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 248 |
+
|
| 249 |
+
queries = []
|
| 250 |
+
for idx, num_patches in enumerate(num_patches_list):
|
| 251 |
+
question = questions[idx]
|
| 252 |
+
if pixel_values is not None and '<image>' not in question:
|
| 253 |
+
question = '<image>\n' + question
|
| 254 |
+
template = get_conv_template(self.template)
|
| 255 |
+
template.system_message = self.system_message
|
| 256 |
+
template.append_message(template.roles[0], question)
|
| 257 |
+
template.append_message(template.roles[1], None)
|
| 258 |
+
query = template.get_prompt()
|
| 259 |
+
|
| 260 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
|
| 261 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 262 |
+
queries.append(query)
|
| 263 |
+
|
| 264 |
+
tokenizer.padding_side = 'left'
|
| 265 |
+
model_inputs = tokenizer(queries, return_tensors='pt', padding=True)
|
| 266 |
+
input_ids = model_inputs['input_ids'].to(self.device)
|
| 267 |
+
attention_mask = model_inputs['attention_mask'].to(self.device)
|
| 268 |
+
|
| 269 |
+
sep = template.sep.strip() if template.sep2 is None else template.sep2.strip()
|
| 270 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(sep)
|
| 271 |
+
|
| 272 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 273 |
+
generation_output = self.generate(
|
| 274 |
+
pixel_values=pixel_values,
|
| 275 |
+
input_ids=input_ids,
|
| 276 |
+
attention_mask=attention_mask,
|
| 277 |
+
**generation_config
|
| 278 |
+
)
|
| 279 |
+
responses = tokenizer.batch_decode(generation_output, skip_special_tokens=False)
|
| 280 |
+
responses = [response.split(sep)[0].split('<|message|>')[-1].strip() for response in responses]
|
| 281 |
+
return responses
|
| 282 |
+
|
| 283 |
+
def chat(self, tokenizer, pixel_values, question, generation_config, history=None, return_history=False,
|
| 284 |
+
num_patches_list=None, IMG_START_TOKEN='<img>', IMG_END_TOKEN='</img>', IMG_CONTEXT_TOKEN='<IMG_CONTEXT>',
|
| 285 |
+
verbose=False):
|
| 286 |
+
|
| 287 |
+
if history is None and pixel_values is not None and '<image>' not in question:
|
| 288 |
+
question = '<image>\n' + question
|
| 289 |
+
|
| 290 |
+
if num_patches_list is None:
|
| 291 |
+
num_patches_list = [pixel_values.shape[0]] if pixel_values is not None else []
|
| 292 |
+
assert pixel_values is None or len(pixel_values) == sum(num_patches_list)
|
| 293 |
+
|
| 294 |
+
img_context_token_id = tokenizer.convert_tokens_to_ids(IMG_CONTEXT_TOKEN)
|
| 295 |
+
self.img_context_token_id = img_context_token_id
|
| 296 |
+
|
| 297 |
+
template = get_conv_template(self.template)
|
| 298 |
+
template.system_message = self.system_message
|
| 299 |
+
|
| 300 |
+
sep = template.sep.strip() if template.sep2 is None else template.sep2.strip()
|
| 301 |
+
eos_token_id = tokenizer.convert_tokens_to_ids(sep)
|
| 302 |
+
|
| 303 |
+
history = [] if history is None else history
|
| 304 |
+
for (old_question, old_answer) in history:
|
| 305 |
+
template.append_message(template.roles[0], old_question)
|
| 306 |
+
template.append_message(template.roles[1], old_answer)
|
| 307 |
+
template.append_message(template.roles[0], question)
|
| 308 |
+
template.append_message(template.roles[1], None)
|
| 309 |
+
query = template.get_prompt()
|
| 310 |
+
|
| 311 |
+
if verbose and pixel_values is not None:
|
| 312 |
+
image_bs = pixel_values.shape[0]
|
| 313 |
+
print(f'dynamic ViT batch size: {image_bs}')
|
| 314 |
+
|
| 315 |
+
for num_patches in num_patches_list:
