
Antidote Project
Collection
Data and models generated within the Antidote Project (https://univ-cotedazur.eu/antidote) • 20 items • Updated • 6

This model is a fine-tuned version of bert-base-multilingual-cased for the argument component detection task on AbstRCT data in English, Spanish, French and Italian (https://huggingface.co/datasets/HiTZ/multilingual-abstrct).
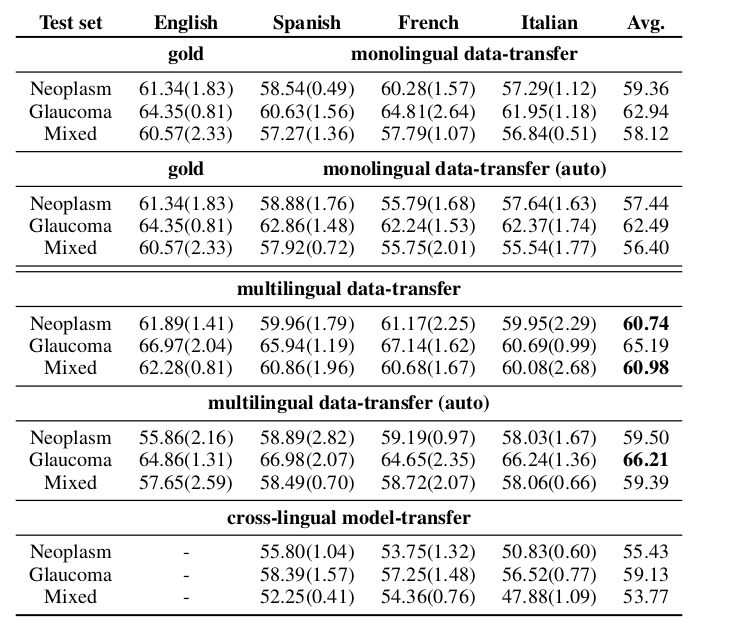
F1-macro scores (at sequence level) and their averages per test set from the argument component detection results of monolingual, monolingual automatically post-processed, multilingual, multilingual automatically post-processed, and crosslingual experiments.
The following hyperparameters were used during training:
Contact: Anar Yeginbergen and Rodrigo Agerri HiTZ Center - Ixa, University of the Basque Country UPV/EHU
Base model
google-bert/bert-base-multilingual-cased