
Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision
Paper
• 2202.08360 • Published
RegNet model trained on imagenet-1k. It was introduced in the paper Vision Models Are More Robust And Fair When Pretrained On Uncurated Images Without Supervision and first released in this repository.
Disclaimer: The team releasing RegNet did not write a model card for this model so this model card has been written by the Hugging Face team.
The authors trained RegNets models in a self-supervised fashion on bilion of random images from the internet. This model is later finetuned on ImageNet
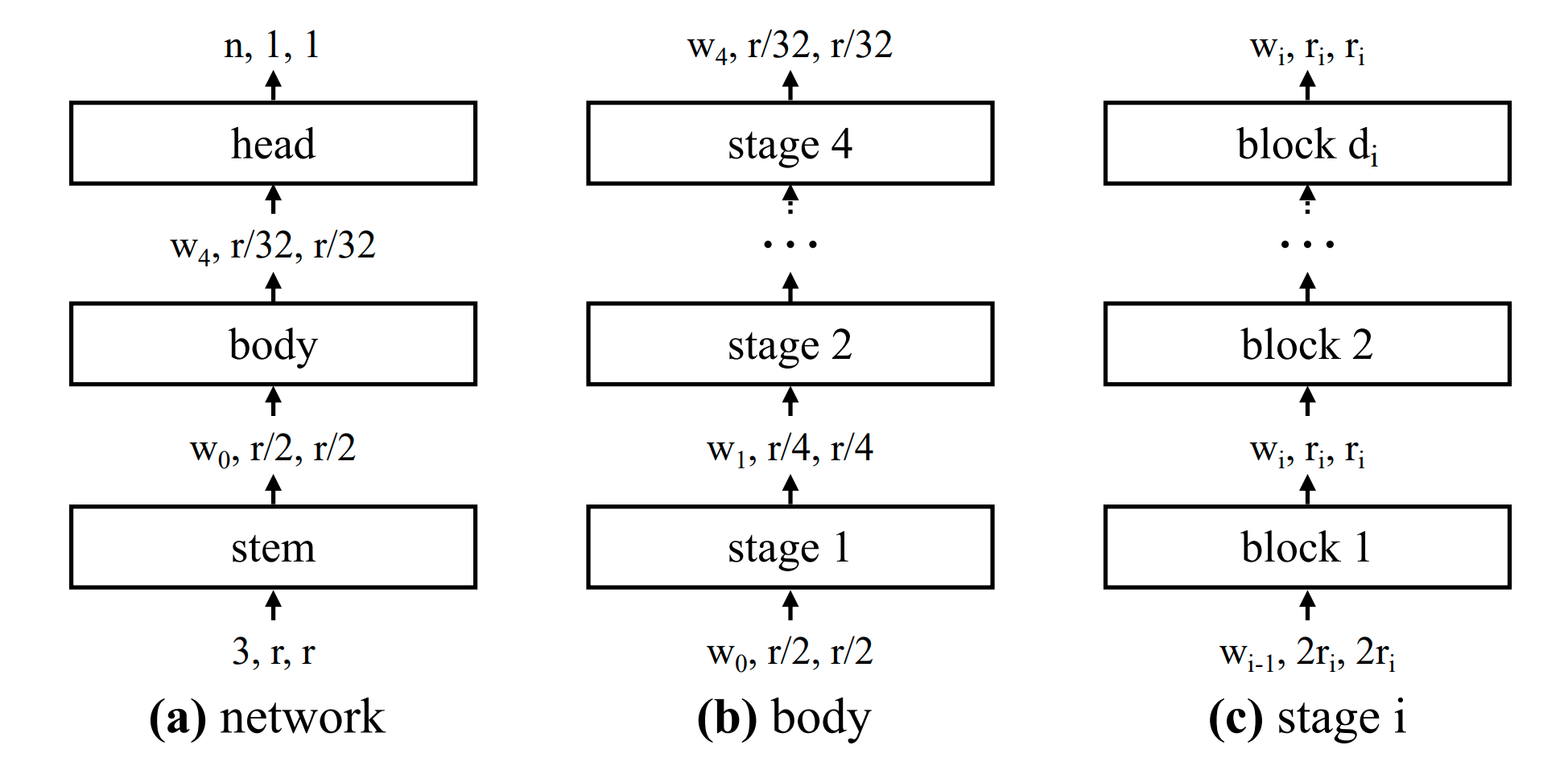
You can use the raw model for image classification. See the model hub to look for fine-tuned versions on a task that interests you.
Here is how to use this model:
>>> from transformers import AutoFeatureExtractor, RegNetForImageClassification
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("zuppif/regnet-y-040")
>>> model = RegNetForImageClassification.from_pretrained("zuppif/regnet-y-040")
>>> inputs = feature_extractor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
'tabby, tabby cat'
For more code examples, we refer to the documentation.