|
| 316 |
+
image_tokens = IMG_START_TOKEN + IMG_CONTEXT_TOKEN * self.num_image_token * num_patches + IMG_END_TOKEN
|
| 317 |
+
query = query.replace('<image>', image_tokens, 1)
|
| 318 |
+
|
| 319 |
+
model_inputs = tokenizer(query, return_tensors='pt')
|
| 320 |
+
input_ids = model_inputs['input_ids'].to(self.device)
|
| 321 |
+
attention_mask = model_inputs['attention_mask'].to(self.device)
|
| 322 |
+
generation_config['eos_token_id'] = eos_token_id
|
| 323 |
+
generation_output = self.generate(
|
| 324 |
+
pixel_values=pixel_values,
|
| 325 |
+
input_ids=input_ids,
|
| 326 |
+
attention_mask=attention_mask,
|
| 327 |
+
**generation_config
|
| 328 |
+
)
|
| 329 |
+
response = tokenizer.batch_decode(generation_output, skip_special_tokens=False)[0]
|
| 330 |
+
response = response.split(sep)[0].strip()
|
| 331 |
+
response = response.split('<|message|>')[-1].strip()
|
| 332 |
+
|
| 333 |
+
history.append((question, response))
|
| 334 |
+
if return_history:
|
| 335 |
+
return response, history
|
| 336 |
+
else:
|
| 337 |
+
query_to_print = query.replace(IMG_CONTEXT_TOKEN, '')
|
| 338 |
+
query_to_print = query_to_print.replace(f'{IMG_START_TOKEN}{IMG_END_TOKEN}', '<image>')
|
| 339 |
+
if verbose:
|
| 340 |
+
print(query_to_print, response)
|
| 341 |
+
return response
|
| 342 |
+
|
| 343 |
+
@torch.no_grad()
|
| 344 |
+
def generate(
|
| 345 |
+
self,
|
| 346 |
+
pixel_values: Optional[torch.FloatTensor] = None,
|
| 347 |
+
input_ids: Optional[torch.FloatTensor] = None,
|
| 348 |
+
attention_mask: Optional[torch.LongTensor] = None,
|
| 349 |
+
visual_features: Optional[torch.FloatTensor] = None,
|
| 350 |
+
generation_config: Optional[GenerationConfig] = None,
|
| 351 |
+
output_hidden_states: Optional[bool] = None,
|
| 352 |
+
**generate_kwargs,
|
| 353 |
+
) -> torch.LongTensor:
|
| 354 |
+
|
| 355 |
+
assert self.img_context_token_id is not None
|
| 356 |
+
if pixel_values is not None:
|
| 357 |
+
if visual_features is not None:
|
| 358 |
+
vit_embeds = visual_features
|
| 359 |
+
else:
|
| 360 |
+
vit_embeds = self.extract_feature(pixel_values)
|
| 361 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 362 |
+
B, N, C = input_embeds.shape
|
| 363 |
+
input_embeds = input_embeds.reshape(B * N, C)
|
| 364 |
+
|
| 365 |
+
input_ids = input_ids.reshape(B * N)
|
| 366 |
+
selected = (input_ids == self.img_context_token_id)
|
| 367 |
+
assert selected.sum() != 0
|
| 368 |
+
input_embeds[selected] = vit_embeds.reshape(-1, C).to(input_embeds.device)
|
| 369 |
+
|
| 370 |
+
input_embeds = input_embeds.reshape(B, N, C)
|
| 371 |
+
else:
|
| 372 |
+
input_embeds = self.language_model.get_input_embeddings()(input_ids)
|
| 373 |
+
|
| 374 |
+
outputs = self.language_model.generate(
|
| 375 |
+
inputs_embeds=input_embeds,
|
| 376 |
+
attention_mask=attention_mask,
|
| 377 |
+
generation_config=generation_config,
|
| 378 |
+
output_hidden_states=output_hidden_states,
|
| 379 |
+
use_cache=True,
|
| 380 |
+
**generate_kwargs,
|
| 381 |
+
)
|
| 382 |
+
|
| 383 |
+
return outputs
|
| 384 |
+
|
| 385 |
+
@property
|
| 386 |
+
def lm_head(self):
|
| 387 |
+
return self.language_model.get_output_embeddings()
|
| 388 |
+
|
| 389 |
+
def get_output_embeddings(self):
|
| 390 |
+
return self.language_model.get_output_embeddings()
|
| 391 |
+
|
| 392 |
+
def get_input_embeddings(self):
|
| 393 |
+
return self.language_model.get_input_embeddings()
|
| 394 |
+
|
| 395 |
+
def set_input_embeddings(self, value):
|
| 396 |
+
