
ModernBERT Science DAPT v2
Summary
- +58% Recall@1 improvement on scientific retrieval tasks vs ModernBERT-base
- MLM loss improved from 1.081 → 0.985
- Classification performance unchanged (~0.92 macro F1)
- Best checkpoint selected at 50k steps (later training degraded retrieval)
Appropriate for semantic search, retrieval, and RAG over scientific text.
Model Version
This model corresponds to the 50,000-step checkpoint, selected via checkpoint evaluation.
Longer training runs (60k–80k steps) continued to reduce MLM loss but degraded retrieval and classification performance.
Model Lineage
- v1: Initial DAPT run (20k steps)
- v2 (this model): Checkpoint-selected at 50k steps with improved retrieval
Future work:
- longer-context evaluation
- expanded PMC coverage
- task-specific fine-tuning
Objective
Evaluate whether domain-adaptive pretraining (DAPT) on a large, curated scientific corpus improves downstream performance of ModernBERT-base on scientific text tasks.
Dataset
Sources
- PMC Open Access (commercial subset)
- arXiv metadata (title + abstract)
Filtering & Policy
- Years: 2015–2024
- Language: English
- License: permissive (CC-BY variants, CC0)
Deduplication
- Exact match removal via SHA256 hash of normalized text
- Conflict resolution:
- Prefer longer documents (char_len)
- Prefer PMC over arXiv
- Stable ordering fallback
Final Training Corpus
- Total documents: 518,531
- arXiv: 276,126
- PMC: 242,405
- Token length (sample):
- median: ~275 tokens
- p95: ~506 tokens
Training Setup
- Base model: answerdotai/ModernBERT-base
- Base model context length: up to 8192 (padding disabled)
- DAPT training sequence length: 512 tokens
- Framework: Hugging Face Trainer
- Device: Apple Silicon (MPS)
Training Run
- Selected checkpoint: 50,000
- Held-out MLM eval loss:: 0.985
- Throughput: ~0.6 steps/sec
- Estimated tokens seen: 450 million tokens (~3x corpus exposure)