return self.language_model.set_input_embeddings(value)
|
| 397 |
+
|
| 398 |
+
def set_output_embeddings(self, value):
|
| 399 |
+
return self.language_model.set_output_embeddings(value)
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"crop_size": null,
|
| 3 |
+
"crop_to_patches": false,
|
| 4 |
+
"data_format": "channels_first",
|
| 5 |
+
"default_to_square": true,
|
| 6 |
+
"device": null,
|
| 7 |
+
"do_center_crop": null,
|
| 8 |
+
"do_convert_rgb": true,
|
| 9 |
+
"do_normalize": true,
|
| 10 |
+
"do_rescale": true,
|
| 11 |
+
"do_resize": true,
|
| 12 |
+
"image_mean": [
|
| 13 |
+
0.485,
|
| 14 |
+
0.456,
|
| 15 |
+
0.406
|
| 16 |
+
],
|
| 17 |
+
"image_processor_type": "GotOcr2ImageProcessorFast",
|
| 18 |
+
"image_std": [
|
| 19 |
+
0.229,
|
| 20 |
+
0.224,
|
| 21 |
+
0.225
|
| 22 |
+
],
|
| 23 |
+
"input_data_format": null,
|
| 24 |
+
"max_patches": 12,
|
| 25 |
+
"min_patches": 1,
|
| 26 |
+
"processor_class": "InternVLProcessor",
|
| 27 |
+
"resample": 3,
|
| 28 |
+
"rescale_factor": 0.00392156862745098,
|
| 29 |
+
"return_tensors": null,
|
| 30 |
+
"size": {
|
| 31 |
+
"height": 448,
|
| 32 |
+
"width": 448
|
| 33 |
+
}
|
| 34 |
+
}
|
processor_config.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"image_seq_length": 256,
|
| 3 |
+
"processor_class": "InternVLProcessor"
|
| 4 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|startoftext|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|return|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<|endoftext|>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
}
|
| 23 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0c5d65adb9e25fe2d444137550e4bf7e9f3501f1eb542ebb8c8fdc27ea9863f1
|
| 3 |
+
size 27869826
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,256 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_eos_token": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"199998": {
|
| 5 |
+
"content": "<|startoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"199999": {
|
| 13 |
+
"content": "<|endoftext|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"200000": {
|
| 21 |
+
"content": "<|reserved_200000|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"200001": {
|
| 29 |
+
"content": "<|reserved_200001|>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"200002": {
|
| 37 |
+
"content": "<|return|>",
|
| 38 |
+
"lstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": false,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"200003": {
|
| 45 |
+
"content": "<|constrain|>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"200004": {
|
| 53 |
+
"content": "<|reserved_200004|>",
|
| 54 |
+
"lstrip": false,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": false,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"200005": {
|
| 61 |
+
"content": "<|channel|>",
|
| 62 |
+
"lstrip": false,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": false,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"200006": {
|
| 69 |
+
"content": "<|start|>",
|
| 70 |
+
"lstrip": false,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": false,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": true
|
| 75 |
+
},
|
| 76 |
+
"200007": {
|
| 77 |
+
"content": "<|end|>",
|
| 78 |
+
"lstrip": false,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": false,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": true
|
| 83 |
+
},
|
| 84 |
+
"200008": {
|
| 85 |
+
"content": "<|message|>",
|
| 86 |
+
"lstrip": false,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": false,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": true
|
| 91 |
+
},
|
| 92 |
+
"200009": {
|
| 93 |
+
"content": "<|reserved_200009|>",
|
| 94 |
+
"lstrip": false,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": false,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": true
|
| 99 |
+
},
|
| 100 |
+
"200010": {
|
| 101 |
+
"content": "<|reserved_200010|>",
|
| 102 |
+
"lstrip": false,
|
| 103 |
+
"normalized": false,
|
| 104 |
+
"rstrip": false,
|
| 105 |
+
"single_word": false,
|
| 106 |
+
"special": true
|
| 107 |
+
},
|
| 108 |
+
"200011": {
|
| 109 |
+
"content": "<|reserved_200011|>",
|
| 110 |
+
"lstrip": false,
|
| 111 |
+
"normalized": false,
|
| 112 |
+
"rstrip": false,
|
| 113 |
+
"single_word": false,
|
| 114 |
+
"special": true
|
| 115 |
+
},
|
| 116 |
+
"200012": {
|
| 117 |
+
"content": "<|call|>",
|
| 118 |
+
"lstrip": false,
|
| 119 |
+
"normalized": false,
|
| 120 |
+
"rstrip": false,
|
| 121 |
+
"single_word": false,
|
| 122 |
+
"special": true
|
| 123 |
+
},
|
| 124 |
+
"200013": {
|
| 125 |
+
"content": "<|reserved_200013|>",
|
| 126 |
+
"lstrip": false,
|
| 127 |
+
"normalized": false,
|
| 128 |
+
"rstrip": false,
|
| 129 |
+
"single_word": false,
|
| 130 |
+
"special": true
|
| 131 |
+
},
|
| 132 |
+
"200014": {
|
| 133 |
+
"content": "<|reserved_200014|>",
|
| 134 |
+
"lstrip": false,
|
| 135 |
+
"normalized": false,
|
| 136 |
+
"rstrip": false,
|
| 137 |
+
"single_word": false,
|
| 138 |
+
"special": true
|
| 139 |
+
},
|
| 140 |
+
"200015": {
|
| 141 |
+
"content": "<|reserved_200015|>",
|
| 142 |
+
"lstrip": false,
|
| 143 |
+
"normalized": false,
|
| 144 |
+
"rstrip": false,
|
| 145 |
+
"single_word": false,
|
| 146 |
+
"special": true
|
| 147 |
+
},
|
| 148 |
+
"200016": {
|
| 149 |
+
"content": "<|reserved_200016|>",
|
| 150 |
+
"lstrip": false,
|
| 151 |
+
"normalized": false,
|
| 152 |
+
"rstrip": false,
|
| 153 |
+
"single_word": false,
|
| 154 |
+
"special": true
|
| 155 |
+
},
|
| 156 |
+
"200017": {
|
| 157 |
+
"content": "<|reserved_200017|>",
|
| 158 |
+
"lstrip": false,
|
| 159 |
+
"normalized": false,
|
| 160 |
+
"rstrip": false,
|
| 161 |
+
"single_word": false,
|
| 162 |
+
"special": true
|
| 163 |
+
},
|
| 164 |
+
"200018": {
|
| 165 |
+
"content": "<|endofprompt|>",
|
| 166 |
+
"lstrip": false,
|
| 167 |
+
"normalized": false,
|
| 168 |
+
"rstrip": false,
|
| 169 |
+
"single_word": false,
|
| 170 |
+
"special": true
|
| 171 |
+
},
|
| 172 |
+
"200019": {
|
| 173 |
+
"content": "<img>",
|
| 174 |
+
"lstrip": false,
|
| 175 |
+
"normalized": false,
|
| 176 |
+
"rstrip": false,
|
| 177 |
+
"single_word": false,
|
| 178 |
+
"special": true
|
| 179 |
+
},
|
| 180 |
+
"200020": {
|
| 181 |
+
"content": "</img>",
|
| 182 |
+
"lstrip": false,
|
| 183 |
+
"normalized": false,
|
| 184 |
+
"rstrip": false,
|
| 185 |
+
"single_word": false,
|
| 186 |
+
"special": true
|
| 187 |
+
},
|
| 188 |
+
"200021": {
|
| 189 |
+
"content": "<IMG_CONTEXT>",
|
| 190 |
+
"lstrip": false,
|
| 191 |
+
"normalized": false,
|
| 192 |
+
"rstrip": false,
|
| 193 |
+
"single_word": false,
|
| 194 |
+
"special": true
|
| 195 |
+
},
|
| 196 |
+
"200022": {
|
| 197 |
+
"content": "<quad>",
|
| 198 |
+
"lstrip": false,
|
| 199 |
+
"normalized": false,
|
| 200 |
+
"rstrip": false,
|
| 201 |
+
"single_word": false,
|
| 202 |
+
"special": true
|
| 203 |
+
},
|
| 204 |
+
"200023": {
|
| 205 |
+
"content": "</quad>",