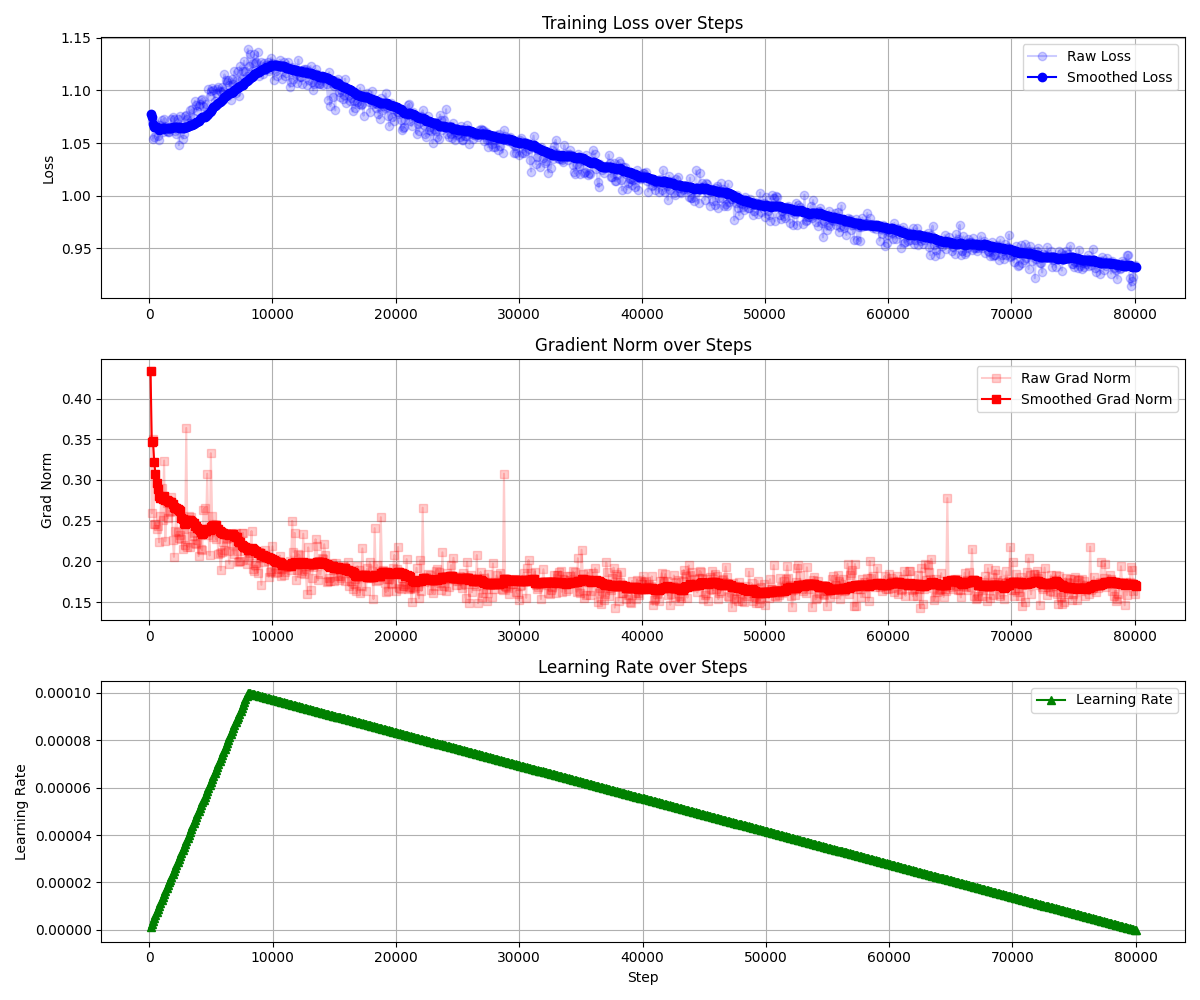
The training process was stable, with decreasing loss and well-behaved gradient norms.
Evaluation
Evaluation Strategy
Evaluation included three proxy evaluations:
- Held-out MLM loss (intrinsic)
- Title → Abstract retrieval (semantic similarity)
- arXiv category classification (top-15) (supervised proxy)
Evaluation Highlights
Retrieval (Title → Abstract)

| Metric | Base | DAPT-20k | DAPT-50k | Δ (base) |
|---|---|---|---|---|
| Recall@1 | 0.279 | 0.338 | 0.440 | +58% |
| Recall@5 | 0.565 | 0.668 | 0.761 | +35% |
| MRR | 0.412 | 0.485 | 0.580 | +41% |
Result: Significant improvement in semantic matching and representation quality.
Held-out MLM Loss
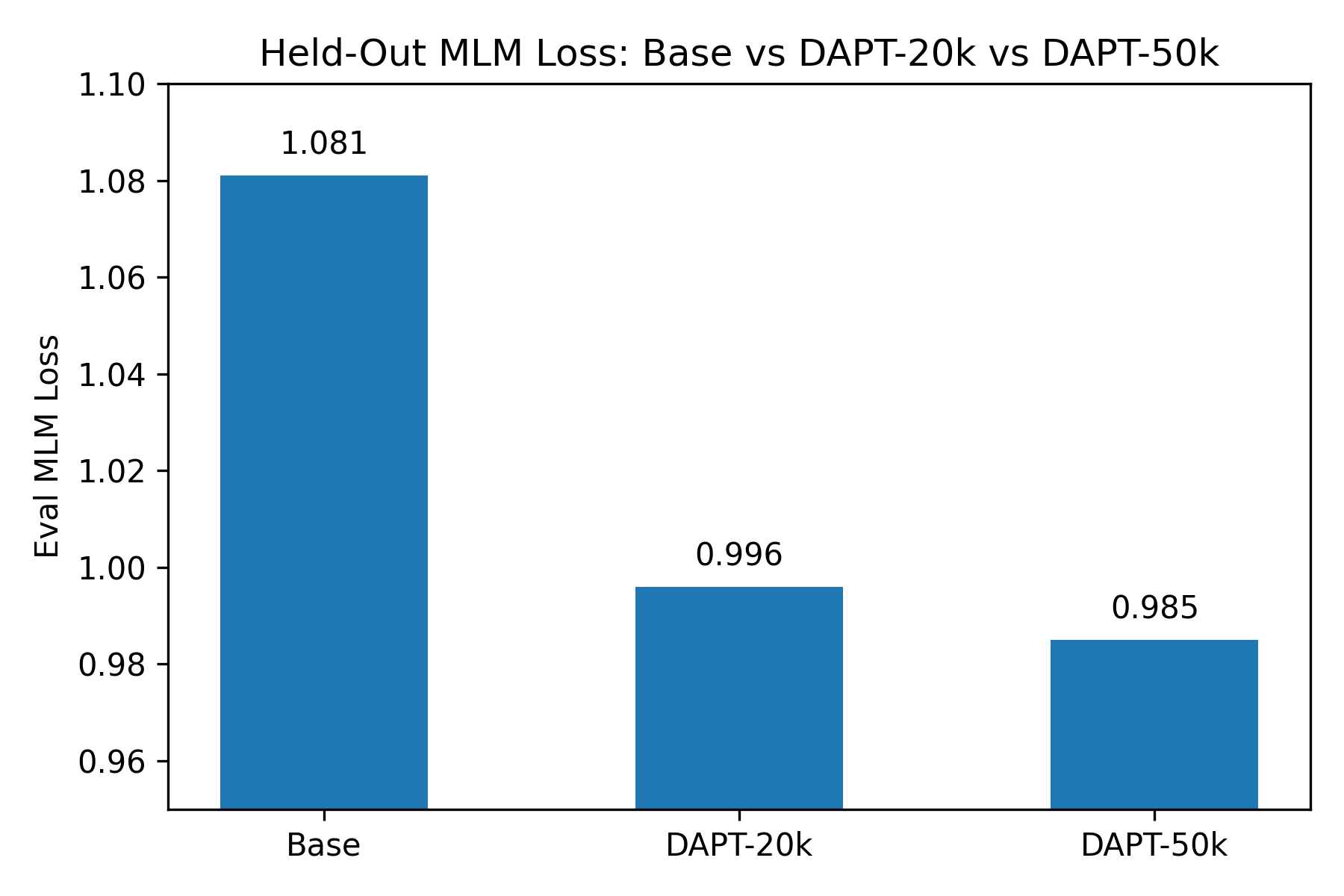
| Model | Eval Loss |
|---|---|
| Base | 1.081 |
| DAPT-20k | 0.996 |
| DAPT-50k | 0.985 |
Result: Clear improvement in language modeling on scientific text. Of note, despite continued MLM eval loss beyond 50,000 steps, retrieval and classification performance declined significantly.
Classification (arXiv Top-15)
| Metric | Base | DAPT-20k | DAPT-50k |
|---|---|---|---|
| Accuracy | 0.9161 | 0.9150 | 0.9151 |
| Macro F1 | 0.9168 | 0.9156 | 0.9159 |
Result: No meaningful change (within expected variance). However, classification performance dropped significantly beyond 50,000 steps.
Interpretation
- DAPT successfully improved scientific language understanding, as shown by:
- lower MLM loss
- strong gains in retrieval
- Classification performance remained effectively unchanged, likely due to:
- already high baseline performance (~0.92 macro F1)
- task-specific label boundaries not aligning with DAPT improvements
- retrieval vs classification capturing different capabilities
Key Finding
- MLM loss continued improving beyond 50k steps
- But retrieval and classification performance declined
This suggests over-specialization to the MLM objective, where improvements in token prediction no longer translate to better semantic representations.
This informed the decision to select the 50k checkpoint.
Additional Validation (Internal Task)
On an internal document relevance task:
- Performance was comparable to ModernBERT-base
- Precision increased, recall slightly decreased
- Threshold tuning yielded improved F1 vs baseline
This suggests improved representation quality but different calibration behavior.
Conclusion
The DAPT model demonstrates meaningful improvement in scientific-domain representation, particularly for:
- semantic similarity
- retrieval-style tasks
- general language modeling
While classification gains were not observed on this proxy task, there is no evidence of degradation, and improvements in representation quality suggest likely benefit for downstream tasks involving:
- relevance classification
- semantic search
- RAG pipelines
Known Limitations
- PMC data currently skewed toward 2015–2016
- arXiv used only title + abstract (no full text)
- Classification proxy limited to first-category labeling
- No multi-task or instruction tuning applied
Usage
from transformers import AutoTokenizer, AutoModel
model_id = "brettgenz/modernbert-science-dapt-v2"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModel.from_pretrained(model_id)
text = "Deep learning approaches for protein structure prediction"
inputs = tokenizer(text, return_tensors="pt", truncation=True)
outputs = model(**inputs)
embeddings = outputs.last_hidden_state
Notes
This model is intended as a drop-in replacement for ModernBERT-base when working with scientific or technical text.
License
This model is released under the Apache 2.0 License.
The training data consists of publicly available open-access scientific content under permissive licenses (e.g., CC-BY, CC0).
- Downloads last month
- 26
Model tree for brettgenz/modernbert-science-dapt-v2
Base model
answerdotai/ModernBERT-base