|
| 206 |
+
"lstrip": false,
|
| 207 |
+
"normalized": false,
|
| 208 |
+
"rstrip": false,
|
| 209 |
+
"single_word": false,
|
| 210 |
+
"special": true
|
| 211 |
+
},
|
| 212 |
+
"200024": {
|
| 213 |
+
"content": "<ref>",
|
| 214 |
+
"lstrip": false,
|
| 215 |
+
"normalized": false,
|
| 216 |
+
"rstrip": false,
|
| 217 |
+
"single_word": false,
|
| 218 |
+
"special": true
|
| 219 |
+
},
|
| 220 |
+
"200025": {
|
| 221 |
+
"content": "</ref>",
|
| 222 |
+
"lstrip": false,
|
| 223 |
+
"normalized": false,
|
| 224 |
+
"rstrip": false,
|
| 225 |
+
"single_word": false,
|
| 226 |
+
"special": true
|
| 227 |
+
},
|
| 228 |
+
"200026": {
|
| 229 |
+
"content": "<box>",
|
| 230 |
+
"lstrip": false,
|
| 231 |
+
"normalized": false,
|
| 232 |
+
"rstrip": false,
|
| 233 |
+
"single_word": false,
|
| 234 |
+
"special": true
|
| 235 |
+
},
|
| 236 |
+
"200027": {
|
| 237 |
+
"content": "</box>",
|
| 238 |
+
"lstrip": false,
|
| 239 |
+
"normalized": false,
|
| 240 |
+
"rstrip": false,
|
| 241 |
+
"single_word": false,
|
| 242 |
+
"special": true
|
| 243 |
+
}
|
| 244 |
+
},
|
| 245 |
+
"bos_token": "<|startoftext|>",
|
| 246 |
+
"clean_up_tokenization_spaces": false,
|
| 247 |
+
"eos_token": "<|return|>",
|
| 248 |
+
"extra_special_tokens": {},
|
| 249 |
+
"model_input_names": [
|
| 250 |
+
"input_ids",
|
| 251 |
+
"attention_mask"
|
| 252 |
+
],
|
| 253 |
+
"model_max_length": 16384,
|
| 254 |
+
"pad_token": "<|endoftext|>",
|
| 255 |
+
"tokenizer_class": "PreTrainedTokenizerFast"
|
| 256 |
+
}
|
video_preprocessor_config.json
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_valid_kwargs_names": [
|
| 3 |
+
"do_convert_rgb",
|
| 4 |
+
"do_resize",
|
| 5 |
+
"size",
|
| 6 |
+
"size_divisor",
|
| 7 |
+
"default_to_square",
|
| 8 |
+
"resample",
|
| 9 |
+
"do_rescale",
|
| 10 |
+
"rescale_factor",
|
| 11 |
+
"do_normalize",
|
| 12 |
+
"image_mean",
|
| 13 |
+
"image_std",
|
| 14 |
+
"do_pad",
|
| 15 |
+
"do_center_crop",
|
| 16 |
+
"crop_size",
|
| 17 |
+
"data_format",
|
| 18 |
+
"input_data_format",
|
| 19 |
+
"device"
|
| 20 |
+
],
|
| 21 |
+
"crop_size": null,
|
| 22 |
+
"data_format": "channels_first",
|
| 23 |
+
"default_to_square": true,
|
| 24 |
+
"device": null,
|
| 25 |
+
"do_center_crop": null,
|
| 26 |
+
"do_convert_rgb": true,
|
| 27 |
+
"do_normalize": true,
|
| 28 |
+
"do_pad": null,
|
| 29 |
+
"do_rescale": true,
|
| 30 |
+
"do_resize": true,
|
| 31 |
+
"image_mean": [
|
| 32 |
+
0.48145466,
|
| 33 |
+
0.4578275,
|
| 34 |
+
0.40821073
|
| 35 |
+
],
|
| 36 |
+
"image_std": [
|
| 37 |
+
0.26862954,
|
| 38 |
+
0.26130258,
|
| 39 |
+
0.27577711
|
| 40 |
+
],
|
| 41 |
+
"input_data_format": null,
|
| 42 |
+
"model_valid_processing_keys": [
|
| 43 |
+
"do_convert_rgb",
|
| 44 |
+
"do_resize",
|
| 45 |
+
"size",
|
| 46 |
+
"size_divisor",
|
| 47 |
+
"default_to_square",
|
| 48 |
+
"resample",
|
| 49 |
+
"do_rescale",
|
| 50 |
+
"rescale_factor",
|
| 51 |
+
"do_normalize",
|
| 52 |
+
"image_mean",
|
| 53 |
+
"image_std",
|
| 54 |
+
"do_pad",
|
| 55 |
+
"do_center_crop",
|
| 56 |
+
"crop_size",
|
| 57 |
+
"data_format",
|
| 58 |
+
"input_data_format",
|
| 59 |
+
"device"
|
| 60 |
+
],
|
| 61 |
+
"processor_class": "InternVLProcessor",
|
| 62 |
+
"resample": 3,
|
| 63 |
+
"rescale_factor": 0.00392156862745098,
|
| 64 |
+
"size": {
|
| 65 |
+
"height": 384,
|
| 66 |
+
"width": 384
|
| 67 |
+
},
|
| 68 |
+
"size_divisor": null,
|
| 69 |
+
"video_processor_type": "InternVLVideoProcessor"
|
| 70 |
+
}
|